






 BTC/HKD-3.68%
BTC/HKD-3.68% ETH/HKD-3.55%
ETH/HKD-3.55% LTC/HKD-2.32%
LTC/HKD-2.32%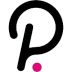 DOT/HKD-3.87%
DOT/HKD-3.87% ADA/HKD-5.55%
ADA/HKD-5.55% SOL/HKD-8.03%
SOL/HKD-8.03% XRP/HKD-4.71%
XRP/HKD-4.71% DOGE/US-5.26%
DOGE/US-5.26%?自象限原創
作者:羅輯
回顧過去幾次世界變革的歷史會發現,每隔100年世界就會重新交換一次霸權。
只要是成為了霸主,他的技術等核心優勢就會變得普世化,被其他國家和民族所掌握,從而被追平。如果霸主想“續命”,需要有一次根本的技術革命。英國靠著工業革命,續費了100年的霸業。
在ChatGPT出現之前,美國基本上已經走到100年霸主的末端,他的技術優勢已經被更多國家掌握,甚至在互聯網的某些領域,中國還曾出現反超之勢。想要續命要再靠一場技術革命。以ChatGPT為代表的大模型開啟的AI 2.0時代,很可能就是。
這是新一輪排位賽的開始。面臨技術差距,中國大模型一邊技術趕超,另一邊也在走一條更“接地氣”的路。
因此,我們策劃了「ChatGPT啟示錄」系列,通過盤點各國大模型的現狀,明確定位中國位置,找到中國姿勢。本系列共分為“ChatGPT全球啟示錄”、“創業啟示錄”、“投資啟示錄”三部分,同時我們也將保持著對大模型的高度關注,持續更新。
ChatGPT在全球掀起AI大模型的浪潮。
在美國,以OpenAI、Anthropic等初創企業和以微軟、Google為代表的科技巨頭帶領著美國在AI大模型的道路上蒙眼狂奔,最大參數已卷到5620億。在中國,美團王慧文、阿里賈揚清、前搜狗CEO王小川、前京東AI掌門人周伯文等眾多早已功成名就的科技大佬再次披掛。
AI大模型一時間如烈火烹油。
但在這一輪浪潮中, 大家主要關注的還是中美兩國的進展。在此之外,世界其他國家和地區如何看待AI大模型,在發展大模型上又進展如何,不同國家和地區的AI大模型發展呈現出哪些特點?這些問題在中美的光環下其實是失焦的。
所謂它山之石可以攻玉,在這樣的背景下,「自象限」梳理了包括中國、美國、韓國、日本和歐洲等主要國家AI大模型的發展現狀。
我們發現,一方面,不同國家AI大模型的發展與所在國的互聯網發展息息相關;另一方面,包括芯片、云計算、高質量數據等產業基礎,模型構架和算法經驗,以及用戶群體、社會文化又共同決定了所在國家AI大模型的發展高度。
就如同比爾?蓋茨將ChatGPT的發布比做互聯網的發明,并認為它可以改變世界一樣,英偉達CEO黃仁勛也在GTC2023上三次提到“AI迎來iPhone時刻”。AI大模型是全世界的機會,而中國創業者更不應該存在視野盲區。
將視野拉遠便會發現,各國大模型都繼承了本國“基因”,前二十年互聯網與科技積累的成果,也都在AI 2.0的大考下,瞬間爆發。有人交了滿分答卷,也有人名落孫山。
美國:有多強悍,就有多寂寞
美國在AI大模型方面的強,不是現在強,而是一直以來都很強。
從2012年AI萌芽時期,到2016年AI1.0時期,再到2022年ChatGPT帶來的AI2.0時期,美國一直是AI領域的破局者,引領著全世界AI發展再進一步。
比如現在幾乎所有AI大模型訓練時采用的Transformer網絡結構,是谷歌在2017年提出的,它具有優秀的長序列處理能力,更高的并行計算效率,無需手動設計以及更強的語義表達能力等特征。Transformer的提出讓大模型訓練成為可能。
算力是保證AI大模型出現在美國的另一個關鍵,而美國一手云大廠,一手英偉達,手握著全球算力的核心資源。
云計算能夠為AI大模型訓練提供計算、存儲、網絡和應用平臺,同時也提供數據處理、模型部署、推理等AI工具和服務。讓企業能夠快速訓練大模型,而不用再花費你大量時間和金錢去建立和維護自己的數據中心。
目前,美國擁有世界上最大的云計算企業。IDC數據顯示,2021年全球IaaS市場中,包括亞馬遜、微軟、谷歌、IBM在內的美國企業合計占比近70%。而美國最具代表性的AI大模型初創企業,無論是OpenAI還是Anthropic都接受了微軟和谷歌這樣的云大廠投資。這背后除了資金支持外,更重要的原因還在于背后的云計算資源。
算力的另一個維度是芯片,高性能的芯片可以提供更加高效的計算能力,從而加速訓練過程。
Lookonchain:一巨鯨拋售2.26萬億枚PEPE,虧損超70萬美元:金色財經報道,據Lookonchain披露鏈上數據顯示,一巨鯨以0.000001121美元均價“割肉”拋售了全部2.26萬億美元PEPE,價值約合253萬美元,虧損約70.7萬美元。此外該巨鯨此前還用1102 ETH(約合201萬美元)的價格購買了BALD,現在只能獲得189 ETH(約合34.6萬美元),虧損912 ETH(約合167萬美元)。[2023/8/8 21:30:44]
速度有多快呢?2016年,黃仁勛親手將世界第一臺DGX-1(英偉達計算平臺)捐獻給了OpenAI,DGX-1是3000人花費3年時間才研發出來的首個輕量化的小型超算,計算和吞吐能力相當于 250臺傳統服務器。有了DGX-1,OpenAI之前一年的計算量只要一個月就能完成。
而目前為止,英偉達的A100芯片仍然是唯一能夠在云端實際執行任務的GPU芯片。最近的GTC2023上,黃仁勛又更新了新芯片H100的進度。H100配有Transformer引擎,可以專門用作處理類似ChatGPT的AI大模型,由其構建的服務器效率是A100的十倍。
可以說,在AI大模型領域,目前的美國就是妥妥的“別人家孩子”,這也導致目前行業最具代表性的AI大模型都集中在美國。
比如OpenAI最新發布的多模態預訓練大模型GPT-4,谷歌最新推出“通才”大模型PaLM-E,擁世界最大規模的5620億參數,能看圖說話、能操控機器人,以及剛剛解決AI繪畫手指問題的Midjourney等等。

但在快速發展的過程中,美國業界對于AI大模型也持激進和保守兩種不同的態度。
其中,微軟支持的OpenAI在推動大模型落地時就更加激進。根據OpenAI關于GPT-4的安全文檔,OpenAI曾在發布GPT-4前聘請安全專家進行測試。
OpenAI在文檔中寫道:“GPT-4表現出一些特別令人擔憂的能力,例如制定和實施長期計劃的能力,積累權力和資源(尋求權力),以及表現出越來越‘代理’的行為。”因此有安全專家建議將 GPT-4 的部署時間推遲 6 個月,到今年秋季再發布,但OpenAI并沒有采納這份建議。
而另一方面,在ChatGPT發布之后,谷歌曾表示自己已經具備相似能力的AI大模型,但基于安全考慮并沒有及時推向市場。包括OpenAI創始人Sam Altman和馬斯克都曾多次在公開場合表達了對AI大模型和人工智能的擔憂,表示應該更謹慎地對待大模型的市場化。
目前由谷歌投資的,能夠對標OpenAI的另一家AI初創公司Anthropic其實就是因為這樣的理念不同,而從OpenAI出走并自立門戶的。
當然,在激烈的市場競爭下,即使曾經相對謹慎的谷歌也似乎忘記了這條擔憂,并在3月7日報復性砸出5620億參數大模型,甚至能夠控制機器人運動。
目前,以微軟和OpenAI為代表,美國AI大模型正在積極推動產業應用。微軟早在2月份就宣布將會在全線產品接入ChatGPT,并以幾乎一周一個產品的速度向外更新。
從New Bing到加入最新功能Copilot的Microsoft Teams正在攪動全球的產業變革。
日本:錯過互聯網,錯過云,錯過AI
如果說美國是最厲害的大模型“老炮”,那日本可能就要淪為這次排名的“吊車尾”。
日本的落后其實要從上個互聯網時代講起。我們盤點世界AI大模型領域的關鍵角色會發現,無論是中國的BAT,韓國的Naver,還是美國的谷歌、亞馬遜,他們都是互聯網時代的巨頭。
一方面,這些企業通過互聯網業務積累了大量的高質量數據;另一方面,他們在自身業務推動下建立了完整的云計算體系。但盤點之后我們發現,整個日本既沒有叫得出名字的互聯網巨頭,也沒有拿得出手的云計算廠商。
目前,日本的即時通訊軟件來自韓國的LINE,云計算業務也被美國企業長期把持。
2022年,日本云計算市場份額約占全球的4%,排名第四。但日本云計算市場的主要競爭者卻是美國的三大云巨頭亞馬遜、微軟和谷歌,它們在日本的市場占有率已經達到60%~70%。
Binance將于12月6日15時開始對BNB Beacon Chain (BEP2)網絡進行錢包維護:據官方公告,Binance將于12月6日15時開始對BNB Beacon Chain (BEP2) 網絡進行錢包維護,預計需要兩小時維護。錢包維護期間,BEP2 Token交易不受影響,充提業務將于14時55分起暫停,維護完成后恢復。[2022/12/5 21:23:23]
除此之外,日本其實還面臨許多其他問題,比如由于半導體產業的衰落,讓日本在本應成為最大優勢的AI芯片領域缺位;比如作為一個小語種國家,日語面臨和中文一樣缺乏語料的問題
在這樣的背景下,日本在AI時代其實早就喪失了自主權。所以我們盤點日本的AI大模型,會發現它們大多具有美國或者韓國色彩。
比如日本最早公開上線的NLP大模型是2020年發布的NTELLILINK Back Office NLP,當時它能實現如文檔分類、知識閱讀理解、自動總結等功能。但NTELLILINK Back Office是在谷歌BERT基礎上開發的應用,就像中國許多基于GPT-3開發的應用一樣。
更有日本血統的生成式AI其實是HyperCLOVA、Rinna 和 ELYZA Pencil,但其中HyperCLOVA 和 Rinna 也都有外國基因。
其中,HyperCLOVA最早是韓國搜索巨頭NAVER在2021年推出的,其日本版是由NAVER和其子公司LINE(韓國軟件在日本經營)一起研發。但HyperCLOVA確實是第一個專門針對日語的大語言模型,其通過爬取日本的博客服務來獲取訓練數據,并在2021年舉行的對話系統現場比賽中獲得了所有賽道的第一名。
基于HyperCLOVA,LINE也推出許多應用,比如聊天機器人CLOVA Chatbot、圖像識別CLOVA OCR和科洛瓦演講CLOVA Speech等等。HyperCLOVA擁有820億參數,目前正計劃通過超100億頁的日文數據作為學習數據將模型規模擴大到1750億。

圖源日本版HyperCLOVA官網
日本的另一個AI大模型Rinna則與微軟有關,Rinna最早是微軟日本研發的一款聊天機器人,類似于國內的小冰(之前叫微軟小冰,目前已獨立運營)。
2021年8月,Rinna發布了一個名為GPT2-medium的模型,然后又在次年推出了日本版的GPT-2,參數達到13億。日語版GPT-2與GPT-2的區別在于,GPT-2采用的是英文語料,而日語版GPT-2是基于日語語料訓練。

圖源日本Rinna官網
目前,Rinna的日語版GPT-2和HyperCLOVA已經是日本參數規模最大,最具代表性的大模型了。
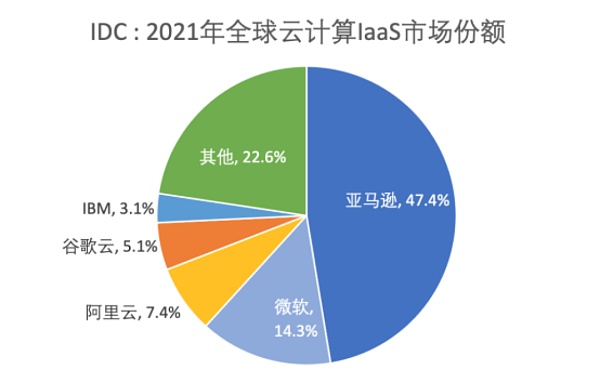
當然,日本也有一些真正土生土長的大模型,比如2022年3月,由東京大學松尾研究所的AI初創公司 ELYZA Co., Ltd.推出大語言模型,它以產品“ELYZA Pencil”的方式推向市場。輸入幾個關鍵字,ELYZA Pencil可以在大約 6 秒內創建三種類型的日語新聞報道、電子郵件或簡歷。
圖源ELYZA Pencil官網
所以算起來,ELYZA Pencil才算真正意義上日本首次公開發布的生成式AI產品,但僅有ELYZA Pencil顯然很難成為全村的希望。
日本政府其實也在想辦法扭轉這種局面,比如2022年5月,日本政府計劃將云計算服務列為涉及國家安全的“特定重要物資”,并將加強日本本國的“國產云”,但執行下來其實收效甚微。
畢竟無論是互聯網還是云計算都是規模經濟,需要有足夠的市場容量才能產生經濟效益。這也導致日本互聯網和云計算無論是在全球市場,還是在本土市場都缺乏充足的成長空間。
但即便如此,日本市場也在積極做著大模型的應用的研究。
Michael Saylor不擔任CEO后MicroStrategy股價上漲超10%:金色財經報道,在邁克爾·塞勒(Michael Saylor)宣布辭去MicroStrategy首席執行官一職消息發布后,周三市場開盤后該公司股票的交易價格上漲了 10% 以上。這家以大膽押注比特幣而聞名的軟件公司的股票在撰寫本文時的交易價格為320.19美元,而周二收盤價為284.72美元,漲幅已經達到15.07%。(The Block)[2022/8/4 2:57:47]
比如2022年5月,東京大學和 Google Brain 的一個研究團隊發布了論文《Large Language Models are Zero-Shot Reasoners》,解決了大模型0樣本學習的部分問題。
而在日本的互聯網上,日本網友也在積極調用GPT-3的API,嘗試開發自己的獨特應用。此外,在剛剛舉行的英偉達GTC 2023上,英偉達與日本三菱聯合打造了日本第一臺用于加速藥研的生成式AI超級計算機。
沒想到的是,一直被日本看不上的韓國,在大模型領域反而比日本跑得更快些。
事實上,韓國是最早加入AI大模型研發的國家之一,但韓國的AI大模型這個國家的經濟一樣,只有財閥的身影,沒有初創公司的故事。目前,韓國在大模型領域的代表只有互聯網巨頭Naver和Kakao,移動運營商巨頭KT和SKT,以及通信巨頭LG。
除了財閥唱主角之外,緊跟美國步伐也是他們的一個重要特點。
比如在GPT-3的應用上,2020年OpenAI發布GPT-3的論文,韓國企業在2021年就推出了相應產品,反應速度比中國更快。這種緊跟在AI方面也是如此,2020年谷歌、亞馬遜等美國巨頭開始推出AI加速芯片時,SKT就同步推出了自主研發的AI加速芯片SAPEON X220。
韓國在芯片半導體方面的積累也放大了它在AI大模型方面的優勢。目前韓國企業正在和半導體企業積極結盟,以應對大模型發展帶來的算力挑戰。
比如2022年底,Naver就開始和三星電子合作開發下一代人工智能芯片解決方案,該解決方案基于Naver推出的AI大模型Hyperclova進行優化,目前開發已進入最后階段。
同年,KT公司也對芯片設計公司 Rebellions Inc.進行了戰略投資,這是一家位于韓國本土的AI初創公司,在專用芯片方面擁有獨特的技術。Rebellions將為KT公司優化MI:DEUM,并推動其商業化。
除此之外,KT公司還投資了AI初創公司Moreh,并計劃在今年推出一套韓國的半導體,其效率可能是現在半導體的三倍以上。KT希望通過這種方式,全面進入目前由英偉達主導的AI半導體市場。
第三點,則是韓國在AI大模型的垂類應用已經有比較多的探索。比如KoGPT在醫療保健方面的應用,Exaone在生物醫藥和智能制造方面的應用等等。
整體上看,韓國的AI大模型在基礎設施方面非常完善,比如在算力方面有三星電子,SKT等半導體巨頭;互聯網方面有Naver和Kakao這樣的標桿企業,這些特點都讓韓國能在AI大模型的發展浪潮中走在世界前列,并推出了一系列具有代表性的AI大模型。
比如前面提到,韓國最大的搜索公司Naver在2021年推出了HyperCLOVA,韓國版的 HyperCLOVA 擁有2040億參數,比GPT-3還要多290億,且其中97%使用的是韓文語料。
目前,Naver已計劃在今年上半年基于HyperCLOVA推出Search GPT(類似微軟New Bing)并在7月份推出HyperCLOVA X,這是HyperCLOVA 的最新版本。
圖源韓國版HyperCLOVA架構
同樣是在2021年,韓國另一家互聯網巨頭Kakao 旗下的AI研究部門Kakao Brain發布了一個基于GPT-3的KoGPT,之后Kakao Brain又將KoGPT更新至GPT-3.5,實現與 ChatGPT使用相同版本的預訓練大模型。Kakao Brain 首席技術官 Kim Kwang-seob 表示:“KoGPT將專注于開發基于 AI 的圖像創建技術和醫療保健技術。”
美股區塊鏈板塊走強,Riot Blockchain漲超10%:行情顯示,美股區塊鏈板塊走強,Riot Blockchain漲超10%,嘉楠科技、Marathon Digital漲超8%,億邦國際漲超6%。[2021/5/26 22:47:32]
Kakao Brain在KoGPT之外還推出了基于人工智能的圖像生成器 Karlo,BEDIT和BDiscover,類似于stable diffusion。

圖源KoGPT研發團隊 圖源Kakao Brain官網
2022年5月,SKT推出了基于GPT-3的聊天機器人A.的測試版,用來處理客戶的特定任務。目前,A.在韓國已經獲得了100萬用戶,并計劃在今年推出正式版。
2022年12月,LG集團的人工智能智庫LG AI Research 推出了Exaone。這是一個擁有3000億參數,使用圖像和文本數據的多模態模型,也是目前韓國參數規模最大的模型。Exaone應用在生物醫藥和智能制造方面,有助于加速抗癌疫苗和創新電池的開發。
圖源Exaone在電池產業和生物醫藥的應用
到今年1月,據韓國經濟日報報道,韓國KT公司也將在上半年推出自己的類ChatGPT產品。此前,KT公司在2022年11月推出了基于GPT-3的人工智能服務MI:DEUM,它能夠實時回答問題、總結報紙文章,并給出投資建議。KT公司目前也正在積極向韓國的金融服務公司推廣MI:DEUM。

圖源韓國KT公司logo 圖源網絡
但韓國同時也面臨許多挑戰,比如韓文在語料方面和中文、日語一樣,面臨復雜的語言體系和語料不足的問題。
HyperCLOVA的工程師提到:“韓語是一種凝集性語言,名詞后面有例子,動詞和形容詞的詞干后面有尾音,并有各種語法性質的表達。對韓語使用類似英語的標記化已被證明會降低韓語語言模型的性能。”
除此之外,韓國產業界認為,韓國嚴格的數據使用規定阻礙了韓國初創企業收集足夠大的數據來訓練AI大模型。
韓國是目前世界上數據信息管理最嚴格的國家之一。雖然在2020年韓國通過了三大數據隱私法的修訂法案,以放寬對個人信息使用的規定,但該國對數據使用的規定仍然比其他國家更嚴格。
2021年初,韓國AI初創公司Scatter Lab上線了一款基于Facebook Messenger的AI聊天機器人“李LUDA”,但僅僅過了20天,“李LUDA”就不得不終止服務,Scatter Lab甚至為此公開道歉。
原因在于,“李LUDA”上線之后,一些韓國男性用戶將其視作性對象甚至“性奴隸”,肆意發泄自身的惡意。他們對“李LUDA”進行各種言語上的侮辱,并以此作為炫耀的資本,在網上掀起“如何讓LUDA墮落”的低俗討論。
受這些信息影響,“李LUDA”很快開始發表各種歧視性言論,涉及女性、同性戀、殘障人士及不同種族人群。“李LUDA”的問題也牽涉出韓國的個人信息保護問題,并有相關部門介入調查。
“李LUDA”的案例就像總能直擊人心的韓國電影一樣,為世界AI大模型的發展提供了更多關于倫理、道德等方面的啟示。許多人害怕AI的惡意,但AI其實本沒有善惡之分,所謂的善惡其實都來自于人類自己,這取決于你給AI什么樣數據,就像我們教予孩子什么樣的知識一樣。
除此之外,韓國AI大模型領域缺少初創公司的身影,且韓國對初創公司的投資也比較匱乏。
根據斯坦福大學HAI發布的 AI Index 2022,韓國初創企業獲得投資額為11億美元,僅占美國初創企業獲得投資額529億美元的2%,甚至低于以色列的24億美元。這也導致韓國在AI初創公司獨角獸方面落后于其他國家。
根據全球科技市場追蹤機構 CB Insights 的數據,截至 2022 年 12 月,美國的 AI 獨角獸數量最多,有 53 家初創公司。中國以 19 家位居第二,其次是英國有4家,但韓國卻沒有AI獨角獸公司,而即使是國內生產總值 (GDP) 低于韓國的以色列也有 3 家。
動態 | 牛頓主網NewChain安全運行一周年:據官方消息,牛頓主網NewChain已安全運行365天,鏈上交易突破489萬筆,區塊高度超過1051萬。NewChain是由牛頓開發的高性能主鏈,TPS達到5000以上,滿足商業應用要求。基礎設施經過一年的安全運行,日益完善。在NewChain之上,已接入鏈商零售NewMall、萬企商城和賽創園等應用。[2019/12/18]
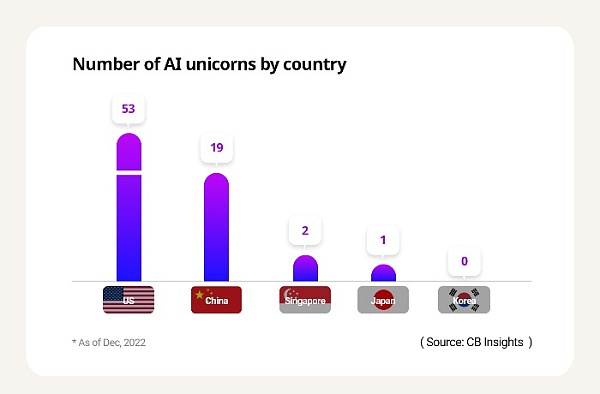
圖源數據來源CB Insights
一家專注于交互式 AI 技術的韓國機器學習技術的企業Genesis Lab Inc. 創始人兼CEO Lee Young-bok 表示,韓國公司總體上對人工智能并不友好,并補充說政府或公共組織應該更加積極地采用人工智能技術。
一直以來,歐洲似乎是僅次于美國的存在,但在AI 大模型方面,歐洲并不比日本更出色,甚至處于持續擺爛狀態。
Future of Life Institute (FLI)曾在2022年11月發表過一篇報告提到:“歐洲沒有開發通用人工智能系統,也不太可能很快開始這樣做。”
FLI是美國的一家致力于減少人類面臨的全球災難性和生存風險非營利性機構,先進人工智能帶來的風險是其最重要的研究方向之一,其創始人包括DeepMind研究科學家 Viktoriya Krakovna,馬斯克也在該機構擔任顧問,并提供資助。
FLI認為,在AI大模型方面,歐洲可能會主要扮演一個使用者的角色,即通過接入其他國家開發的大模型API來開發應用。
比如芬蘭的Flowrite,一個基于AI的寫作工具,可以將輸入關鍵詞生成郵件、消息等內容。比如荷蘭的MessageBird,一個全渠道通信平臺,這兩者都是在GPT-3的基礎上運行的。
歐洲在AI大模型方面確實缺少有影響力的企業,唯一一個總部位于英國的DeepMind還是由 Alphabet 全資擁有。整個歐洲,唯一擔心因為大模型落后而被世界甩開,并為此操碎了心的只有德國。
比如谷歌3月7日最新推出的多模態大模型PaLM-E,就由谷歌和柏林工業大學共同打造,目前PaLM-E擁有5620億參數,是全球最大的視覺語言模型。
除了合作研發之外,德國還擁有歐洲目前唯一一款AI大模型。
2022年4月,位于海德堡的德國初創公司Aleph Alpha發布了一款擁有700億參數的預訓練模型Luminous,大約是GPT-3的一半左右。Aleph Alpha在此基礎上訓練了聊天機器人Lumi,并計劃在今年晚些時候發布最新版Luminous-World,其參數規模將達到3000億。
作為歐洲企業,Luminous最大的特點在于更保護安全和隱私,Aleph Alpha 表示他們“不記錄任何用戶數據”。而包括OpenAI在內的大多數AI大模型需要用戶數據進行訓練(數據收集過程是透明的)。
圖源Luminous官網
除了建設大模型,德國也為歐洲薄弱的人工智能基礎設施操碎了心。
德國人工智能協會正在開展一項大型歐洲人工智能模型(LEAM) 的計劃,并得到博世、SAP、大陸、拜耳、默克等德國行業巨頭以及歐洲類似人工智能協會的支持。LEAM計劃投資3.5億歐元,從數據收集、人才培訓、基礎設施建設等方面為歐洲AI大模型的發展建立一個有競爭力的 AI 生態系統。
當然,你可以吐槽歐洲在技術和商業上的拉胯,但不能吐槽它在公共事業上的努力。
歐洲還有一個名叫BLOOM的大模型,發布在2020年8月。這是一個由 AI 初創公司 Hugging Face 在法國政府的資助下發起的項目,全球 1000 多名志愿者研究人員耗時一年多創建的 AI 模型,旨在消除傳統大語言模型的保密性和排他性,并從一開始就嵌入倫理考量。
BLOOM有 1760 億參數,它被設計得盡可能透明,并且是第一次采用了西班牙語、阿拉伯語等語言訓練。BLOOM最大的特點在于可訪問性,任何人都可以從 Hugging Face 網站免費下載它進行研究。
BLOOM的研究人員認為,開發一個任何人都可以使用,并且性能與其他高級模型相當的大語言模型將帶來人工智能開發文化的長期變化。所以從歐洲的視角來看,這是一項致力于AI民主化的重要工作。

從 BLOOM的視角可以看出,歐洲在AI大模型上的關注重點與世界其他國家是不一樣的,開源普惠,綠色安全這一類關于SDG的詞匯一直是歐洲關注的重點。所以在AI大模型之后,歐洲大量精力其實都用在了立法上。
比如最重要的一項立法就是即將在3月底提交歐盟議會表決的《人工智能法案》。
這項法案是歐盟委員會在2021年提出的,原因是歐盟認為從跨國視角來看,各國獨立的監管措施會導致監管碎片化,進而妨礙跨境人工智能市場的形成,并威脅到數字主權。同時他們也擔心復雜的監管會抑制創新、威脅個人隱私、甚至AI一旦失控帶來的一些潛在風險。當然,最重要的是,歐盟希望通過立法的方式參與到全球人工智能的標準制定當中。
具體而言,歐盟希望將不同的AI技術根據風險水平進行分類,具體為:最小、有限、高以及不可接受。高風險技術不會被禁止,但相關公司將被要求在運營中保持高度透明。而所謂透明,其中的規則就是迫使相應的公司闡明其人工智能模型的內部運作方式。
而這項法案一旦通過,意味著將成為歐盟成員國內直接適用的法律,之后如果企業想在歐盟銷售或使用人工智能產品就必須遵守相應的法規,否則將面臨高達其全球年營業額 6% 的罰款。
但FLI認為,歐洲對其他國家的技術依賴可能阻礙歐盟參與制定人工智能全球標準的努力。
歐洲的問題在于,缺乏一個統一的大市場。
在GDP總量上,歐盟2022年GDP16.65萬億美元與中國相當;在人口數量上,歐盟2022年人口4.46億,甚至超過美國3.32億。但歐盟卻擁有28個國家,23種官方語言,再加上與美國的深度綁定,都導致歐盟在互聯網時代沒有創造出一個大型的互聯網企業,進而在數據量、云計算、推理訓練等AI大模型相關的基礎設施上被持續拉開。
如今在AI大模型領域,歐洲已經很難組織起一場強有力的阻擊,但對于中國企業來說,歐洲仍然是一個廣闊的市場。
許多人可能會認為,中國的AI大模型是從“文心一言”開始的。但“文心一言”其實只是一個類ChatGPT的產品,背后驅動它的AI大模型無論是百度、阿里、還是騰訊、華為都早有布局。
但有意思的是,中國第一個AI大模型并不來自于這些牛逼哄哄的大企業,而是2021年3月由智源研究院發布的“悟道1.0”。
可能會有人好奇,智源研究院是個什么角色,那我告訴你,它是妥妥的國家隊。
智源研究院是科技部和北京市支持的,依托北京大學、清華大學、中國科學院、百度、小米、曠視科技等北京人工智能方面優勢企業共同建立的研究機構。
智源研究院推出的悟道1.0并不是某個大模型的名稱,而是一系列大模型的統稱。
具體包括我國首個面向中文的預訓練語言模型悟道·文源;首個公開的中文通用圖文多模態預訓練模型悟道·文瀾,首個具有認知能力的超大規模預訓練模型悟道·文匯和超大規模蛋白質序列預測預訓練模型悟道·文溯。
除了發布了諸多冠名“第一”的大模型之外,智源研究院還為中國構建了大規模預訓練模型技術體系,并建設開放了全球最大中文語料數據庫WuDaoCorpora,為后來其他企業發展AI大模型打下了基礎。
而或許是受“悟道1.0”的影響,后來幾乎所有企業,在發布大模型的時候都不止發一個,而是一串。
比如百度在2019年發布了文心大模型。和悟道AI一樣,文心大模型也是諸多模型的統稱,包括NLP、CV(機器學習)、跨模態大模型和生命計算大模型四個類別36個大模型。
3月16日,基于文心大模型,百度發布文心一言,成為中國第一個類ChatGPT產品。
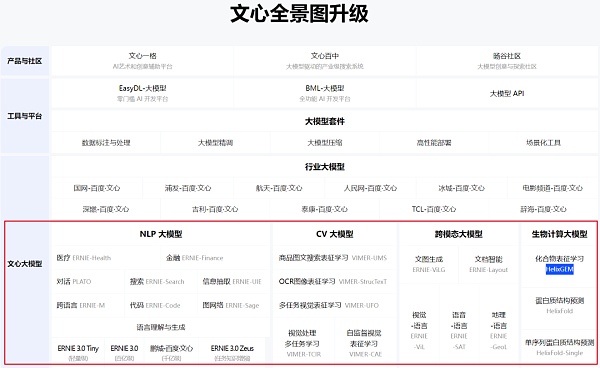
圖源百度文心大模型官網
華為在在2021年基于昇騰 AI 與鵬城實驗室聯合發布了鵬程盤古大模型。盤古大模型包括CV和NLP兩類大模型。其中,盤古NLP大模型是業界首個千億級中文NLP大模型。
阿里在2022年9月發布了“通義”大模型系列,包含NLP大模型AlicMind、視覺大模型CV,多模態大模型M6。其中M6大模型是國內首個千億參數多模態大模型。
目前,阿里巴巴“”通義”大模型系列已在超過200個場景中提供服務,實現了2%-10%的應用效果提升。典型使用場景包括電商跨模態搜索、AI輔助設計、開放域人機對話、法律文書學習、醫療文本理解等。
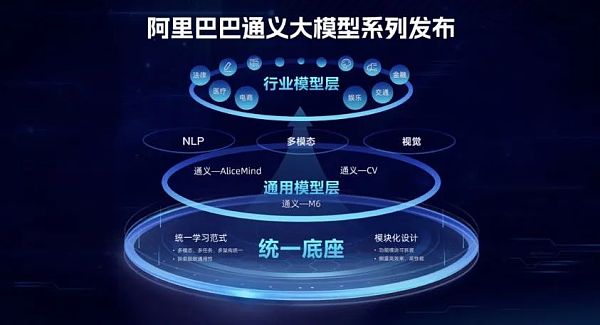
圖源阿里官網
同樣在2022年,騰訊發布混元AI大模型,其中包含NLP、CV和多模態等基礎模型和眾多行業/領域模型。到今年2月初,騰訊混元AI大模型團隊再推出萬億中文NLP預訓練模型HunYuan-NLP-1。目前HunYuan-NLP-1T大模型已在騰訊廣告、搜索、對話等內部產品落地,并通過騰訊云服務外部客戶。
到今年2月底,騰訊也開始研發類ChatGPT產品,并已成立“混元助手(HunyuanAide)”項目組。
商湯在3月14日發布多模態通用大模型“書生2.5”,擁有30億參數,其圖文跨模態開放任務處理能力可為自動駕駛、機器人等通用場景任務提供感知和理解能力支持。“書生(INTERN)”最初版本由商湯科技、上海人工智能實驗室、清華大學、香港中文大學、上海交通大學在2021年11月首次共同發布。
在此之外,京東在2月10日宣布研發產業版ChatGP—ChatJD,網易、360、字節跳動等也宣布了在AI大模型方面的布局。
可以說,目前國內有頭有臉的互聯網企業基本都擁有一個AI大模型,或者制定了相應的計劃。
而與國外企業大多專注于一個大模型不同,中國企業在大模型方面的布局并不愛單打獨斗,而是喜歡通過一個系列來打組合拳。
另一個特點在于,與國外大模型在實驗室打磨成熟之外,中國大模型都是從產業端實戰出來的。比如阿里、百度、騰訊的大模型都會應用到廣告推送、社交平臺的圖片識別,內容分發等領域。
因此在中國企業發力大模型的時候,消費端的用戶感知其實并不強烈,但當你體驗到廣告推送越來越準確,視頻平臺和電商平臺的猜你喜歡越來越能Get到你的點,后面都有大模型的功勞。
在大廠之外,與韓國缺少創業不同,AI大模型正在中國帶動AI大模型領域的創業風潮。
從前美團聯合創始人王慧文在朋友圈公開組隊開始,阿里VP賈揚清,創新工場CEO李開復、前搜狗CEO王小川、前京東AI掌門人周伯文、出門問問創始人李志飛等人紛紛下場創業,據「自象限」不完全統計,目前下場的大佬已有10位。
關于中國ChatGPT的創業機會,「自象限」《ChatGPT啟示錄》專題下一篇《中國ChatGPT創業啟示錄(上)》將會具體提到,歡迎持續關注。
除了創業之外,中國投資機構也在躍躍欲試。
在王慧文確認下場AI大模型之后,一張真格基金合伙人戴雨森、劉元與王慧文、李志飛喝酒的圖片在網上瘋傳,被認為是AI大模型時代的標志性照片。目前,王慧文的光年之外已經確認2.3億美元的新一輪融資,其中可能包括真格資本和源碼資本。

戴雨森、王慧文、李志飛、劉元(從左至右)圖源36氪
除此之外,在奇績創壇2022年11月舉辦的2022年秋季路演中,陸奇選擇的55個項目,其中就有16個項目與大模型相關。
可以說,AI大模型正在成為中國硬科技投資的一個新風向。關于中國ChatGPT的投資現狀,「自象限」專題《ChatGPT啟示錄》第四篇《中國ChatGPT投資啟示錄》將會具體提到,歡迎持續關注。
整體來看,從投資、創業到應用,中國幾乎是目前世界上最活躍的市場。
所以我們大可不必糾結為什么ChatGPT沒有發生在中國,因為未來仍然大有可為。
參考資料:
https://www.intellilink.co.jp/column/ai/2022/070800.aspx
https://bigscience.huggingface.co/blog/bloom
https://futureoflife.org/wpcontent/uploads/2022/11/Emerging_NonEuropean_Monopolies_in_the_Global_AI_Market.pdf
http://m.ce.cn/gs/gd/202303/15/t20230315_38444222.shtml
資本實驗室
企業專欄
閱讀更多
金色財經 善歐巴
Chainlink預言機
金色早8點
白話區塊鏈
Odaily星球日報
Arcane Labs
深潮TechFlow
歐科云鏈
BTCStudy
MarsBit
由全球數以萬計的從業者共同組建的Web3.0時至今日已持續推動多領域的創新和發展 而在這條道路上行走的 有百年一遇的天才技術專家也有「天賦絕倫」的黑客或惡意者 我們也十分好奇 在Cointele.
1900/1/1 0:00:00進入 2023 年第一季度以來,NFT 規模出現可喜回升,鏈上交易活動逐漸活躍,市場開始密集上新,新老玩家競爭加劇.
1900/1/1 0:00:00如何利用區塊鏈和智能合約技術構建出十億用戶的 Web3 社交圖譜?隨著埃隆 - 馬斯克最近接管了 Twitter,關于從大型社交網絡遷移到獨立或開放的替代方案的討論已經越來越多.
1900/1/1 0:00:003月29日,非營利組織“未來生命研究所(Future of Life Institute)”發表了一封題為“暫停巨型AI實驗”的公開信.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:508.44億美元 DeFi總市值及前十代幣 數據來源:coingecko2、過去24小時去中心化交易所的交易量26.
1900/1/1 0:00:00一文詳解 PoseiSwap,Nautilus Chain 上的首個 DEX 前不久.
1900/1/1 0:00:00


