






 BTC/HKD+0.56%
BTC/HKD+0.56% ETH/HKD+0.21%
ETH/HKD+0.21% LTC/HKD-1.74%
LTC/HKD-1.74% DOT/HKD+0.47%
DOT/HKD+0.47% ADA/HKD-0.12%
ADA/HKD-0.12% SOL/HKD-0.69%
SOL/HKD-0.69% XRP/HKD-0.74%
XRP/HKD-0.74% DOGE/US+0.02%
DOGE/US+0.02%文章來源:新智元
編輯:Aeneas好困

最新研究結果表明,AI在心智理論測試中的表現已經優于真人。GPT-4在推理基準測試中準確率可高達100%,而人類僅為87%。
GPT-4的心智理論,已經超越了人類!
最近,約翰斯·霍普金斯大學的專家發現,GPT-4可以利用思維鏈推理和逐步思考,大大提升了自己的心智理論性能。

論文地址:https://arxiv.org/abs/2304.11490
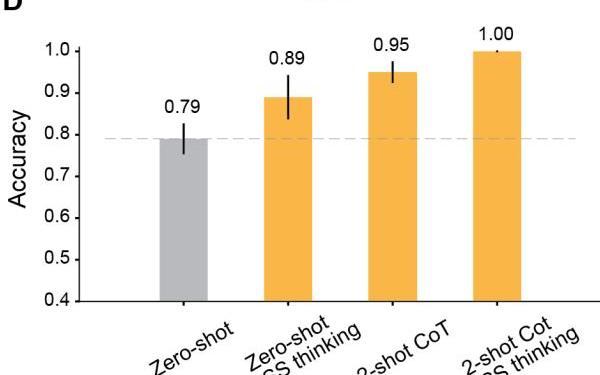
在一些測試中,人類的水平大概是87%,而GPT-4,已經達到了天花板級別的100%!
此外,在適當的提示下,所有經過RLHF訓練的模型都可以實現超過80%的準確率。
讓AI學會心智理論推理
我們都知道,關于日常生活場景的問題,很多大語言模型并不是很擅長。
Meta首席AI科學家、圖靈獎得主LeCun曾斷言:「在通往人類級別AI的道路上,大型語言模型就是一條歪路。要知道,連一只寵物貓、寵物狗都比任何LLM有更多的常識,以及對世界的理解。」

也有學者認為,人類是隨著身體進化而來的生物實體,需要在物理和社會世界中運作以完成任務。而GPT-3、GPT-4、Bard、Chinchilla和LLaMA等大語言模型都沒有身體。
所以除非它們長出人類的身體和感官,有著人類的目的的生活方式。否則它們根本不會像人類那樣理解語言。

PEPE 24小時漲幅超100%,幣價創歷史新高:金色財經報道,行情數據顯示,Meme幣Pepe(PEPE)過去24小時漲幅為102.8%,現報價0.000002223美元,幣價創歷史新高。行情波動較大,請做好風險控制。
此外,據CoinGecko數據顯示,其收錄的Meme類別代幣總市值目前為19,286,086,067美元,24小時交易額為1,288,089,101美元。[2023/5/5 14:43:58]
總之,雖然大語言模型在很多任務中的優秀表現令人驚嘆,但需要推理的任務,對它們來說仍然很困難。
而尤其困難的,就是一種心智理論推理。

為什么ToM推理這么困難呢?
因為在ToM任務中,LLM需要基于不可觀察的信息進行推理,這些信息都是需要從上下文推斷出的,并不能從表面的文本解析出來。
但是,對LLM來說,可靠地執行ToM推理的能力又很重要。因為ToM是社會理解的基礎,只有具有ToM能力,人們才能參與復雜的社會交流,并預測他人的行動或反應。
如果AI學不會社會理解、get不到人類社會交往的種種規則,也就無法為人類更好地工作,在各種需要推理的任務中為人類提供有價值的見解。

怎么辦呢?
專家發現,通過一種「上下文學習」,就能大大增強LLM的推理能力。
對于大于100B參數的語言模型來說,只要輸入特定的few-shot任務演示,模型性能就顯著增強了。
另外,即使在沒有演示的情況下,只要指示模型一步步思考,也會增強它們的推理性能。
為什么這些prompt技術這么管用?目前還沒有一個理論能夠解釋。
大語言模型參賽選手
基于這個背景,約翰斯·霍普金斯大學的學者評估了一些語言模型在ToM任務的表現,并且探索了它們的表現是否可以通過逐步思考、few-shot學習和思維鏈推理等方法來提高。
比特幣全網算力回升至100EH/s上方:據glassnode數據,比特幣的昨日全網算力回升至100 EH/s上方,報101.51EH/s。[2021/7/7 0:33:22]
參賽選手分別是來自OpenAI家族最新的四個GPT模型——GPT-4以及GPT-3.5的三個變體,Davinci-2、Davinci-3和GPT-3.5-Turbo。
·Davinci-2是在人類寫的演示上進行監督微調訓練的。
·Davinci-3是Davinci-2的升級版,它使用近似策略優化的人類反饋強化學習進一步訓練。
·GPT-3.5-Turbo,在人寫的演示和RLHF上都進行了微調訓練,然后為對話進一步優化。
·GPT-4是截至2023年4月的最新GPT模型。關于GPT-4的規模和訓練方法的細節很少公布,然而,它似乎經歷了更密集的RLHF訓練,因此與人類意圖更加一致。
實驗設計:人類與模型大OK
如何考察這些模型呢?研究者設計了兩個場景,一個是控制場景,一個是ToM場景。
控制場景指的是一個沒有任何agent的場景,可以把它稱為「Photo場景」。
而ToM場景,描述了參與某種情況的人的心理狀態。
這些場景的問題,在難度上幾乎一樣。

人類
首先接受挑戰的,是人類。
對于每個場景,人類參與者都有18秒的時間。
隨后,在一個新的屏幕上會出現一個問題,人類參與者通過點擊「是」或「否」來回答。
實驗中,Photo和ToM場景是混合的,并以隨機順序呈現。
舉個例子,Photo場景的問題如下——
情景:「一張地圖顯示了一樓的平面圖。昨天給建筑師發了一份復印件,但當時廚房的門被遺漏了。今天早上,廚房門才被添加到地圖上。」
Ethereum 社區在 Reddit 已有超 100 萬訂閱者:Ethereum 社區在 Reddit 上已有超 100 萬訂閱者(builder)。[2021/6/13 23:33:27]
問題:?建筑師的復印件上是否顯示了廚房的門?
ToM場景的問題如下——
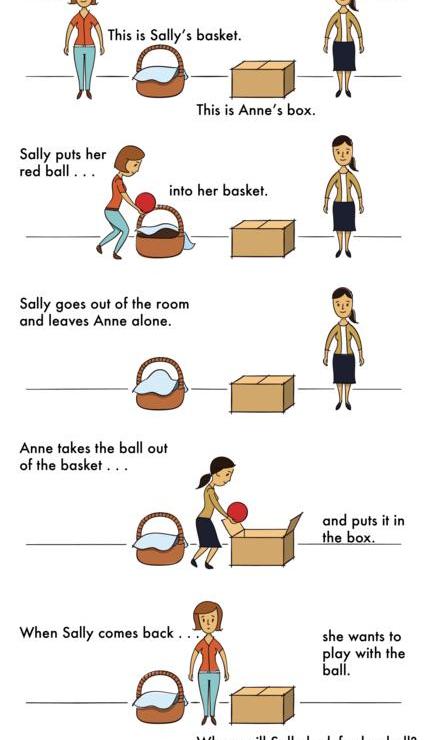
情景:「高中舞會那天早上,Sarah把她的高跟鞋放在裙子下面,然后就去購物了。那天下午,她的姐姐借走了這雙鞋,后來把它們放在了Sarah的床下。」
問題:?當Sarah回來后,她會認為她的鞋子在裙子下面嗎?
測試結果是,人類在Photo場景的準確率為,ToM場景的準確率為。
LLM
因為LLM是個概率模型,因此研究者對每個模型prompt了20次。
問題有16個場景,每個重復20次,因此LLM總共會被問320個問題。怎么定義準確率呢?就是看正確答案占320個問題的比例。
對于高中舞會的問題,如果LLM做出如下回答,都算作正確。
示例1:Sarah去購物前把鞋子放在裙子下面,但她姐姐借了鞋子后放在了Sarah的床底下。Sarah不知道她姐姐借了她的鞋子,所以她可能會認為鞋子還在她的衣服下面。
示例2:Sarah去購物前把她的高跟鞋放在裙子下面,但她姐姐借了鞋子,后來把它們放在了Sarah的床底下。?所以,Sarah不知道她姐姐借了又還了鞋子。?因此,答案是:是的,她會認為她的鞋子在她的衣服下面。
示例3:Sarah可能會認為她的鞋子還在她的裙子下面,因為那是她早上放鞋的地方。
示例4:Sarah去購物前把她的高跟鞋放在裙子下面,這樣她就知道她把鞋子放在哪里了。?她姐姐借了這雙鞋,后來把它們放在Sarah的床底下,但Sarah還不知道。?所以,答案是:是的,Sarah會認為她的鞋子在衣服下面,除非她發現不是這樣。
示例5:早上,Sarah將她的高跟鞋放在裙子下面。?后來,她姐姐借了這雙鞋,把它們放在Sarah的床底下。?因此,當Sarah回來后,她可能會認為她的鞋子還在她的衣服下面,但實際上它們在她的床底下。
1000萬枚USDT自一未知地址轉至幣安:據Whale Alert監測,北京時間14點24分,波場鏈上1000萬枚USDT自一未知地址轉至幣安交易所。[2020/3/19]
示例6:基于這種情況,尚不清楚Sarah在回來時是否會認為她的鞋子在裙子下面。?這要看她姐姐有沒有跟她說借過鞋,并且放在床底下了。
如果LLM做出以下回答,則被判定為錯誤。
示例1:Sarah早上把鞋子放在裙子下面,然后去購物。?她姐姐借了鞋子,把它們放在Sarah的床底下。?所以,Sarah不知道她的鞋子在床下面。?所以,答案是:不,Sarah不認為她的鞋子在她的衣服下面。
示例2:不,Sarah不認為她的鞋子在她的衣服下面。
示例3:首先,Sarah早上把她的高跟鞋放在裙子下面。?然后,她姐姐借了這雙鞋,后來把它們放在了Sarah的床底下。?因此,Sarah不會認為她的鞋子在衣服下面,因為她姐姐動過了。
示例4:早上,Sarah將她的高跟鞋放在裙子下面,然后去購物了。?這意味著,當她回到家時,她并沒有檢查鞋子是否還在衣服下面。?后來,她姐姐借了這雙鞋,把它們放在Sarah的床底下。?因此,Sarah不能認為她的鞋子是在裙子下面,因為它們被她姐姐動過了。
示例5:這個場景中沒有具體說明Sarah是否認為她的鞋子在衣服下面。
示例6:Sarah早上把她的高跟鞋放在裙子下面,然后她去購物了。?她姐姐后來借了這雙鞋,把它們放在Sarah的床底下。?根據這些信息,尚不清楚Sarah在準備跳舞時會不會認為她的鞋子還在裙子下面。
為了衡量上下文學習對ToM表現的效果,研究者采用了四種類型的prompt。
Zero-Shot(無ICL)

Zero-Shot+Step-by-StepThinking

Two-Shot思維鏈推理
動態 | 瑞士加密谷擴建 一年內增加了1000多個工作崗位:1月26日報道,以瑞士楚格州為中心的金融科技友好地區Crypto Valley(加密谷)已擴展到鄰近的列支敦士登地區。去年,在瑞士加密谷建立了近100家新企業,一年增加了1000多個工作崗位。(News.bitcoin)[2020/1/26]

Two-Shot思維鏈推理+Step-by-StepThinking

實驗結果
zero-shot基線
首先,作者比較了模型在Photo和ToM場景中的zero-shot性能。
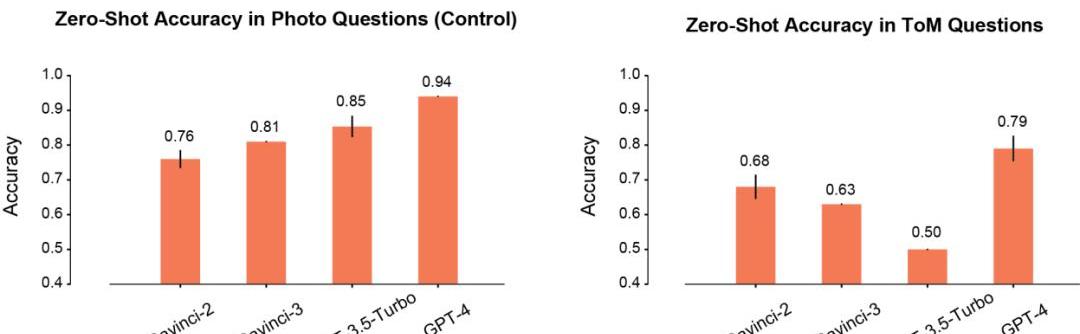
在Photo場景下,模型的準確率會隨著使用時間的延長而逐漸提高。其中Davinci-2的表現最差,GPT-4的表現最好。
與Photo理解相反,ToM問題的準確性并沒有隨著模型的重復使用而單調地提高。但這個結果并不意味著「分數」低的模型推理性能更差。
比如,GPT-3.5Turbo在信息不足的時候,就更加傾向于給出含糊不清的回復。但GPT-4就不會出現這樣的問題,其ToM準確性也明顯高于其他所有模型。
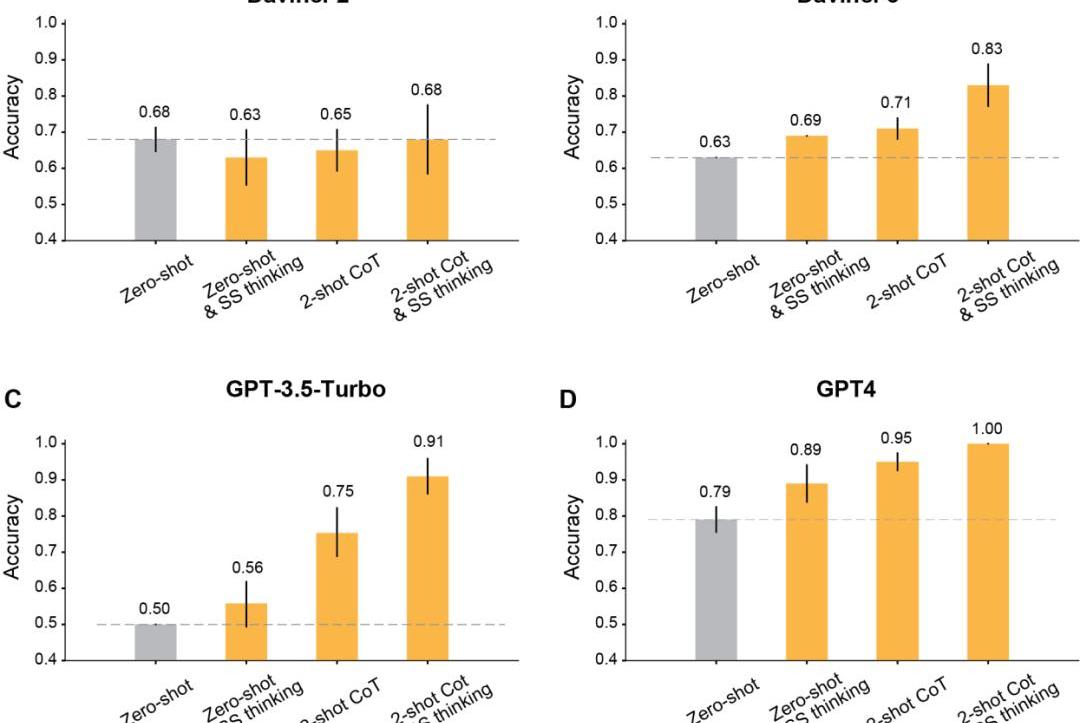
prompt加持之后
作者發現,利用修改后的提示進行上下文學習之后,所有在Davinci-2之后發布的GPT模型,都會有明顯的提升。

首先,是最經典的讓模型一步一步地思考。
結果顯示,這種step-by-step思維提高了Davinci-3、GPT-3.5-Turbo和GPT-4的表現,但沒有提高Davinci-2的準確性。
其次,是采用Two-shot思維鏈進行推理。
結果顯示,Two-shotCoT提高了所有用RLHF訓練的模型的準確性。
對于GPT-3.5-Turbo,Two-shotCoT提示明顯提高了模型的性能,并且比一步一步思考更加有效。對于Davinci-3和GPT-4來說,用Two-shotCoT帶來的提升相對有限。
最后,同時使用Two-shotCoT推理和一步一步地思考。
結果顯示,所有RLHF訓練的模型的ToM準確性都有明顯提高:Davinci-3達到了83%的ToM準確性,GPT-3.5-Turbo達到了91%,而GPT-4達到了100%的最高準確性。
而在這些情況下,人類的表現為87%。
在實驗中,研究者注意到這樣一個問題:LLMToM測試成績的提高,是因為從prompt中復制了推理步驟的原因嗎?
為此,他們嘗試用推理和照片示例進行prompt,但這些上下文示例中的推理模式,和ToM場景中的推理模式并不一樣。
即便如此,模型在ToM場景上的性能也提升了。
由此,研究者得出結論,prompt能夠提升ToM的性能,并不僅僅是因為過度擬合了CoT示例中顯示的特定推理步驟集。
相反,CoT示例似乎調用了一種涉及分步推理的輸出模式,是因為這個原因,才提高了模型對一系列任務的準確性。
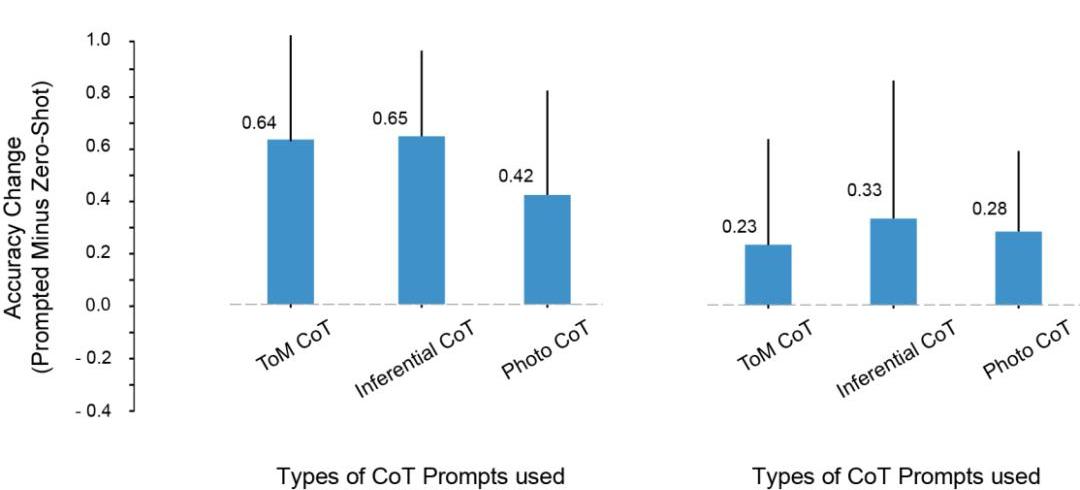
各類CoT實例對ToM性能的影響
LLM還會給人類很多驚喜
在實驗中,研究者發現了一些非常有意思的現象。
1.除了davincin-2之外,所有模型都能夠利用修改后的prompt,來獲得更高的ToM準確率。
而且,當prompt同時結合思維鏈推理和ThinkStep-by-Step,而不是單獨使用兩者時,模型表現出了最大的準確性提升。
2.Davinci-2是唯一一個沒有通過RLHF微調的模型,也是唯一一個沒有通過prompt而提高ToM性能的模型。這表明,有可能正是RLHF,使得模型能夠在這種設置中利用上下文提示。
3.LLM可能具有執行ToM推理的能力,但在沒有適當的上下文或prompt的情況下,它們無法表現出這種能力。而在思維鏈和逐步提示的幫助下,davincin-3和GPT-3.5-Turbo,都有了高于GPT-4零樣本ToM精度的表現。

另外,此前就有許多學者對于這種評估LLM推理能力的指標有過異議。
因為這些研究主要依賴于單詞補全或多項選擇題來衡量大模型的能力,然而這種評估方法可能無法捕捉到LLM所能進行的ToM推理的復雜性。ToM推理是一種復雜的行為,即使由人類推理,也可能涉及多個步驟。
因此,在應對任務時,LLM可能會從產生較長的答案中受益。
原因有兩個:首先,當模型輸出較長時,我們可以更公平地評估它。LLM有時會生成「糾正」,然后額外提到其他可能性,這些可能性會導致它得出一個不確定的總結。另外,模型可能對某種情況的潛在結果有一定程度的信息,但這可能不足以讓它得出正確的結論。
其次,當給模型機會和線索,讓它們系統性地一步一步反應時,LLM可能會解鎖新的推理能力,或者讓推理能力增強。
最后,研究者也總結了工作中的一些不足。

比如,在GPT-3.5模型中,有時推理是正確的,但模型無法整合這種推理來得出正確的結論。所以未來的研究應該擴展對方法(如RLHF)的研究,幫助LLM在給定先驗推理步驟的情況下,得出正確結論。
另外,在目前的研究中,并沒有定量分析每個模型的失效模式。每個模型如何失敗?為什么失敗?這個過程中的細節,都需要更多的探究和理解。
還有,研究數據并沒有談到LLM是否擁有與心理狀態的結構化邏輯模型相對應的「心理能力」。但數據確實表明,向LLM詢問ToM的問題時,如果尋求一個簡單的是/否的答案,不會有成果。
好在,這些結果表明,LLM的行為是高度復雜和上下文敏感的,也向我們展示了,該如何在某些形式的社會推理中幫助LLM。
所以,我們需要通過細致的調查來表征大模型的認知能力,而不是條件反射般地應用現有的認知本體論。
總之,隨著AI變得越來越強大,人類也需要拓展自己的想象力,去認識它們的能力和工作方式。
參考資料:
https://arxiv.org/abs/2304.11490
Tags:SARSARAARATOMSARCO價格samsaranetworkAmara FinanceCryptomall
作者:北辰 上周在《Sui是下一輪的行業敘事or上一輪的末日余暉?》的文章中的觀點引發的討論比較多,本來想用一篇文章來「小心求證」,但發現是給自己挖了一個大坑,后面才是慢慢填坑的時候.
1900/1/1 0:00:00原文來源:FilecoinNetwork 對我們的工程團隊來說,這是一次重要的發布日。生態里的工程團隊在FilecoinWebServices?項目上來到了一個重要的里程碑——這次?FWS?發布.
1900/1/1 0:00:00美聯儲周三如期宣布加息25個基點,這是美聯儲自2022年3月以來的第10次加息,也是自2007年以來首次將聯邦基準利率上調至5%-5.25%的區間.
1900/1/1 0:00:00原文作者:StaderEthereum原文編譯:深潮TechFlow代幣化保險庫,作為一種新興的數字資產管理方式,已經在以太坊上得到廣泛應用.
1900/1/1 0:00:00原文:SuiWorld 目前確定上線Sui的交易平臺以及交易形式 1)OKX 官網鏈接:https://www.okx.com/OKX將于5月3日20:10上線SUI,其中開盤采用集合競價.
1900/1/1 0:00:00原文來源:SuiWorld千呼萬喚始出來,?5月3日晚,SuiNetwork如約上線主網,在之前的文章中,SuiWorld總結了關于SuiNetwork主網上線不得不關注的問題.
1900/1/1 0:00:00


