






 BTC/HKD+0.64%
BTC/HKD+0.64% ETH/HKD+0.38%
ETH/HKD+0.38% LTC/HKD-0.2%
LTC/HKD-0.2% DOT/HKD-2.97%
DOT/HKD-2.97% ADA/HKD+0.27%
ADA/HKD+0.27% SOL/HKD+1.63%
SOL/HKD+1.63% XRP/HKD-0.85%
XRP/HKD-0.85% DOGE/US+2.2%
DOGE/US+2.2%本文主要來介紹NLP中的命名實體識別。命名實體識別與中文分詞、詞性標注一樣,也是NLP的一個基礎任務,是信息抽取、信息檢索、機器翻譯、問答系統等多種NLP技術不可或缺的一部分。其目的是:識別語料中的人名、地名、組織機構名等命名實體。
隨著命名實體數量的不斷增加,一般不可能在詞典中全部列出,由于命名實體的構成方法具有規律性,通常把對這些詞的識別在任務中進行獨立處理,稱之為命名實體識別。NER一般分為3大類和7小類。

1.中文命名實體識別的難點
各類命名實體的數量眾多。命名實體的構成規律復雜。比如人名的構成規則各有不同,中文人名識別又可以細分為中國人名識別、日本人名識別和音譯人名識別等;再比如機構名的組成方式,機構名的種類繁多,各有獨特的命名方式,用詞也相當廣泛,只有結尾用詞相對集中。嵌套情況復雜。一個命名實體經常和一些詞組合成一個嵌套的命名實體,人名中嵌套著地名,地名中也經常嵌套著人名。長度不確定。與其他類型的命名實體相比,長度和邊界難以確定,使得機構名更難識別。中國人名一般二到四字,常用地名一般二到四字,但是機構名長度變化范圍極大,少的只有兩個字簡稱,多的達到幾十個字的全稱。2命名實體識別方式
Coinbase Cloud與Chainlink Labs合作推出NFT地板價喂價服務:9月29日消息,Coinbase Cloud和Chainlink Labs合作推出NFT地板價喂價服務,允許開發人員實時訪問NFT價格以創建新的DeFi應用程序,如NFT借貸市場和NFT指數。該功能將首先支持Bored Ape Yacht Club、CryptoPunks、CloneX和World of Women這些藍籌NFT。(Decrypt)[2022/9/29 22:39:23]
中文分詞中,主要有基于規則方法、基于統計方法和基于二者的混合方法。命名實體識別主要也包含這三種方法。
基于規則的命名實體識別:規則加詞典是早期命名實體識別中最行之有效的方式。依賴手工規則,結合命名實體庫,對每條規則進行權重賦值,然后通過實體與規則的相符情況來進行類型判斷。基于統計的命名實體識別:與分詞類似,目前主流的基于統計的命名實體識別方法有:隱馬爾可夫模型、最大熵模型、條件隨機場等。其主要思想是:基于人工標注的語料,將命名實體識別任務作為序列標注問題來解決。基于混合的命名實體識別:NLP并不完全是一個隨機過程,單獨使用基于統計的方法使狀態搜索空間非常龐大,必須借助規則知識提前進行過濾修剪處理。目前幾乎沒有單純使用統計模型而不使用規則知識的命名實體識別系統,在很多情況下是使用混合方法,結合規則和統計方法。序列標注方式是目前命名實體識別中的主流方法,下面重點介紹基于CRF條件隨機場的方法。
預言機項目Chainlink宣布為Solana主網提供喂價服務:6月3日消息,預言機項目 Chainlink 宣布為 Solana 主網提供喂價服務。在 Solana 主網上構建 DeFi 項目的開發人員現在可以將 Chainlink 的喂價服務整合到他們的產品中。Solana 也由此成為 Chainlink 支持的第一個非 EVM 鏈。[2022/6/3 4:01:02]
3基于CRF的命名實體識別
條件隨機場的主要思想來源于HMM,也是一種用來標記和切分序列化數據的統計模型。不同的是,條件隨機場是在給定觀察的標記序列下,計算整個標記序列的聯合概率,而HMM是在給定當前狀態下,定義下一個狀態的分布。
條件隨機場的定義為:假設X=(X1,X2,X3,…,Xn)和Y=(Y1,Y2,Y3,…,Ym)是聯合隨機變量,若隨機變量Y構成一個無向圖G=(V,E)表示的馬爾可夫模型,則其條件概率分布P(Y|X)稱為條件隨機場,即:
Chainlink與CRD合作以實現跨DeFi平臺的KYC數據互相操作性:10月29日消息,Chainlink宣布與DeFi生態系統CRD Network合作,為各種跨DeFi平臺帶來多合一的合規方案,不僅可實現KYC數據的互相操作性,還允許DeFi應用程序訪問CRD Network的數據庫,以驗證用戶數字地址的各種指標。(Ambcrypto)[2021/10/29 6:19:29]
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)
其中w~v表示無向圖G=(V,E)中與結點v有邊連接的所有節點,w≠v表示結點v以外的所有節點。
例如:對句子“我來到陶家村”進行標注,正確標注后的結果為:我/O來/O到/O陶/B家/M村/E。采用線性鏈CRF來進行解決,那么是其一種標注序列,也是是其一種標注選擇,類似的可選擇的標注序列有很多,在NER任務中就是在這么多的可選標注序列中,找出最靠譜的作為句子的標注。
BitGo前CTO擔任Chainlink Labs工程副總裁:金色財經報道,Chainlink周五宣布,數字資產托管服務提供商BitGo的前首席技術官Ben Chan已加入Chainlink,將擔任Chainlink Labs的工程副總裁,為去中心化Oracle網絡構建第二層擴容解決方案。[2020/10/17]
那么我們要解決的問題就是要判斷標注序列是否靠譜。就剛才的兩種標注方法,顯然第一種比第二種更為準確,因為第二種將“陶”和“家”都作為地名首字標成了“B”,一個地名兩個首字符,顯然不合理。假如給每個標注序列打分,分值代表標注序列的靠譜程度,越高代表越靠譜,那么可以定一個規則,若在標注中出現連續兩個“B”結構的標注序列,則給它低分。連續“B”結構打低分就對應一條特征函數。在CRF中,定義一個特征函數集合,然后使用這個特征函數集合為標注序列進行打分,據此選出最靠譜的標注序列,該序列的分值是通過特征函數集合得出的。
動態 | 加密公司CoinList獲得包括推特CEO在內的1000萬美元戰略投資:加密初創公司CoinList在新一輪融資中獲得了包括推特CEO在內的1000萬美元戰略投資。Twitter首席執行官Jack Dorsey是CoinList幾位投資者之一,該公司已成立兩年,旨在幫助初創企業通過代幣銷售籌集資金。(華爾街日報)[2019/10/30]
在CRF中有兩種特征函數,分別為:轉移函數tk(yi-1,yi,i)和狀態函數sl(yi,X,i)。tk(yi-1,yi,i)依賴于當前和前一個位置,表示從標注序列中位置i-1的標記yi-1轉移到位置i上的標記yi的概率。sl(yi,X,i)依賴當前位置,表示標記序列在位置i上為標記yi的概率。通常特征函數取值為1或0,表示符不符合該條規則約束。
4日期識別代碼示例
應用場景:
現有一個智能外呼系統,由機器人撥打電話給客戶,通知客戶新股中簽情況,客戶與機器人進行對話。對話機器人根據用戶的語音進行解析,發覺用戶的需求,比如:新股中簽的時間,新股買入的時間等。通過asr技術將用戶的語音轉換成中文文本,然后由于asr的識別準確度問題,許多日期類的數據并不是嚴格的數字,比如會出現“十一月12日”“2019年11月”“20191112”“后天下午”等形式。
現在的需求是識別出每個請求文本中可能的日期信息,并將其轉換成統一的格式進行輸出。比如:“我打算今天或明天買入新股”,那么通過日期解析后,應該輸出為“2019-11-12”和“2019-11-13”。
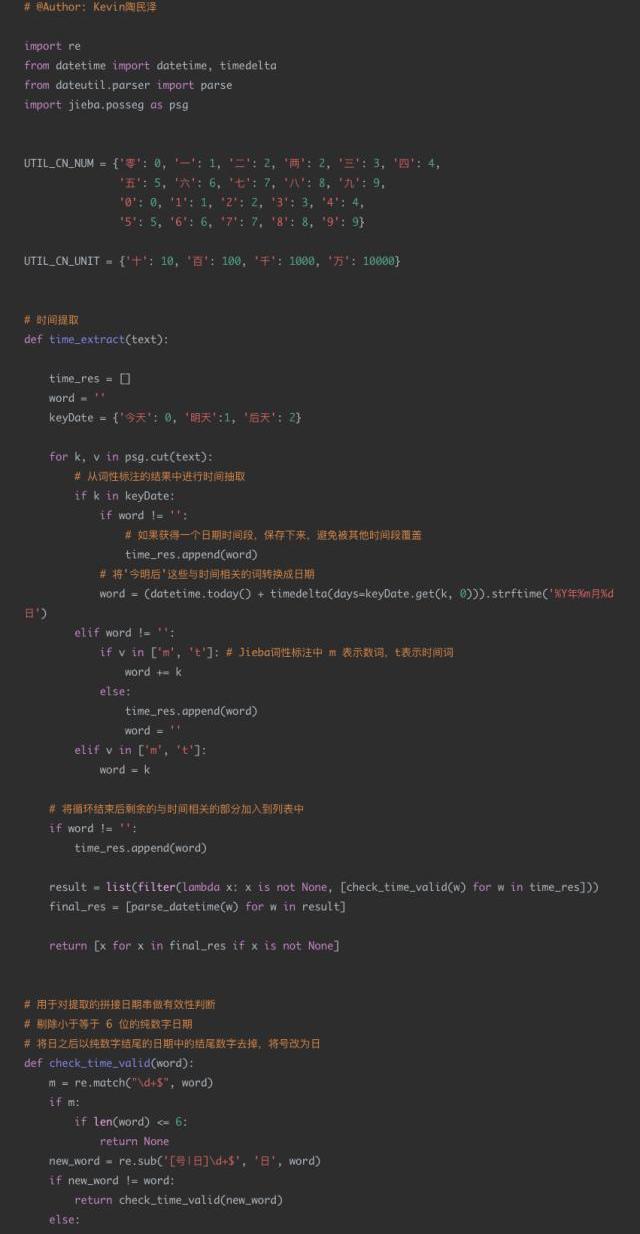
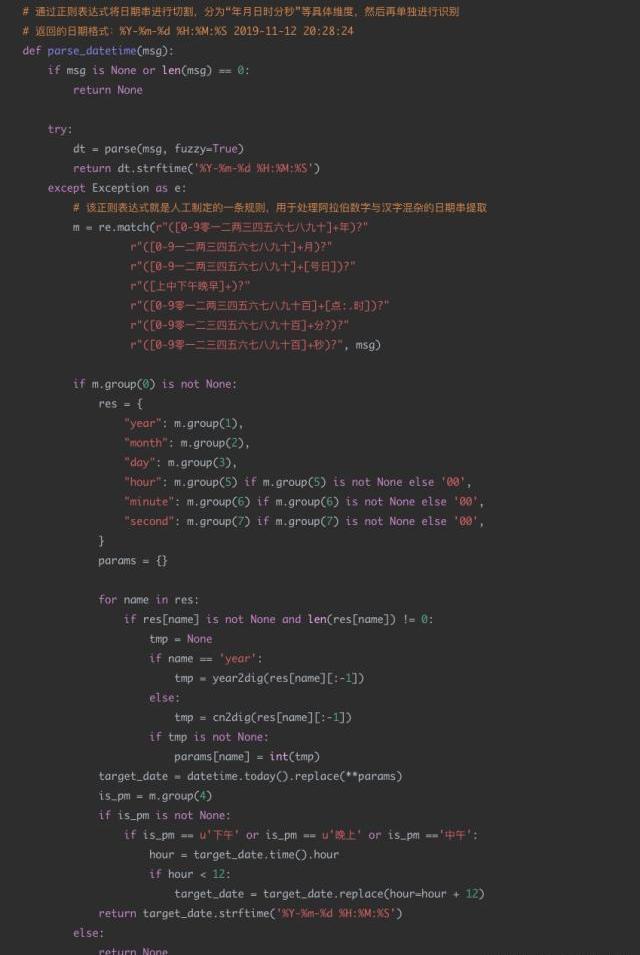
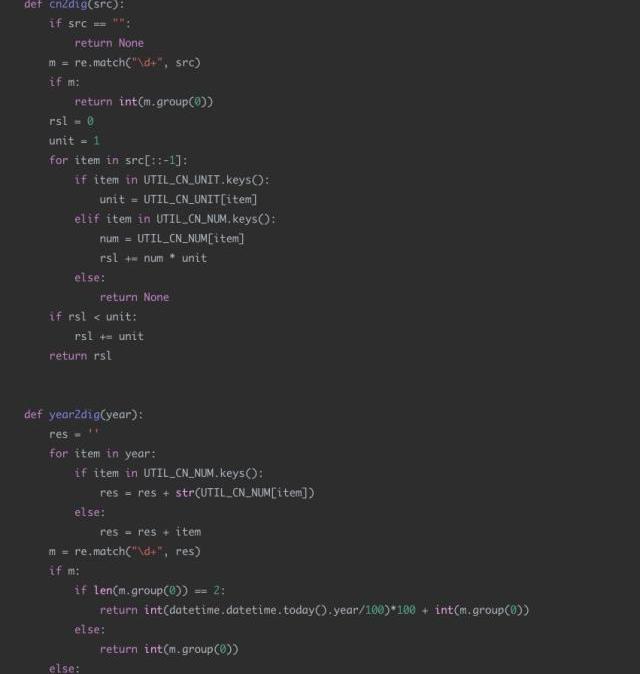
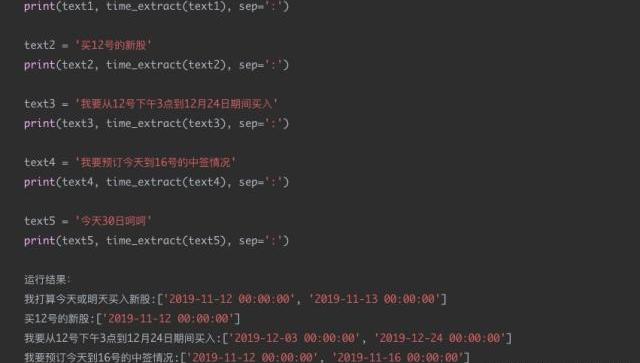
通過結果分析可以看到,text1text2text3text4結果還是相對較好的,對于text5這種規則覆蓋之外的場景,方法效果大大降低。
作者:KevinTao
知乎號:Kevin陶民澤
備注:轉載請注明出處。
如發現錯誤,歡迎留言指正。
24小時行情速覽 比特幣跌1.32%,暫報8671.76美元。以太坊漲0.42%,暫報185.35美元。瑞波幣漲0.36%,暫報0.2687美元。比特幣現金漲0.75%,暫報278.91美元.
1900/1/1 0:00:00新型冠狀病感染的肺炎疫情牽動著人們的心,與此同時,謠言一波未平一波又起。比如“人民幣表面監測到新型冠狀病病原體”“日本派遣千人醫療隊赴武漢”“乳鐵蛋白能預防新型冠狀病”“30萬湖北籍境外旅.
1900/1/1 0:00:00因懷疑人民幣上可能沾染“新冠肺炎病”,近日江蘇無錫江陰市的李阿姨居然把現金放進微波爐中加熱消,3000多元人民幣被烤得面目全非.
1900/1/1 0:00:00《財經》新媒體劉洋/文蔣詩舟/編輯 “怎樣辨別新項目優劣?”“看頭像就行,你肯定不能去加一個穿正裝的人。”官方為區塊鏈技術定調半月有余,沉寂已久的“炒幣”圈再次活躍了起來.
1900/1/1 0:00:00公元前6世紀開始,古希臘結束古風時代,進入古典時代,他們與周邊地區的交易日漸頻繁,貨幣制度也逐漸成熟.
1900/1/1 0:00:00學無國界 我們是知識的搬運工 福利時間 今天我們將送出由清華大學出版社提供的優質科普書籍《科學是什么》。 全國優秀科普作品獎獲得者、科普作家張天蓉最新力作《科學是什么》.
1900/1/1 0:00:00


