






 BTC/HKD+0.17%
BTC/HKD+0.17% ETH/HKD+0.52%
ETH/HKD+0.52% LTC/HKD+0.72%
LTC/HKD+0.72% DOT/HKD+0.25%
DOT/HKD+0.25% ADA/HKD+1.67%
ADA/HKD+1.67% SOL/HKD+0.82%
SOL/HKD+0.82% XRP/HKD+0.97%
XRP/HKD+0.97% DOGE/US+0.81%
DOGE/US+0.81% 
作者|劉大一恒、齊煒禎、晏宇、宮葉云、段楠、周明
編者按:微軟亞洲研究院提出新的預訓練模型ProphetNet,提出了一種新的自監督學習目標——同時預測多個未來字符,在序列到序列的多個自然語言生成任務都取得了優異性能。
大規模預訓練語言模型在自然語言理解和自然語言生成中都取得了突破性成果。這些模型通常使用特殊的自監督學習目標先在大規模無標記語料中進行預訓練,然后在下游任務上微調。
傳統自回歸語言模型通過估計文本語料概率分布被廣泛用于文本建模,序列到序列的建模,以及預訓練語言模型中。這類模型通常使用teacher-forcing的方法訓練,即每一時刻通過給定之前時刻的所有字符以預測下一個時刻的字符。然而,這種方式可能會讓模型偏向于依賴最近的字符,而非通過捕捉長依賴的信息去預測下一個字符。有如以下原因:局部的關系,如兩元字符的組合,往往比長依賴更強烈;Teacher-forcing每一時刻只考慮對下一個字符的預測,并未顯式地讓模型學習對其他未來字符的建模和規劃。最終可能導致模型對局部字符組合的學習過擬合,而對全局的一致性和長依賴欠擬合。尤其是當模型通過貪心解碼的方式生成序列時,序列往往傾向于維持局部的一致性而忽略有意義的全局結構。
今日恐慌與貪婪指數為47,等級為中性:金色財經報道,今日恐慌與貪婪指數為47(昨日為49),等級為中性。
注:恐慌指數閾值為0-100,包含指標:波動性(25%)+市場交易量(25%)+社交媒體熱度(15%)+市場調查(15%)+比特幣在整個市場中的比例(10%)+谷歌熱詞分析(10%)。[2023/6/11 21:29:22]
ProphetNet
針對上述問題,我們提出了一個新的seq2seq預訓練模型,我們稱之為ProphetNet。該模型帶有一個新穎的自監督學習目標函數,即預測未來的N元組。與傳統seq2seq的Teacher-forcing每一時刻只預測下一個字符不同,ProphetNet每一時刻將學習去同時預測未來的N個字符。如圖1所示:
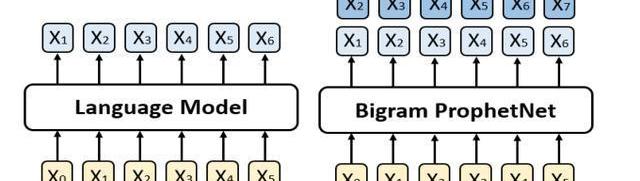
圖1:左邊是傳統的語言模型,每一時刻預測下一時刻的字符。右邊是Bigram形式下的ProphetNet,每一時刻同時預測未來的兩個字符。
數據:gTrade上線Arbitrum后月交易量逾17億美元,月收入近120萬美元:1月28日消息,加密貨幣衍生品交易所 Gains Network 推出的針對加密貨幣、外匯和股票的去中心化合成杠桿交易協議 gTrade 上線 Arbitrum 近一個月以來的交易量逾 17 億美元,gTrade 協議已產生近 120 萬美元的收入。[2023/1/28 11:33:52]
預測未來N元組這一自監督學習目標在訓練過程中顯式地鼓勵模型在預測下一個字符時考慮未來更遠的字符,做到對未來字符的規劃,以防止模型對強局部相關過擬合。
ProphetNet基于Transformer的seq2seq架構,其設計有兩個目標:1.模型能夠以高效的方式在訓練過程中完成每時刻同時預測未來的N個字符;2.模型可以靈活地轉換為傳統的seq2seq架構,以在推理或微調階段兼容現有的方法和任務。為此,我們受XLNet中Two-streamselfattention的啟發,提出了用于模型decoder端的N-streamself-attention機制。圖2展示了bigram形式下的N-streamself-attention樣例。
XEN Crypto將推出多重鑄造功能VMU,啟用后可獲得XEN Torrent NFT:10月27日消息,XEN Crypto創始人Jack Levin在其官方Youtube頻道中宣布,XEN Crypto將推出基于NFT技術的多重鑄造功能VMU(Virtual Minting Unit),用戶啟用該功能后將獲得可用于交易的XENT orrent NFT。
Jack Levin表示,用戶使用多個錢包鑄造ZEN的過程單一冗長,還會消耗大量GAS費。VMU將優化鑄幣過程,用戶不再需要重復創建錢包,而是可以直接進入XEN Crypto的網頁版App,選擇多個VMU,并一次性支付所需Gas費。
一旦用戶啟用VMU,將會獲得NFT XEN Torrent。該NFT將會記錄所有平行進行的鑄幣過程,并且可以在OpenSea上進行交易。[2022/10/27 11:48:04]
除了原始的multi-headself-attention之外,N-streamself-attention包含了額外的N個predictingstreamself-attention,用于分別預測第n個未來時刻的字符所示。每一個predictingstream與mainstream共享參數,我們可以隨時關閉predictingstream以讓模型轉換回傳統seq2seq的模式。
Limit Break已完成兩輪共計2億美元融資,Paradigm等領投:8月29日消息,NFT 項目 DigiDaigaku 母公司 Limit Break 已通過兩輪融資籌集 2 億美元,Josh Buckley、Paradigm 和 Standard Crypto 領投,FTX、Coinbase、Positive Sum、Shervinator 和 Anthos Capital 等參投。
新資金將用于開發 Web 3 MMO 游戲。Limit Break 創始人推出新模式“Free to Own”(F2O),即“免費擁有”,是基于創世 NFT 的免費鑄造而創建。這些創世 NFT 通過空投和更多的方式產出其他 NFT 系列,均不涉及到籌款環節。[2022/8/29 12:55:55]
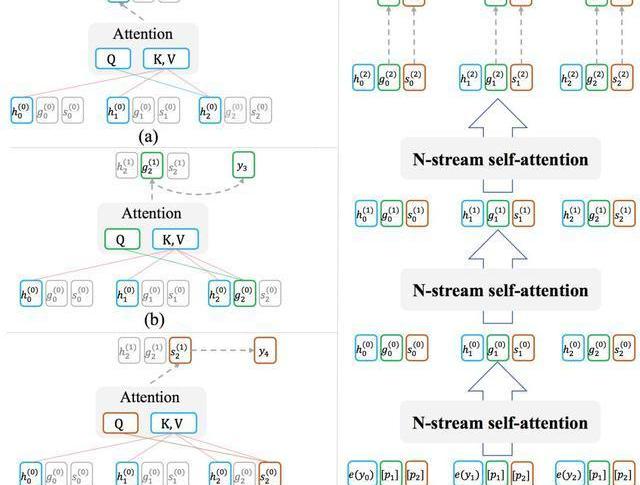
圖2:(a)為mainstreamself-attention;(b)為1-stpredictingstreamself-attention;(c)為2-ndpredictingstreamself-attention;(d)展示了n-streamself-attention的輸入輸出及流程。
灰度比特幣信托負溢價率達32.98%:8月18日消息,根據Tokenview鏈上數據顯示,灰度總持倉量達211.92億美元,主流幣種信托溢價率如下:
BTC,-32.98%;
ETH,-24.77%;
ETC,-62.58%;
LTC, -30.37%;
BCH,-20.83%。[2022/8/18 12:33:38]
由于難以獲取到大量帶標記的序列對數據,我們用去噪的自編碼任務通過大量無標記文本預訓練ProphetNet。去噪的自編碼任務旨在輸入被噪音函數破壞后的序列,讓模型學習去復原原始序列。該任務被廣泛應于seq2seq模型的預訓練中,如MASS、BART、T5等。本文中使用MASS的預訓練方式,通過引入提出的predictingn-stream自監督學習目標函數預訓練ProphetNet。我們以bigram形式的ProphetNet為例,整個流程如圖3所示:
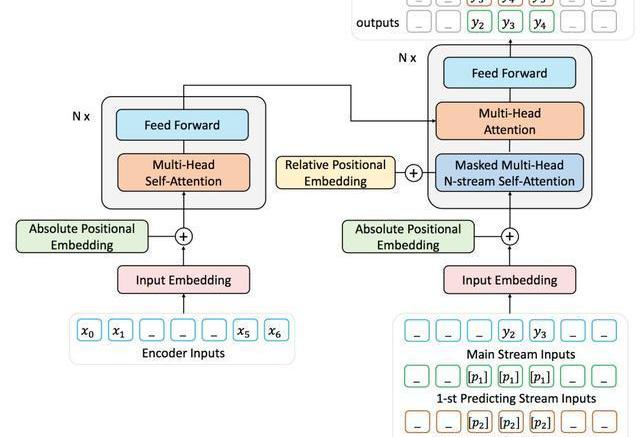
圖3:二元形式下的Prophet整體框架圖
實驗結果
我們使用兩個規模的語料數據訓練ProphetNet。ProphetNet包含12層的encoder和12層的decoder,隱層大小為1024。先在BERT所使用的BookCorpus+Wikipedia的數據上預訓練模型,將模型在Textsummarization和Questiongeneration兩個NLG任務上的三個數據集微調并評估模型性能。與使用同等規模數據的預訓練模型相比,ProphetNet在CNN/DailyMail、Gigaword和SQuAD1.1questiongeneration數據集上都取得了最高的性能,如表1-3所示。
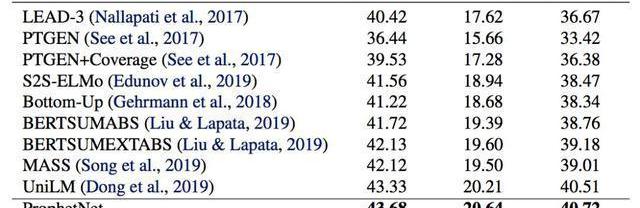
表1:CNN/DailyMail測試集結果
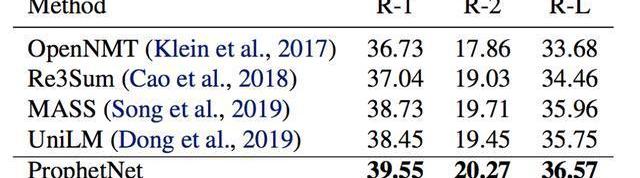
表2:Gigaword測試集結果
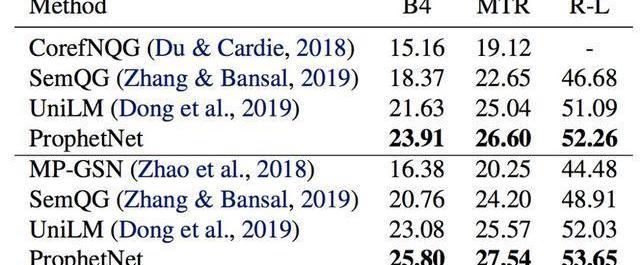
表3:SQuAD1.1測試集結果SQuAD1.1交換驗證測試集結果
除了使用16GB的語料訓練模型,我們也進行了更大規模的預訓練實驗。該實驗中,我們使用了160GB的語料預訓練ProphetNet。我們展示了預訓練14個epoch后的ProphetNet在CNN/DailyMail和Gigaword兩個任務上微調和測試的結果。如表4所示。需要注意的是,在相同大小的訓練數據下,我們模型的預訓練epoch僅約為BART的三分之一。我們模型的訓練數據使用量僅約為T5和PEGASUSLARGE的五分之一,約為PEGASUSLARGE的二十分之一。盡管如此,我們的模型仍然在CNN/DailyMail上取得了最高的ROUGE-1和ROUGE-LF1scores。并在Gigaword上實現了新的state-of-the-art性能。

表4:模型經大規模語料預訓練后在CNN/DailyMail和Gigaword測試集的結果
為了進一步探索ProphetNet的性能,我們在不預訓練的情況下比較了ProphetNet和Transformer在CNN/DailyMail上的性能。實驗結果如表5所示,ProphetNet在該任務上超越了同等參數量的Transformer。
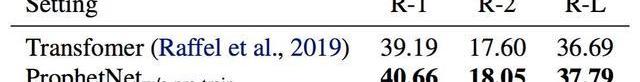
表5:模型不經過預訓練在CNN/DailyMail驗證集結果
總結
本文介紹了微軟亞洲研究院在序列到序列模型預訓練的一個工作:ProphetNet,該模型提出了一種新的自監督學習目標,在同一時刻同時預測多個未來字符。并通過提出的N-streamself-attention機制高效地實現了模型在該目標下的訓練。實驗表明,該模型在序列到序列的多個自然語言生成任務都取得了不錯的性能。我們將在之后嘗試使用更大規模的模型架構和語料進行預訓練,并進一步深入地探索該機制。
論文鏈接:https://arxiv.org/pdf/2001.04063.pdf
原力計劃
《原力計劃-學習力挑戰》正式開始!即日起至3月21日,千萬流量支持原創作者!更有專屬等你來挑戰
Python數據清理終極指南口罩檢測識別率驚人,這個Python項目開源了談論新型冠狀病、比特幣、蘋果公司……沃倫巴菲特受訪中的18個金句,值得一看!天貓超市回應大數據殺熟;華為MateXs被熱炒至6萬元;Elasticsearch7.6.1發布一張圖對比阿里、騰訊復工的區別不看就虧系列!這里有完整的Hadoop集群搭建教程,和最易懂的Hadoop概念!|附代碼
加密世界足夠隱私嗎?是,又不是。以加密資產為例,BTC、ETH本身都采用橢圓曲線數字簽名算法,能夠滿足99%的隱私要求,一般情況下,只有持有私鑰的人才能夠簽名交易,使用代幣;但另一方面,它們又不.
1900/1/1 0:00:003月9日,有群眾向鷹鑒舉報“五行幣”傳銷團伙又開始“作妖”了。該名群眾稱,“五行幣的傳銷人員最近在推廣一個叫做‘霧星鏈’項目,希望我們進行曝光,避免更多的人上當受騙.
1900/1/1 0:00:00文丨林立 “2020年,幣圈會好嗎?”幣圈許多人已不再關心這個問題的答案。近兩年,合約交易在幣圈大火,讓許多投資者不再關注比特幣的長期漲跌.
1900/1/1 0:00:00前面文章小編為大家梳理了關于IPFS&Filcoin的相關內容,相信大家已經有了了解和興趣,那么作為投資者.
1900/1/1 0:00:00大家好!爐石傳說新版本外域的灰燼給除了惡魔獵手外的九大職業都推出了一張終極隨從。兩個周的時間過去了,兩個平衡補丁上線,三次天梯環境變化,這九張終極隨從到底表現如何,是否當得起“終極”這個名號呢?.
1900/1/1 0:00:00來源:挖貝網 精選層已邁入打新時代。穎泰生物、艾融軟件、同享科技、球冠電纜將于7月1日、2日進行申購,另外還有5家企業也拿到了發行批文.
1900/1/1 0:00:00


