






 BTC/HKD+0.29%
BTC/HKD+0.29% ETH/HKD-0.14%
ETH/HKD-0.14% LTC/HKD+0.34%
LTC/HKD+0.34% DOT/HKD+1.23%
DOT/HKD+1.23% ADA/HKD-0.08%
ADA/HKD-0.08% SOL/HKD-0.46%
SOL/HKD-0.46% XRP/HKD+0.13%
XRP/HKD+0.13% DOGE/US+0.5%
DOGE/US+0.5%今天是新專欄《AI白身境》的第九篇,所謂白身,就是什么都不會,還沒有進入角色。
咱們這個系列接近尾聲了,今天來講一個非常重要的話題,也是很多的小伙伴們關心的問題。要從事AI行業,吃這碗飯,至少應該先儲備一些什么樣的數學基礎再開始。
下面從線性代數,概率論與統計學,微積分和最優化3個方向說起,配合簡單案例,希望給大家做一個拋磚引玉,看完之后能夠真正花時間去系統性補全各個方向的知識,筆者也還在努力。
作者|言有三
編輯|言有三
01線性代數
1.1向量
什么是數學?顧名思義,一門研究“數”的學問。學術點說,線性代數是一個數學分支,來源于希臘語μαθηματικ,意思是“學問的基礎”。
數學不好,就不要談學問了,只能算知識。
按照維基百科定義:數學是利用符號語言研究數量、結構、變化以及空間等概念的一門學科,從某種角度看屬于形式科學的一種。所以一看見數學,我們就想起符號,方程式,簡單點比如這個。
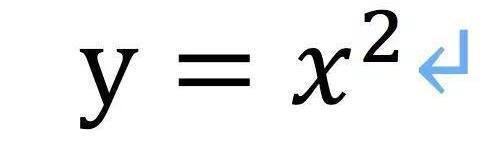
復雜的比如這個
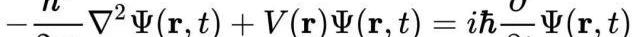
代數是數學的一個分支,它的研究對象是向量,涵蓋線、面和子空間,起源于對二維和三維直角坐標系的研究。
我們都知道歐式空間,任何一個向量(x,y,z)可以由三個方向的基組成
(x,y,z)=x(1,0,0)+y(0,1,0)+z(0,0,1)
它的維度是3,拓展至n就成為n維空間,這N維,相互是獨立的,也就是任何一個都不能由其他的幾維生成,這叫線性無關,很重要。
MakerDAO:存入Spark Protocol的95%的抵押品為Lido wstETH:5月30日消息,MakerDAO 發推稱,存入其借貸協議 Spark Protocol 的 95% 的抵押品為 Lido wstETH(約合 1085 萬美元)。[2023/5/30 11:47:57]
2.2線性回歸問題
用向量表示問題有什么用呢?
假如基友今天約你去吃飯,沒有說好誰買單,而根據之前的慣例你們從來不AA,今天你剛交了房租,沒錢了,那么該不該去呢?我們可以先回歸一下他主動買單的概率,先看一下和哪些變量有關,把它串成向量。
X=(剛發工資,剛交女朋友,剛分手,要離開北京,有事要我幫忙,無聊了,過生日,就是想請我吃飯,炒比特幣賺了,炒比特幣虧了,想蹭飯吃),共11維,結果用Y表示
Y=1,表示朋友付款,Y=-1,表示不付款
好,我們再來分析下:
和Y=1正相關的維度:要離開北京,有事要我幫忙,過生日,就是想請我吃飯,炒比特幣賺了
和Y=-1正相關的維度:想蹭飯吃
暫時關系不明朗的維度:剛發工資,剛交女朋友,剛分手,無聊了,炒比特幣虧了
好,拿出紙筆,今天是2019年1月22日,據我所知,這貨就是一個典型的死宅摩羯工作狂
剛發工資=0,時候沒到
剛交女朋友=0,不可能
剛分手=0,沒得選
要離開北京=0,不像
有事要我幫忙=0,我能幫上什么忙
無聊了=1,估計是
過生日=0,不對
就是想請我吃飯=0,不可能
炒比特幣賺了=?,不知道
炒比特幣虧了=?,不知道
想蹭飯吃=?,不知道
這下麻煩了,有這么多選項未知,假如我們用一個權重矩陣來分析,即y=WX,W是行向量,X是列向量
當前以太坊Gas費飆漲165%至53GWei:金色財經報道,據ultrasound.money數據顯示,當前以太坊Gas費升至53GWei附近,10分鐘飆漲165%,表面ETH鏈上活躍度有所上升。[2023/4/7 13:49:47]
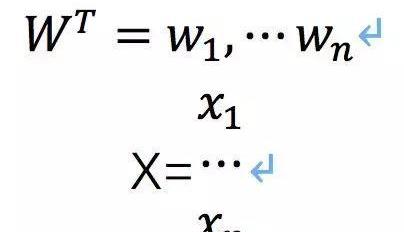
X1到xn就是前面那些維度。現在等于
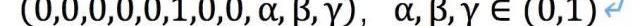
假如我們不學習參數,令所有的wi與y=1正相關的系數為1,與y=-1正相關為-1,關系不明的隨機置為0.001和-0.001,那么就有下面的式子
還是3個未知數,問題并沒有得到解決。

不過我們還是可以得到一些東西:
我們的模型還沒有得到訓練,現在的權重是手工設定的,這是不合理的,應該先抓比如1萬個樣本來填一下報告,把X和Y都填上。當然,要保證準確性,不能在報告中填了說自己會請客,實際吃起來就呵呵呵。這樣就是標簽打錯了,肯定學不到東西。從X來看,這個朋友還是可以的,與y=1正相關的變量更多,但是,未必!因為現在X的維度太低了,比如這個朋友是不是本來就是小氣鬼或者本來就喜歡請人吃飯,比如是來我家附近吃還是他家附近吃,比如他吃飯帶不帶女孩等等。上面提到了一些隨機性,比如權重W的隨機性,0.001或者-0.001,X本身的噪聲α,β,γ。是不是很復雜,現實問題本來就很復雜嘛。不過如果你沒有經濟問題,那就可以簡單點,不管這個模型,只問你今天想不想吃飯,是就去,不想吃就不去。
線性代數就說這么多,后面想好好學,一定要好好修行線性代數和矩陣分析,咱們以后再說,書單如下。
Kraken上的ETH期貨未平倉合約達到5個月高點:金色財經報道,據Glassnode的數據顯示,Kraken上的ETH期貨合約未平倉合約剛剛達到5個月高點,數值為25,506,633.07美元[2023/3/1 12:35:52]

以下是一些關鍵詞,如果都熟練了解了第一階段也就OK了。
標量,向量,特征向量,張量,點積,叉積,線性回歸,矩陣,秩,線性無關與線性相關,范數,奇異值分解,行列式,主成分分析,歐氏空間,希爾伯特空間。
02概率論與統計學
2.1概率論
概率大家都知道吧,研究的是隨機性事件。大家應該都曾經飽受貝葉斯公式的折磨。
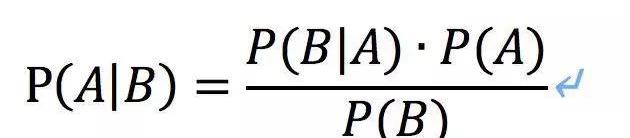
概率論中有以下幾個概念,還是以之前的吃飯問題,朋友主動叫我吃飯為事件X,也叫觀測數據,他請客了事件為Y,有以下幾個概率,其中P(A|B)是指在事件B發生的情況下事件A發生的概率。
(1)X的先驗概率,即朋友主動喊我吃飯的概率p(X),與Y無關。
(2)Y的先驗概率p(Y):即單純的統計以往所有吃飯時朋友請客的概率p(Y),與X無關。
(3)后驗概率p(Y|X):就是給出觀測數據X所得到的條件概率,即朋友喊我吃飯,并且會請客的概率。
anyway,飯我們吃完了,現在回家,結果未來的女朋友打來電話問去干嘛了,氣氛有點嚴肅,原來是吹牛皮過程中沒有看微信漏掉了很多信息。只好說去應酬了,妹子不滿意問你還有錢吃飯,誰請客。我說不吃白不吃啊,朋友請。
Binance:良好的稅收政策應使用特定于加密的框架以及提供精確的指南:金色財經報道,Binance發布關于加密稅收政策的文章,列出為加密資產行業制定良好稅收政策的一般原則包括:引入特定于加密貨幣的框架 、提供詳細且技術上精確的規則或指南、征稅并引入與類似行業(如金融和科技)的一致而非更復雜的加密貨幣報告義務、對已實現的資本收益征收特權稅而非交易稅、推行有吸引力的政策。[2023/2/23 12:25:10]
妹子又問,誰主動提出吃飯的!
正好,那不就是要算后驗概率p(X|Y)嗎?也就是飯吃了,誰提議的。
于是故作聰明讓妹子猜,還給了一個提示可以用貝葉斯公式,并且已知p(Y)=0.2,p(X)=0.8,再加上上面算出來的p(Y|X)

好了又回到了這個問題,3個未知變量。
不過沒關系,我們可以先用它們的數學期望來替換掉,數學期望就是一個平均統計。
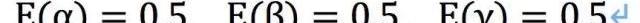
這說明什么?說明這一次吃飯,是朋友先動的嘴的概率p(X|Y)=0.002,那么今天99.8%是自己跑出去蹭吃吹牛皮了。
接下來的問題就是搓衣板是跪還是不跪,貝葉斯公式解決不了。
事情結束后,要想好好搞下去,肯定是要學好概率論和統計學習的。

同樣,有一些關鍵詞要掌握。
不確定性,隨機變量,大數定律,聯合分布,邊緣分布,條件概率,貝葉斯公式,概率密度,墑與交叉墑,期望,最大似然估計,正態分布/高斯分布,伯努利分布,泊松分布,概率論與統計推斷,馬爾可夫鏈,判別模型,生成模型。
M2E項目Sweat基金會承諾將用其利潤的50%回購代幣SWEAT:9月15日消息,Move-to-Earn項目Sweat Еconomy發文稱Sweat基金會承諾將用其利潤的50%從二級市場購買SWEAT,此SWEAT將被銷毀或作為質押收益分發,以此來減少流通中的代幣來增強代幣效用。Sweat基金會的收入主要通過用戶參與以及交易費用兩個方式產生。[2022/9/15 6:58:40]
有意思的是:概率論還有一些東西是有點違背認知的,比如生日悖論。
一個班上如果有23個人,那么至少有兩個人的生日是在同一天的概率要大于50%,對于60或者更多的人,這種概率要大于99%。大家都是上過學的少年,你在班上遇到過同一天生日的嗎?
2.2傳統機器學習算法基礎
傳統機器學習算法本來不應該放在這里說,但是因為其中有一部分算法用到了概率論,所以也提一句。
有很多人在知乎上問,搞深度學習還需要傳統機器學習基礎嗎?當然要!且不說這個傳統機器學習算法仍然在大量使用,光是因為它經典,就值得學習一下,依舊推薦一本書。

機器學習完成的任務就是一個模式識別任務,機器學習和模式識別這兩個概念實際上等價,只是歷史原因說法不同。
一個模式識別任務就是類似于識別這個圖是不是貓,這封郵件是不是垃圾郵件,這個人臉是不是你本人之類的高級的任務。
傳統的機器學習算法有兩大模型,一個是判別模型,一個是生成模型,我們以前講過,大家可以去看。
有三說GANs
傳統機器學習算法就不展開了,太多。
03微積分與最優化
3.1導數
機器學習就是要學出一個模型,得到參數嘛,本質上就是優化一個數學方程,而且通常是離散的問題,這個時候大殺器就是微積分了。
微積分是什么,根據維基百科:
微積分學曾經指無窮小的計算,就是一門研究變化的學問,更學術點說就是研究函數的局部變化率,如下。
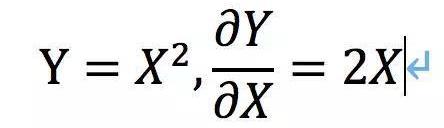
可知,在不同的X處它的導數是不相等的。如果遇到了一個導數為0的點,它很有可能就是最大值或者最小值,如下面的x=0點取得最小值y=0。
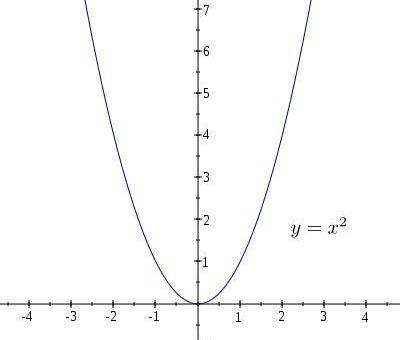
導數反映了y的變化趨勢,比如這個方程x>0時,導數大于0,則y隨著x的增加而增加。x<0時,導數小于0,則y隨著x的增加而減小。
所以看導數,我們就得到了目標y的變化趨勢,而深度學習或者說機器學習中需要優化的目標就是一個Y,也稱之為目標函數,價值函數,損失函數等等。通常我們定義好一個目標函數,當它達到極大值或者極小值就實現了我們的期望。
不過還有個問題,就是導數等于0,一定是極值點嗎?未必,比如鞍點。

上面的小紅點就是鞍點,在這個曲面上,它在某些方向的導數等于0,但是顯然它不是極值點,不是極大也不是極小,正因如此,給后面的優化埋下了一個坑。
如果你真的微積分也忘了,就需要補了。

3.2數值微分
前面說了,機器學習就是要求解目標的極值,極大值極小值是等價的不需要糾結,通常我們求極小值。
上面的函數我們輕輕松松就求解出了導數,從而得到了唯一的極值,這叫做解析解,答案很唯一,用數學方程就能手算出來。
但是實際要優化的神經網絡上百萬個參數,是不可能求出解析解的,只能求數值近似解,就是用數值微分的方法去逼近。
數值微分的核心思想就是用離散方法近似計算函數的導數值或偏導數值,相信同學們在課程中都學過。
向前差商公式:
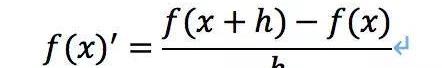
向后差商公式:
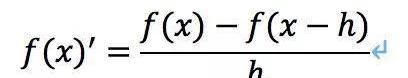
中心差商公式:
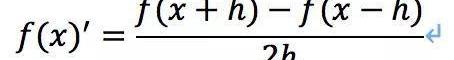
有了感覺咱們接著說
那么,一般情況下要求解任意函數極值的方法是什么呢?在深度學習中就是梯度下降法。
梯度下降法可以說是最廣泛使用的最優化方法,在目標函數是凸函數的時候可以得到全局解。雖然神經網絡的優化函數通常都不會是凸函數,但是它仍然可以取得不錯的結果。
梯度下降法的核心思想就是(公式比較多,就截圖了):

這一套對所有的函數f(x)都通用,所以以導數的反方向進行搜索,就能夠減小f(x),而且這個方向還是減小f(x)的最快的方向,這就是所謂的梯度下降法,也被稱為“最速下降法”,參數更新方法如下。
關于微積分和最優化,咱們就點到為止了,不然就超出了白身境系列的要求。要補這方面的知識,就比較多了,建議先找花書中的對應章節看看,找找感覺再說。

最優化的方法還有很多,目前在神經網絡優化中常用的是一階優化方法,不過二階優化方法也慢慢被研究起來,最后還是給出一些關鍵詞去掌握。
導數,偏導數,線性規劃,二次規劃,動態規劃,Hessianmatrix,損失函數,正則項,一階優化方法(梯度下降法),二階優化方法(牛頓法)等等。
好嘞,掌握了這些,就大膽往前走,不用怕了。
總結
數學這種東西,學習就是三步曲,一看書,二做題,三應用,其他學習方法比如看視頻聽課基本都是扯淡。
另外,數學怎么好都不過分。希望小白看完還能愛數學,畢竟這才剛剛開始一點點。
下期預告:下一期我們講AI在當前各大研究方向。
4月24日,上交所網站顯示,貴州白山云科技股份有限公司、博拉網絡股份有限公司的科創板上市申請已獲受理。至此,科創板申請受理企業總數已增加至92家.
1900/1/1 0:00:00美聯儲主席杰鮑威爾,在參議院銀行委員會就Facebook計劃的天秤幣加密貨幣作證時,將比特幣比喻為“像黃金一樣的價值儲藏庫”.
1900/1/1 0:00:00在如今的小球時代,NBA的每一場比賽都充滿著無限的可能,注定是一個創造籃球奇跡的時代。在雷霆對陣湖人的比賽中,威少砍下20+20+21的大號三雙,幫助球隊在斯臺普斯球館取得了勝利.
1900/1/1 0:00:00馬云最年輕的門徒和堅定的幣圈從業者搖身一變,成了巴菲特門徒和堅定的價值投資者,孫宇晨是如何做到的?6月4日凌晨,孫宇晨在微博上證實此前傳聞.
1900/1/1 0:00:00京東和美團均已申請導航電子地圖甲級資質,但申請未獲自然資源部審核通過,主要原因是兩家公司VIE結構協議條款不符合規定。知情人士向財新記者透露上述信息.
1900/1/1 0:00:00來源:期貨日報 原創:周曉雅來源:期貨日報“當初聽信專家對比特幣的觀點,心想著搏一搏說不定能賺點外快,前前后后花了十幾萬去挖礦,沒想到現在居然成韭菜了.
1900/1/1 0:00:00


