






 BTC/HKD+2.91%
BTC/HKD+2.91% ETH/HKD+5.48%
ETH/HKD+5.48% LTC/HKD+2.17%
LTC/HKD+2.17% DOT/HKD+6.22%
DOT/HKD+6.22% ADA/HKD+6.66%
ADA/HKD+6.66% SOL/HKD+4.68%
SOL/HKD+4.68% XRP/HKD+5.35%
XRP/HKD+5.35% DOGE/US+5.85%
DOGE/US+5.85%亮點
GPT-4可以接受圖像和文本輸入,而GPT-3.5只接受文本。GPT-4在各種專業和學術基準上的表現達到"人類水平"。例如,它通過了模擬的律師考試,分數約為應試者的前10%。OpenAI花了6個月的時間,利用從對抗性測試項目以及ChatGPT中獲得的經驗,反復調整GPT-4,結果在事實性、可引導性和可控制方面取得了"史上最佳結果"。在簡單的聊天中,GPT-3.5和GPT-4之間的區別可能微不足道,但是當任務的復雜性達到足夠的閾值時,區別就出來了,GPT-4比GPT-3.5更可靠,更有創造力,能夠處理更細微的指令。GPT-4能對相對復雜的圖像進行說明和解釋,比如說,從插入iPhone的圖片中識別出一個LightningCable適配器。圖像理解能力還沒有向所有OpenAI的客戶開發,OpenAI正在與合作伙伴BeMyEyes進行測試。OpenAI承認,GPT-4并不完美,仍然會對事實驗證的問題產生錯亂感,也會犯一些推理錯誤,偶爾過度自信。開源OpenAIEvals,用于創建和運行評估GPT-4等模型的基準,同時逐個樣本檢查其性能。官宣文檔
OpenAI已經正式推出GPT-4,這也是OpenAI在擴大深度學習方面的最新里程碑。GPT-4是大型的多模態模型,盡管GPT-4在許多現實世界的場景中能力不如人類,但它可以在各種專業和學術基準上,表現出近似人類水平的性能。例如:GPT-4通過了模擬的律師考試,分數約為全部應試者的前10%。而相比之下,GPT-3.5的分數大約是后10%。我們團隊花了6個月的時間,利用我對抗性測試項目以及基于ChatGPT的相關經驗,反復對GPT-4進行調整。結果是,GPT-4在事實性、可引導性和拒絕超范圍解答問題方面取得了有史以來最好的結果在過去兩年里,我們重構了整個深度學習堆棧,并與Azure合作,為工作負荷從頭開始,共同設計了一臺超級計算機。一年前,OpenAI訓練了GPT-3.5,作為整個系統的首次"試運行",具體來說,我們發現并修復了一些錯誤,并改進了之前的理論基礎。因此,我們的GPT-4訓練、運行空前穩定,成為我們首個訓練性能可以進行提前準確預測的大模型。隨著我們繼續專注于可靠擴展,中級目標是磨方法,以幫助OpenAI能夠持續提前預測未來,并且為未來做好準備,我們認為這一點,對安全至關重要。我們正在通過ChatGPT和API發布GPT-4的文本輸入功能,為了能夠更大范圍地提供圖像輸入功能,我們正在與合作伙伴緊密合作,以形成一個不錯的開端。我們計劃開源OpenAIEvals,也是我們自動評估AI模型性能的框架,任何人都可以提出我們模型中的不足之處,以幫助它的進一步的改進。能力
以太坊合并公共測試網 Kiln 已上線,預計將于本周全面過渡到 PoS:3月15日消息,以太坊基金會官方博客發文,宣布以太坊合并公共測試網 Kiln 已上線,預計將于本周(預計3 月 17 日之后)全面過渡到 PoS,旨在將客戶端實施階段轉至生產準備階段。此前的合并測試網 Kintsugi 將在未來幾周內被棄用。[2022/3/15 13:57:09]
在簡單閑聊時,也許不太好發現GPT-3.5和GPT-4之間的區別。但是,當任務的復雜性達到足夠的閾值時,它們的區別就出來了。具體來說,GPT-4比GPT-3.5更可靠,更有創造力,能夠處理更細微的指令。為了理解這兩個模型之間的差異,我們在各種不同的基準上進行了測試,包括模擬最開始那些為人類設計的考試。通過使用最新的公開測試還包括購買2022-2023年版的練習考試來進行,我們沒有為這類考試給模型做專門的培訓,當然,考試中存在很少的問題是模型在訓練過程中存在的,但我們認為下列結果是有代表性的。
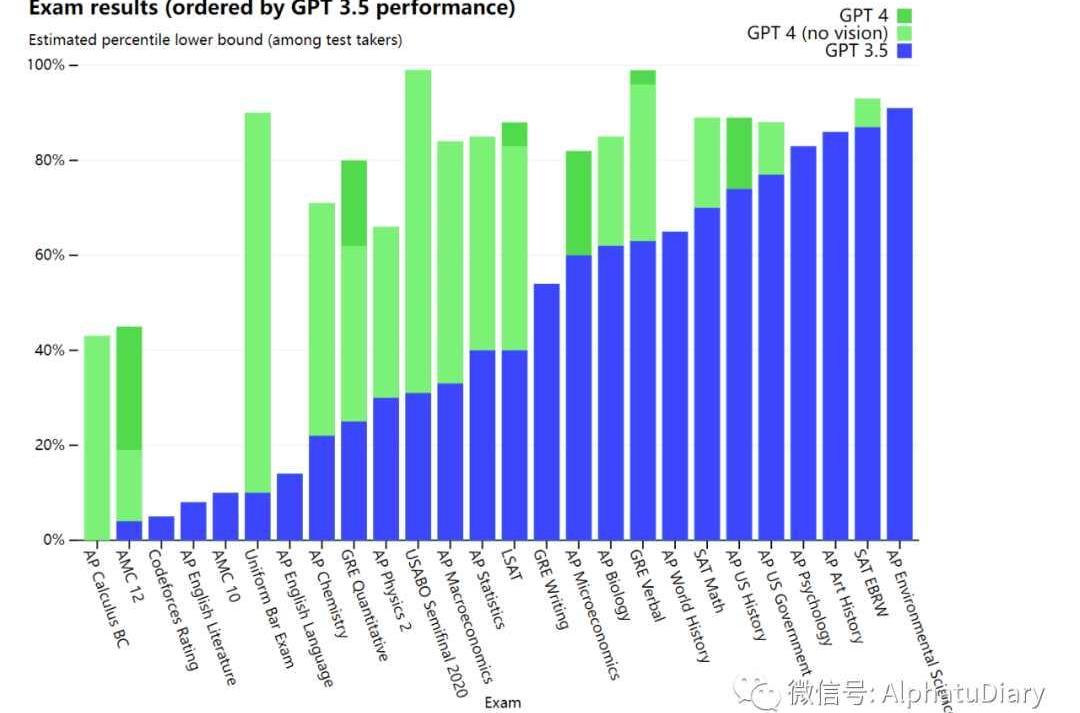
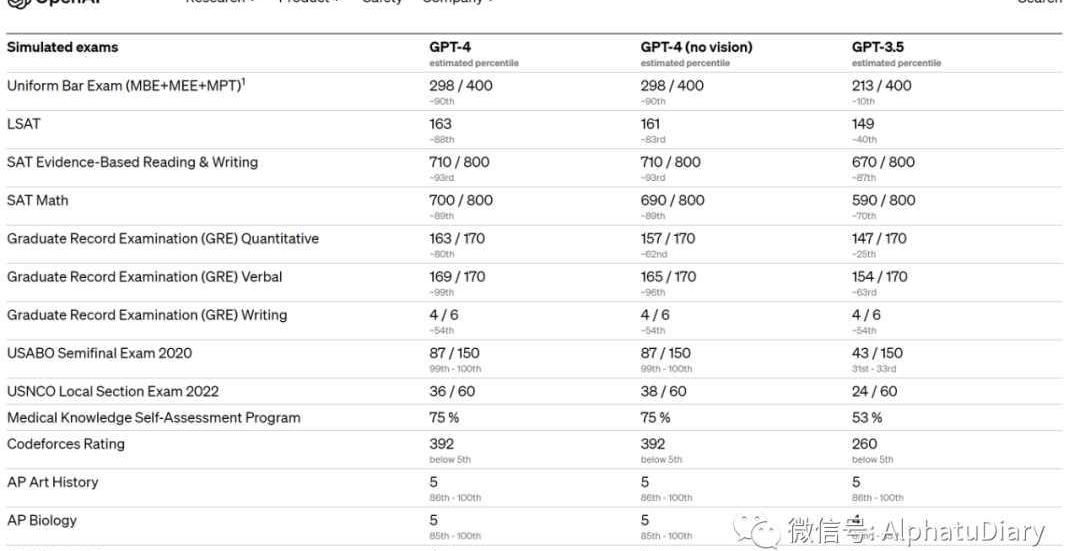
我們還在為機器學習模型設計的傳統基準上,對GPT-4進行了評估。GPT-4大大超過現有的大語言模型,與多數最先進的模型并駕齊驅,這些模型包括針對基準的制作或額外的訓練協議。
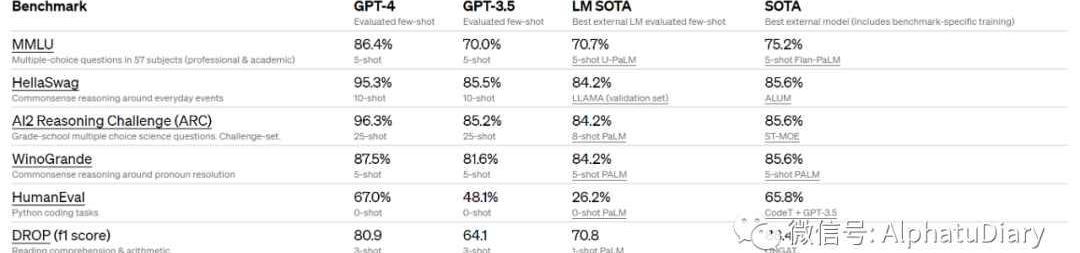
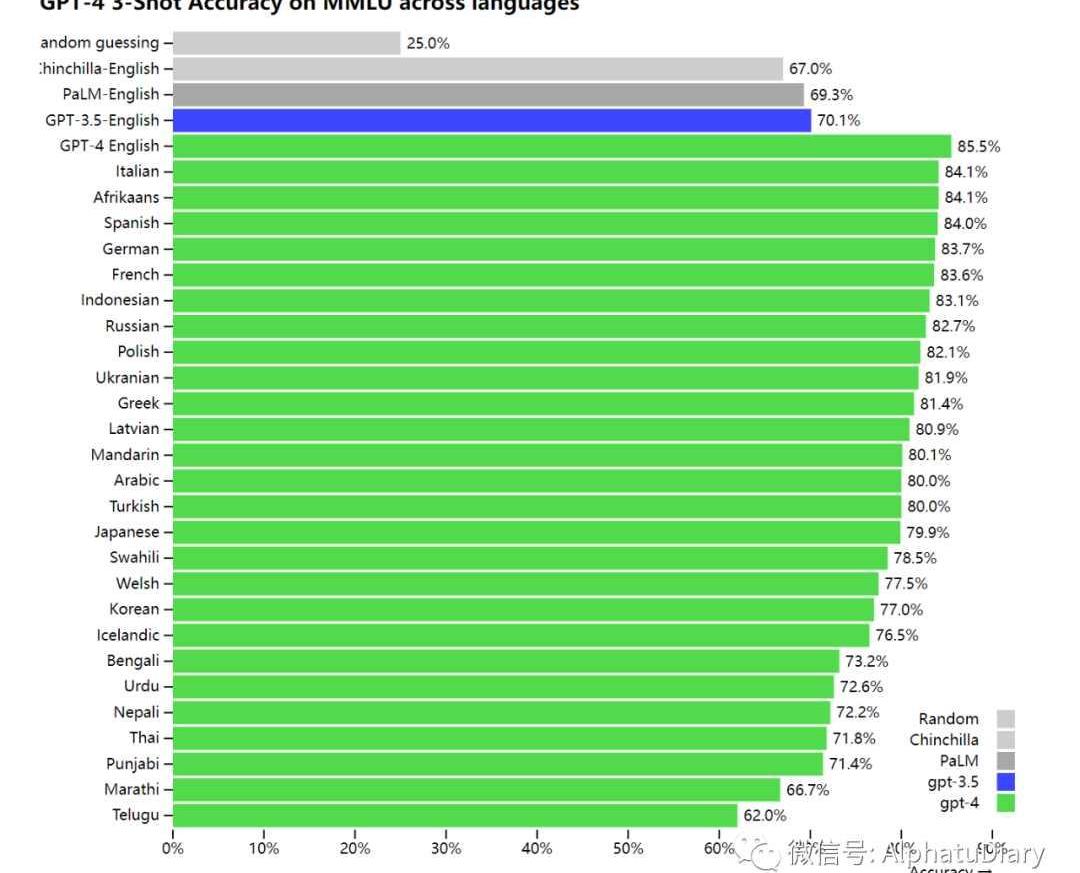
由于現有的大多數ML基準是用英語編寫的,為了初步了解其他語言的能力,我們使用AzureTranslate將MMLU基準:一套涵蓋57個主題的14000個選擇題,翻譯成了各種語言。在測試的26種語言中的24種語言中,GPT-4的表現優于GPT-3.5和其他大模型的英語表現,這種優秀表現還包括類似拉脫維亞語、威爾士語和斯瓦希里語等等。
Synthetix將全面整合Chainlink預言機以提供所有合成資產喂價:金色財經報道,經過幾個月的測試,DeFi交易所Synthetix今天宣布對其所有資產全面整合Chainlink價格預言機,包括其指數上所有合成資產的喂價。Synthetix此前在大宗商品和外匯Synths中實施了Chainlink價格預言機,但現在將從內部維護的預言機轉向Chainlink解決方案,從而進一步實現全面去中心化治理。(Decrypt)[2020/9/2]
我們一直在內部使用GPT-4,發現它對支持、銷售、內容審核和編程等功能會產生很大影響,我們還在用它來協助人類評估AI的輸出,這就是我們調整戰略的第二階段的開始。視覺輸入
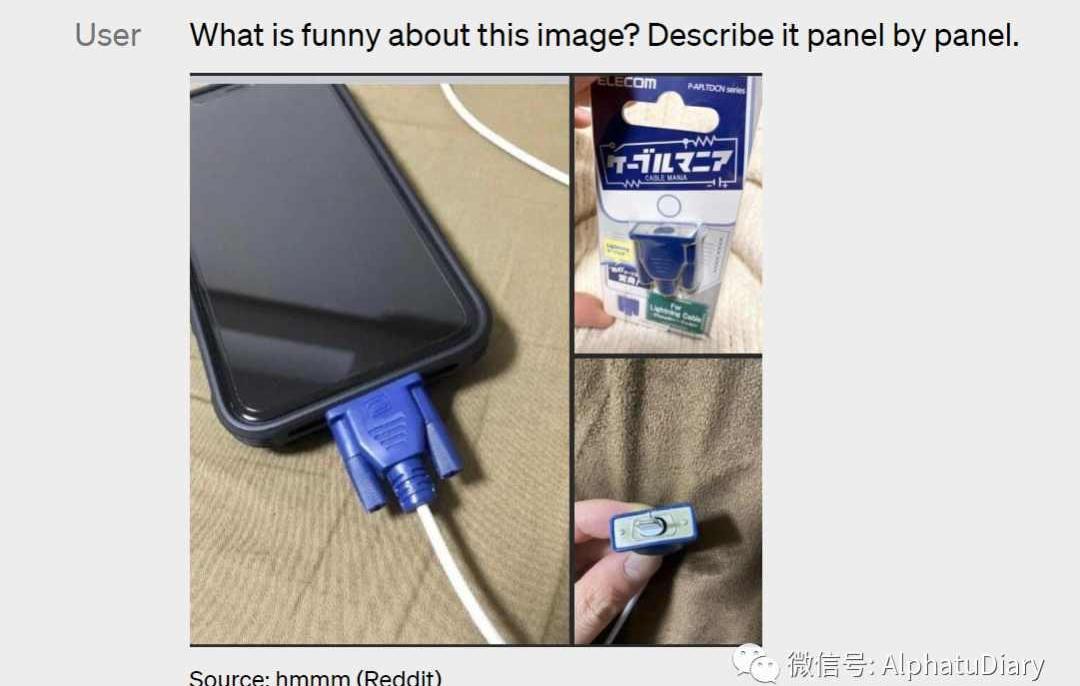
GPT-4可以接受文本和圖像的提示語,這與純文本設置平行。比如說,可以讓用戶指定任何視覺或語言任務,它可以生成文本輸出,給定的輸入包括帶有文字和照片的文件、圖表或屏幕截圖,GPT-4表現出與純文本輸入類似的能力。此外,還可以應用在為純文本語言模型開發的測試時間技術,包括少數幾個鏡頭和CoT的Prompting,不過目前圖像輸入仍然屬于研究方面預覽,沒有像C端公開產品。下列圖片顯示了一個"LightningCable"適配器的包裝,有三個面板。

動態 | 報告:區塊鏈等技術不斷成熟為全面提升港口服務提供了技術機遇:近日,中國港口高質量發展智庫研討會在北京舉行。會上中國經濟信息社與交通運輸部水運科學研究院聯合發布了中國港口高質量發展評價指標體系以及首份研究成果《中國港口高質量發展報告(海港篇)2019》,報告指出,互聯網、大數據、云計算和區塊鏈等技術不斷成熟,結合港口自身的海量貨物貿易數據共同為港口與經濟社會深度融合,全面提升港口服務提供了技術機遇。(中國水運網)[2019/9/6]
面板1:一個帶有VGA接口的智能手機插在其充電端口。面板2:"LightningCable"適配器的包裝上有一張VGA接口的圖片。面板3:VGA連接器的特寫,末端是一個小的Lightning連接器。這張圖片的搞笑性質來自于將一個大的、過時的VGA連接器插入一個小的、現代的智能手機充電端口..因此看起來很荒謬通過在一套狹窄的標準學術視覺基準上,對GPT-4的性能進行評估,并且對它進行預覽。然而,這些數字并不能代表其的能力范圍,因為我們發現,這個模型能夠處理很多的新的和令人興奮的任務,OpenAI計劃很快發布進一步的分析和評估數字,以及對測試時間技術效果的徹底調查結果。可控制的AI
我們一直在努力實現關于定義AI行為那篇文章中,所概述的計劃的每個方面,包括AI的可控制性。與經典的ChatGPT個性的固定言語、語氣和風格不同,開發者現在可以通過在"系統"消息中描述這些方向,來規定自己的AI的風格和任務。系統消息允許API用戶在范圍內,大幅對用戶體驗進行定制,我們將持續改進。局限性
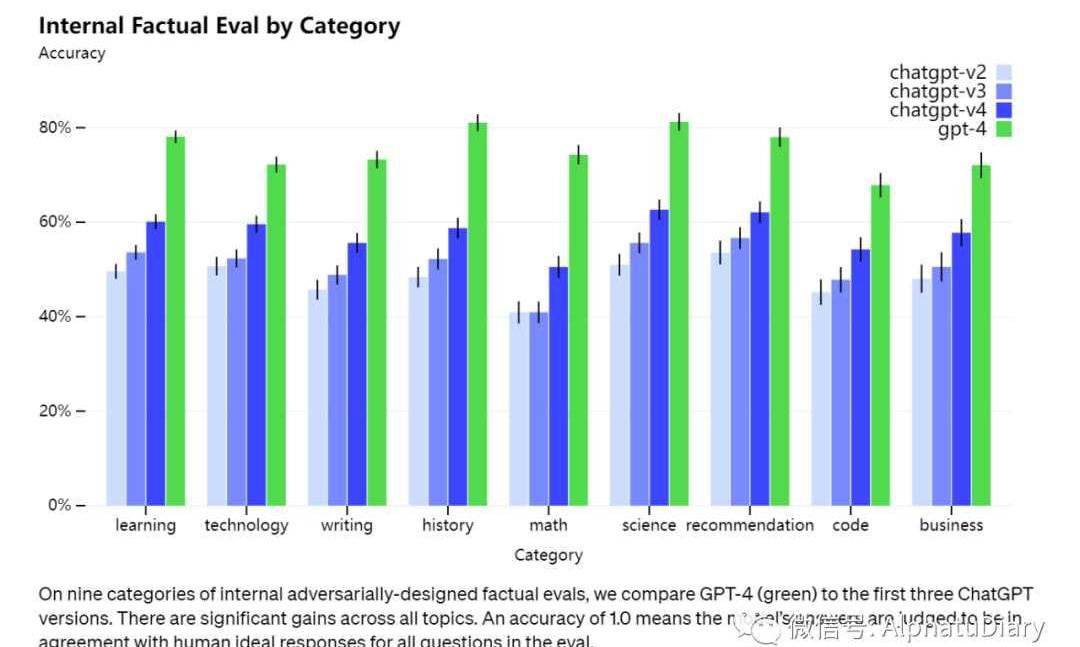
盡管能力驚人,不過,GPT-4仍存在與早期GPT模型類似的限制。最重要的是,它仍然不是完全可靠的。在使用語言模型的輸出時,特別是在高風險的情況下,應該非常小心謹慎,比如說:需要人類審查,完全避免高風險的使用)以及需要與特定的使用案例的需求相匹配。盡管各類情況仍然存在,但相較于以前的模型,GPT-4大大減少了hallucinations。在我們內部的對抗性事實性評估中,GPT-4的得分比我們最新推出的GPT-3.5高40%。
動態 | 否認闖入Cryptopia 表示正與Cryptopia展開全面合作:Cryptopia在推特分享最新調查進展。根據在官網發布的調查進度文件顯示,否認此前媒體的報道,表示未強行闖入Cryptopia,而Cryptopia正與調查小組展開全面合作。高科技犯罪部門的專家已進入案件調查,目前還未透漏涉及的加密貨幣總量,但金額巨大。將對案件進行技術分析調查,以及實地現場調查,結案時間仍未明確。表示將盡力為Cryptopia客戶追回損失的資金,然而也表示困難重重。[2019/1/17]
可控制的AI
GPT-4的基礎模型在這項任務中只比GPT-3.5略勝一籌;然而,在經過RLHF的后期訓練后,卻有很大差距。該模型在其輸出中會有各種偏差,我們在這些方面已經取得了進展,但仍有更多工作要做。根據我們最近的博文,我們的目標是使我們建立的人工智能系統具有合理的默認行為,以反映廣泛的用戶價值觀,允許這些系統在廣泛的范圍內被定制,并獲得公眾對這些范圍的意見。GPT-4通常缺乏對其絕大部分數據截止后發生的事件的了解,也不會從其經驗中學習。它有時會犯一些簡單的推理錯誤,這似乎與這么多領域的能力不相符,或者過于輕信用戶的明顯虛假陳述。有時它也會像人類一樣在困難的問題上失敗,例如在它產生的代碼中引入安全漏洞。GPT-4也可能在預測中自信地犯錯。風險和緩解措施
我們一直在對GPT-4進行迭代,使其從訓練開始就更加安全,保持一致性,我們所做的努力包括預訓練數據的選擇和過濾、評估,邀請專家參與,對模型安全改進、監測,以及執行。GPT-4與過去的模型會存在類似風險,如生產有害的建議、錯誤代碼或不準確的信息。然而,GPT-4的額外能力還導致了新的風險面。為了明確這些風險的具體情況,我們聘請了50多位來自人工智能對接風險、網絡安全、生物風險、信任和安全以及國際安全等領域的專家對該模型進行對抗性測試。他們的參與,使我們能夠測試模型在高風險領域的行為,這些領域需要專業知識來評估。來自這些領域專家的反饋和數據,為我們緩解和改進模型提供了依據。比如說,我們已經收集了額外的數據,以提高GPT-4拒絕有關如何合成危險化學品的請求的能力。GPT-4在RLHF訓練中加入了一個額外的安全獎勵信號,通過訓練模型來拒絕對此類內容的請求,從而減少有害產出。獎勵是由GPT-4的分類器提供的,它能夠判斷安全邊界和安全相關提示的完成方式。為了防止模型拒絕有效的請求,我們從不同的來源收集多樣化的數據集,并在允許和不允許的類別上應用安全獎勵信號。與GPT-3.5相比,我們的緩解措施大大改善了GPT-4的許多安全性能。與GPT-3.5相比,我們將模型對非法內容的請求的響應傾向,降低了82%,而GPT-4對敏感請求的響應符合我們的政策的頻率提高了29%總的來說,我們的模型級干預措施增加了誘發不良行為的難度,但仍然存在"越獄"的情況,以產生違反我們使用指南的內容。隨著人工智能系統的風險的增加,在這些干預措施中實現極高的可靠性將變得至關重要。目前重要的是,用部署時間的安全技術來補充這些限制,如想辦法監測。GPT-4和后續模型,很有可能對社會產生正面或者負面的影響,我們正在與外部研究人員合作,以改善我們對潛在影響的理解和評估,以及建立對未來系統中可能出現的危險能力的評估。我們將很快分享我們對GPT-4和其他人工智能系統的潛在社會和經濟影響的更多思考。訓練過程
金色財經獨家分析 全球多地對加密貨幣征稅,2018成加密貨幣征稅全面落地元年:澳洲《星島日報》近日刊文稱,澳洲稅務局(ATO)將進行逾36萬宗個人稅務審查,在新的報稅規例下,超過1萬澳元“比特幣”(Bitcoin)或其他虛擬貨幣交易,亦可能被稅務局審查。報稅時,比特幣被列作資產,投資者須繳資本增值稅。金色財經獨家分析,比特幣等加密貨幣在2017年底出現了爆發式增長,從無人問津變得炙手可熱,全球相關的加密貨幣交易所也如雨后春筍般出現在大眾視野,加入到加密貨幣領域的投資者也日益增加,不論從市值還是從交易量上,加密貨幣都逐漸從世界經濟的邊緣向中心逐步靠攏,擁有了一定的比重和地位。至此,原本野蠻生長的模式不能夠再繼續下去,高速增長的產業同時也引起了監管者的注意。全球多個國家和地區開始宣布對加密貨幣征稅,美國國稅局就在今年宣布加密貨幣交易與其他形式的財產一樣需要納稅;日本國稅廳也宣稱虛擬貨幣需要“報稅”;南非國家稅務局(SARS)發布的一份聲明顯示,雖然加密貨幣在該國不被認定為法定貨幣,但交易、投資加密貨幣,以及礦工仍需為此繳稅;以色列稅務部門將以20%到25%的稅率征收資本利得稅,而個人挖礦或商業交易加密貨幣必須增繳17%的增值稅;泰國對加密交易將征收7%的增值稅(VAT),以及15%的資本利得稅。這樣開來,全球范圍針對加密貨幣的稅收行動全面展開,2018將成加密貨幣征稅全面落地元年。[2018/4/9]
和之前的GPT模型一樣,GPT-4基礎模型的訓練是為了預測文檔中的下一個單詞,并使用公開的數據以及我們授權的數據進行訓練。這些數據是來自于極大規模的語料庫,包括數學問題的正確和錯誤的解決方案,弱的和強的推理,自相矛盾的和一致的聲明,以及種類繁多的意識形態和想法。因此,當被提示有一個問題時,基礎模型可以以各種各樣的方式作出反應,而這些反應可能與用戶的意圖相去甚遠。為了使其與用戶的意圖保持一致,我們使用人類反饋的強化學習對模型的行為進行微調。注意,模型的能力似乎主要來自于預訓練過程,RLHF并不能提高考試成績。但是對模型的引導來自于訓練后的過程--基礎模型需要及時的工程,甚至知道它應該回答問題。可預測的擴展
GPT-4項目的一大重點是建立一個可預測擴展的深度學習棧。主要原因是,對于像GPT-4這樣非常大的訓練運行,做大量的特定模型調整是不可行的。我們對基礎設施進行了開發和優化,在多種規模下都有非常可預測的行為。為了驗證這種可擴展性,我們提前準確地預測了GPT-4在我們內部代碼庫中的最終損失,方法是通過使用相同的方法訓練的模型進行推斷,但使用的計算量要少10000倍。我們認為,準確預測未來的機器學習能力是安全的一個重要部分,相對于其潛在的影響,它沒有得到足夠的重視。我們正在擴大我們的努力,開發一些方法,為社會提供更好的指導,讓人們了解對未來系統的期望,我們希望這成為該領域的一個共同目標。開放式人工智能評估
我們正在開源OpenAIEvals,這是我們的軟件框架,用于創建和運行評估GPT-4等模型的基準,同時逐個樣本檢查其性能。我們使用Evals來指導我們模型的開發,我們的用戶可以應用它來跟蹤不同模型版本和不斷發展的產品集成的性能。例如,Stripe已經使用Evals來補充他們的人工評估,以衡量他們的GPT驅動的文檔工具的準確性。因為代碼都是開源的,Evals支持編寫新的類來實現自定義的評估邏輯。然而,根據我們自己的經驗,許多基準都遵循一些"模板"中的一個,所以我們也包括了內部最有用的模板。一般來說,建立一個新的評估的最有效方法是將這些模板中的一個實例化,并提供數據。我們很高興看到其他人能用這些模板和Evals更廣泛地建立什么。我們希望Evals成為一個分享和眾包基準的工具,最大限度地代表廣泛的故障模式和困難任務。作為后續的例子,我們已經創建了一個邏輯謎題評估,其中包含GPT-4失敗的十個提示。Evals也與實現現有的基準兼容;我們已經包括了幾個實現學術基準的筆記本和一些整合CoQA的變化作為例子。我們邀請大家使用Evals來測試我們的模型,并提交最有趣的例子。我們相信Evals將成為使用和建立在我們的模型之上的過程中不可或缺的一部分,我們歡迎直接貢獻、問題和反饋。ChatGPTPlus
ChatGPTPlus用戶將在chat.openai.com上獲得有使用上限的GPT-4權限。我們將根據實際需求和系統性能調整確切的使用上限,但我們預計容量將受到嚴重限制。根據我們看到的流量模式,我們可能會為更高的GPT-4使用量引入一個新的訂閱級別,我們也希望在某個時候提供一定數量的免費GPT-4查詢,這樣那些沒有訂閱的用戶也可以嘗試。API
要獲得GPT-4的API,請可以去OpenAI的官方Waitlist上注冊。結論
我們期待著GPT-4成為一個有價值的工具,通過為許多應用提供動力來改善人們的生活。還有很多工作要做,我們期待著通過社區的集體努力,在這個模型的基礎上進行建設、探索和貢獻,共同對模型進行改進。參考文獻:1.https://openai.com/research/gpt-42.https://techcrunch.com/2023/03/14/openai-releases-gpt-4-ai-that-it-claims-is-state-of-the-art/3.https://www.theverge.com/2023/3/14/23638033/openai-gpt-4-chatgpt-multimodal-deep-learning
Tags:GPTNAIPENOPENgpt幣價格Monopoly Millionaire GameOpen PlatformOPENAIERC
上周我們盤點了8個即將首發上線的項目,有些項目表現亮眼。比如,HALO在BitgetIEO價格為0.02美元,上線后一度飆升至1.5美元,目前穩定在0.3美元,較IEO價上漲1500%.
1900/1/1 0:00:00去年以來ZK賽道受到了大家的廣泛關注,特別是采用ZK-EVM技術的Starknet、zkSync、PolygonEVM、Scroll等明星項目成為大家談論最多的話題.
1900/1/1 0:00:00隨著埃隆-馬斯克最近接管了Twitter,關于從大型社交網絡遷移到獨立或開放的替代方案的討論已經越來越多,但是所有那些剛開始幻想在加入繁榮的Twitter前居民社區的人.
1900/1/1 0:00:00對于剛進入Web3領域的用戶來說,創建錢包或許是他們遇到的第一層障礙。傳統的12位助記詞對于新人用戶來說過于繁瑣和危險,作為備份和恢復功能也過于復雜,可說是毫無用戶體驗優勢.
1900/1/1 0:00:00本文來自Bankless,由Odaily星球日報譯者Katie辜編譯。 隨著ARB空投在即,人們開始對Arbitrum生態系統密切關注.
1900/1/1 0:00:00最近幾周,加密市場涌現出一批新項目,投資者參與熱情高漲。Odaily星球日報精選整理了三月即將首發上線的8個項目以供參考,涉及AI、DEX、鏈游、NFT等不同細分賽道.
1900/1/1 0:00:00


