






 BTC/HKD+2.43%
BTC/HKD+2.43% ETH/HKD+5.49%
ETH/HKD+5.49% LTC/HKD+1.67%
LTC/HKD+1.67% DOT/HKD+6.19%
DOT/HKD+6.19% ADA/HKD+7.03%
ADA/HKD+7.03% SOL/HKD+4.51%
SOL/HKD+4.51% XRP/HKD+4.45%
XRP/HKD+4.45% DOGE/US+4.74%
DOGE/US+4.74% 
圖片來源:由無界版圖AI工具生成
3月2日,OpenAI正式開放了ChatGPT的API接口,開發人員可以將ChatGPT模型集成到他們的應用程序和產品中。ChatGPTAPI調用的價格以Token計算,0.002美元可以獲得1000Token,1000個Token約等750個單詞。這個價格比ChatGPT剛剛開放測試時大幅下降,OpenAI官方稱,12月以來,OpenAI為ChatGPT降低了90%的成本。
與ChatGPT一同開放API的還有OpenAI的語音轉文字模型Whisper,如果開發人員把這兩個模型結合起來應用到自己的App中,沒準也能造出一個鋼鐵俠的“賈維斯”。
與科技行業大環境的停滯與衰退不同,AI產業正在逆流而上,關于ChatGPT和通用AI大模型的討論一浪接著一浪,現在幾乎每周都會有幾條關于生成式AI以及AI大模型的熱點新聞。
在加密貨幣頻頻暴雷后,風險投資領域太需要一個刺激神經的技術了。
2月28日,百度官宣了將在3月16日召開發布會,公開自己的類ChatGPT產品“文心一言”。在此之前,Meta也宣布將開源一個用于科研的大模型系列LLaMA。
在微軟高調把ChatGPT推到NewBing的臺前后,硅谷巨頭們就開始緊鑼密鼓地推動大模型研究,谷歌僅用兩個月就發布了類似ChatGPT的Bard。
在這方面,中國并不落后。2023年2月起,百度、阿里、騰訊、京東、字節等紛紛發聲表示自己在大模型領域已經開展了深入研究,且獲得了很多成果。一時間,追逐大模型成了國內AI行業的標準動作,“大練模型到煉大模型”的過度期似乎已經接近尾聲,下一階段大有“全民大模型,ChatGPT進萬家”的架勢。
不過,AI技術研發不是誰都能做的,需要真正的專家。硅谷巨頭之所以能在大模型領域迅速反應,一方面因為他們在這條賽道上有多年的技術積累,更重要的是他們在AI研究方面有著大量的人才儲備。
谷歌的人工智能研究團隊一直處在全球領先地位,旗下還有與OpenAI齊名的實驗室DeepMind;另一家科技巨頭Meta則有被稱為卷積神經網絡之父的圖靈獎得主YannLeCun以首席AI科學家的身份坐鎮。
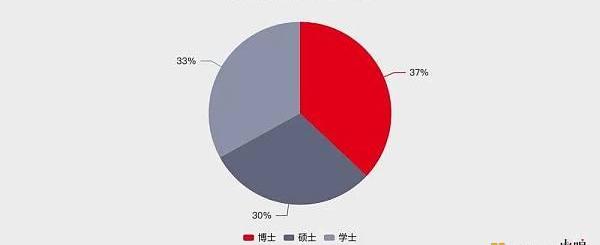
微軟手下的急先鋒OpenAI,也是基于強大的科研團隊才奠定的領先地位。科技情報分析機構AMiner和智譜研究發布的《ChatGPT團隊背景研究報告》顯示,OpenAI的ChatGPT研發團隊中,27人為本科學歷,25人為碩士學歷,28人為博士研學歷(注:5人信息缺失),占比分別為33%、30%、37%。
動態 | IBM與韓國信用卡公司合作 改善人工智能和區塊鏈技術的應用:據bitcoinexchangeguide消息,日前,IBM宣布與韓國信用卡公司現代信用卡(Hyundai Card )合作。官方表示,本次合作的目的是將改善人工智能和區塊鏈技術在現代公司中的應用。[2019/2/14]
ChatGPT團隊學歷分布
而另一份來自獵聘大數據的國內AI人才市場調查則顯示:近一年,預訓練模型、對話機器人和AIGC三個ChatGPT相關領域中,國內企業明確要求本科以上學歷的職位分別占71.33%、82.30%、92.53%;要求碩、博士學歷的占比分別為16.49%、9.86%、18.22%。
對比ChatGPT團隊,國內AI人才的平均水平差距較大,碩博比例明顯不足。而在今天這種大家齊上大模型賽道的“加速”發展態勢下,要在短時間里“大干快上”,勢必要先比試比試誰的團隊技術實力強,誰更能在自己的麾下聚攏一批大模型人才。
搶人大作戰
技術大戰開打之前,各家的大模型團隊先得打贏一場關鍵的人才爭奪戰。
如果你是一個清華博士,有5-10年NLP行業經驗,那么你的資料只要出現在招聘平臺上,不需要任何詳細履歷,就可以在注冊完成后的48小時內,接到多家獵頭公司的詢問電話,以及數十條HR、獵頭、業務經歷甚至BOSS本人發來的站內信息。在這些信息中,不乏阿里、美團、小紅書等大廠,還有諸多創業公司,以及研究機構。獵頭們提供的NLP算法研究員崗位年薪也大多會在百萬元上下。
根據獵聘大數據調查,過去五年,人工智能和互聯網的招聘薪資均處于上漲態勢,人工智能年均招聘薪資明顯高出互聯網。2022年,人工智能招聘平均年薪為33.15萬元,比互聯網高出4.27萬元,即14.78%。
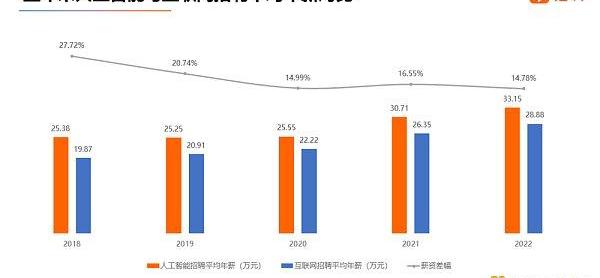
五年來人工智能與互聯網招聘平均年薪對比
在ChatGPT爆火后,這樣的情況越來越明顯。據上述調查顯示,與ChatGPT相關的崗位工資均超過平均水平,AIGC為39.08萬,對話機器人為34.89萬,預訓練模型為33.93萬。“ChatGPT一火起來,AI工程師的薪資水平也越來越高,你不開高價就搶不到人。”某AI領域投資人對虎嗅說。
從技術的角度看,大模型發端于NLP領域,自然語言處理崗位在人工智能領域一直都處于人才稀缺的狀態,薪酬水平處于高位。科銳國際調研咨詢業務負責人&高科技領域資深專家景曉平對虎嗅表示,“人工智能行業典型崗位按產業鏈劃分,技術層和基礎層薪酬水平處于高位,高于互聯網其他領域薪酬水平,應用層和互聯網常規崗位薪酬一致。”
事實上,近年來國內AI人才的碩博占比也在逐年提升,很多企業對AI領域的人才要求學歷至少是碩士。薪酬結構則與企業的性質密切相關,國有企業、研究所的薪酬主要是固定薪酬、項目獎金和津貼,例如,國內第一梯隊的AI實驗室,清華大學計算機系自然語言處理與社會人文計算實驗室掛在官網上的博士后招聘待遇為年薪30萬,享受清華大學教職工社會保險、住房公積金等待遇。提供公寓或每年4.2萬的租房補貼,同時可以解決子女入園、入學。
聲音 | 美的集團副總裁:區塊鏈、人工智能、大數據、等數據在融合的過程中:美的集團副總裁兼CIO張小懿稱,“從整個業態的發展來看,無論國內國外,現在工業互聯網大家都在持續不斷投入和探索的過程,人工智能、大數據、區塊鏈這些所有的數據的融合,大家都在融合的過程中。讓工業互聯網能夠真正的聯動人與萬物,感知美好世界。 ”[2018/10/21]
IT大廠和AI創業公司的薪酬結構則多為,固定薪資+浮動獎金+股權期權激勵。在獵聘、脈脈、BOSS直聘三個平臺搜索ChatGPT,碩博學歷職位的月薪普遍高于3萬,最高達9萬。“在薪酬方面IT大廠并不會占多少便宜,AI大模型的研發都是高舉高打,創業公司給出的薪酬可能更有競爭力。”西湖心辰COO俞佳認為,沒有資金支持很難在大模型的基礎訓練領域推動一家初創公司,對于這個領域來說,錢的問題可能“不是最大的問題”。
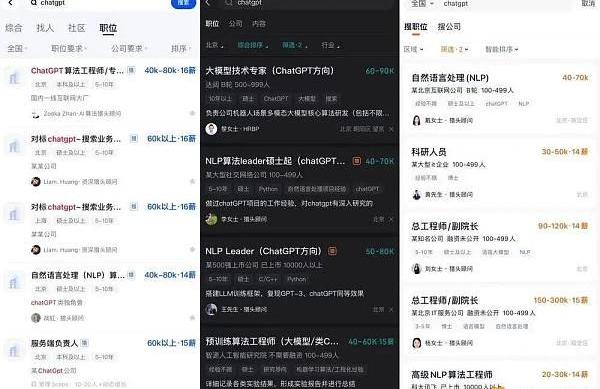
獵聘、脈脈、BOSS直聘,搜索ChatGPT的前排結果
此外,在諸多崗位信息中,工作地點集中在北京、上海、杭州和深圳,但其中一些職位也并不限制辦公地。景曉平表示,目前國內AI人才北京占據第一位,上海、廣東省分列二三位,近些年互聯網發展極為活躍的浙江省,在人工智能發展上也絲毫不落風頭,成都作為科技新秀城市,有優質相關生源的地域,也儲備了不少人工智能人才。但從需求總量來看,國內AI人才還有很大缺口。
OpenAI的專家團隊為何強
OpenAI官網掛出的參與過ChatGPT的項目團隊共87人,該團隊平均年齡為32歲,其中90后是主力軍。
《ChatGPT團隊背景研究報告》顯示,ChatGPT研發團隊絕大多數成員擁有名校學歷,成員最集中的前5大高校是:斯坦福大學、加州大學伯克利分校、麻省理工學院、劍橋大學、哈佛大學和佐治亞理工學院。
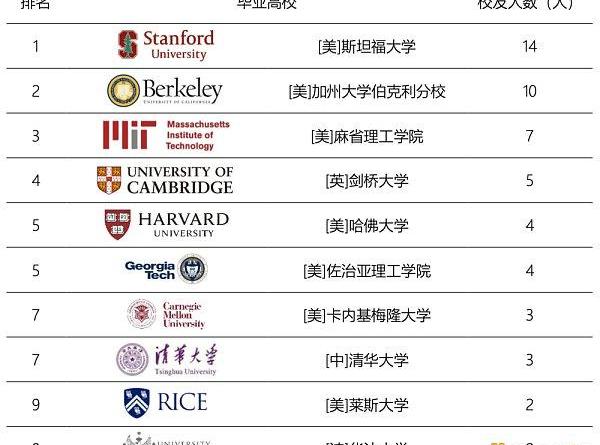
ChatGPT團隊成員畢業前10名高校
此外,很多成員都有名企工作經歷,包括:Facebook、Stripe、Uber、Quora、NVIDIA、Microsoft、Dropbox、DeepMind、Apple、Intel等公司,其中有10人來自谷歌,OpenAI的首席科學家IlyaSutskever亦是從谷歌轉會而來,IlyaSutskever是AlphaGo的作者之一,師從人工智能學界泰斗GeoffreyHinton。
聲音 | MATRIX首席人工智能科學家:區塊鏈和AI結合會創造更高層次的智能:近日中本聰團隊見面會上,主持人對話MATRIXAI首席人工智能科學家鄧仰東先生,請他介紹比特幣與人工智能的關系,鄧先生表示,區塊鏈和AI結合會創造更高層次的智能。
鄧仰東表示:“比特幣和人工智能兩個概念之間有內在本質的聯系。比特幣最大的作用是數據可信性,上面的數據可以相信的,可以交易的。比特幣給AI提供非常好的數據來源。
在共識基礎上的合作機制使大家有充足動機,將資源共享,之后可以拿來做更多的計算,這樣,比特幣給AI提供共享資源計算平臺。
另一方面,AI對于區塊鏈也有幫助,區塊鏈需要參數優化,目前區塊鏈需要處理的參數復雜,數量巨大,AI對優化參數起到很大的作用。”[2018/7/4]
ChatGPT團隊成員流動示意圖
1985年出生在蘇聯的IlyaSutskever,如今已經是英國皇家學會院士。據說IlyaSutskever退出谷歌,與SamAltman、ElonMusk等人一起創立OpenAI時,年薪曾大幅縮水。但他參與創立OpenAI的初衷是“確保強大的人工智能造福全人類”的大義和情懷。
OpenAI初創之時是一家非營利研究機構,從這點上來看,無論是否帶著情懷加入這家公司的研究人員,還是給“非營利”事業燒錢的投資人,多少都有一點對技術的“信仰”,這種驅動力,可能是錢買不來的。
不過OpenAI給這些科技精英們提供的薪酬待遇并不低。據紐約時報報道,2016年,OpenAI向IlyaSutskever支付了超過190萬美元。另一位行業大佬級的研究員IanGoodfellow2016年從OpenAI得到的報酬則超過80萬美元,而他在這一年中只工作了9個月,不過IanGoodfellow在OpenAI沒有待很長時間就離開了。
一直以來,硅谷的AI研究員都是高收入人群。在谷歌發布的官方招聘信息中,在美國工作的全職“高級軟件工程師,大型語言模型,應用機器學習”崗位基本工資范圍為年薪17.4萬-27.6萬美元+獎金+股權+福利。
這份工作的主要職責是:為谷歌大型語言模型的關鍵沖刺做出貢獻,將尖端的LLM引入下一代谷歌產品和應用程序,以及外部用戶。在建模技術方面進行協作,以支持全方位的LLM調整,從提示工程、指令調整、基于人類反饋的強化學習?(RLHF)、參數高效調整到微調。
微軟研究院的研究員崗位“博士后研究員-機器學習和強化學習”年薪則在9.4萬-18.2萬美元。工作職責是“與其他研究人員合作制定自己的研究議程,推動有效的基礎、基礎和應用研究計劃。”
ChatGPT團隊中另一個有意思的點是團隊中有9位華人成員,其中5人本科畢業于國內高校,美國學界對人才的虹吸效應也正是硅谷巨頭以及“OpenAI”們強大人才競爭力的基礎。
“中國的AI人才是從14億人里挑,美國是從80億人里挑,全世界優秀的人很多都到美國去了。”圖靈聯合創始人、原智源研究院副院長劉江表示,要承認差距確實存在,不過他也表示,“在這方面,我們也不用氣餒。中國也有自己的優勢,比如市場化、產品化的能力,近年來我們不比美國同行差了。”
2018中發高論壇將于3月24至26日舉行,將針對人工智能、區塊鏈等熱點議題進行討論:經國務院批準,由國務院發展研究中心主辦的中國發展高層論壇2018年會,將于2018年3月24日至26日在北京釣魚臺國賓館舉行。本屆論壇主題是“新時代的中國”。國務院發展研究中心主任李偉擔任論壇主席,蘋果公司首席執行官蒂姆·庫克擔任外方主席。參會嘉賓將在經濟峰會上就改革開放四十周年、新時代的中美關系、一帶一路、人工智能、區塊鏈等熱點議題展開交流。[2018/3/21]
國內大廠的實力如何?
除了人才問題,國內大模型研究落后美國另一個原因是在生成式AI和大模型研究方面起步略晚,而起步晚的原因,則還是與“錢”脫不開關系。
從技術角度看,生成式技術在StableDiffusion和ChatGPT等網紅產品出現之前,技術實現的效果并不理想,且需要消耗大量算力進行研究。所以大廠、資本很難斥以重資,投入到這種看上去不太賺錢,還要燒錢的業務。
中國的AI產業更注重應用場景,而非基礎理論和技術創新。各家大廠在NLP的理解方面有很多成熟業務,比如聽寫、翻譯,在視覺識別和AI大數據處理方面也有很多應用場景。所以這部分業務自然是AI研發的主力,一方面他們賺錢,另一方面在這些領域的技術積累,使研究人員能夠“在規定跑道上賽跑”,而不是在未知領域探路。
這一點不只是限制了國內公司,更是很多全球巨頭的創新桎梏。正如諾基亞做不出iPhone一樣,巨頭都不喜歡“破壞式創新”,谷歌發布的Bard只因一個小失誤就牽動了母公司Alphabet的萬億市值,這也正是谷歌一直聲稱不愿發布LaMDA大模型的理由,害怕會因AI的失誤影響自己的商譽。而OpenAI顯然不太在乎ChatGPT在公測中會出什么問題,畢竟他發布ChatGPT時只是一家估值200億美元的獨角獸。
不過,在這波大模型的追趕賽中,國內大廠的團隊也可以說是實力頗強。
百度在大模型方面走的最早,百度自2019年開始研發預訓練模型,先后發布了知識增強文心系列模型。文心大模型研發的帶頭人,百度首席技術官、深度學習技術及應用國家工程研究中心主任王海峰博士,是自然語言處理領域權威國際學術組織ACL的首位華人主席、ACL亞太分會創始主席、ACLFellow,還是IEEEFellow、CAAIFellow及國際歐亞科學院院士。他還兼任中國電子學會、中國中文信息學會、中國工程師聯合體副理事長等。目前,王海峰在國內外期刊會議上發表的學術論文有200余篇,獲得已授權專利170余項。
雖然沒有像百度一樣公布類ChatGPT產品的發布時間表,但騰訊、阿里和華為分別提出的“混元”、“通義”和“盤古”三個大模型,均已研發了很長時間。
據機器學習和自然語言處理著名學者MarekRei教授在2022年4月發布的統計顯示,2012-2021年中,在ML和NLP頂級期刊和會議發表論文數量最多的機構是谷歌,微軟緊隨其后。發文數量最多的中國機構是清華大學,第二是位列第16的騰訊,騰訊也是前32名中唯一的中國互聯網廠商。不過,在2021年單年的統計中,阿里和華為也登上此榜,騰訊仍排在較靠前的位置。
Nexus與SingularityNET合作 通過3D區塊鏈技術探索人工智能:\t據Cryptoninjas消息,Nexus和SingularityNET今天宣布了一項合作,以探索區塊鏈和人工智能技術的結合。SingularityNET正在創建基于區塊鏈的分布式人工智能網絡。這種新的合作關系可能會帶來最安全、可升級、可受審查的區塊鏈人工智能基礎設施。對于SingularityNET,這種合作關系為其人工智能網絡創建了可伸縮性、可訪問性和安全性。這種關系也有助于兩家公司實現各自強大技術的共同目標。對于Nexus來說,該合作關系為部署其3D區塊鏈結構以及在其網絡層面上探索AI應用程序提供了寶貴的用例。[2018/2/7]
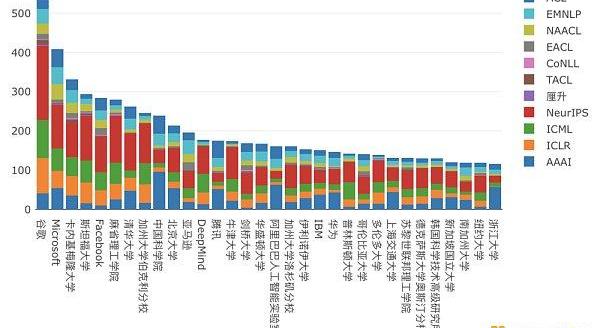
MarekRei發布的2021年ML、NLP頂會、期刊發文量統計
目前,騰訊官方并沒有公布“混元”大模型研發團隊的具體信息。不過,騰訊旗下AI研發團隊“騰訊AILab”的專家構成,也顯示出了騰訊在AI領域的一部分實力。騰訊AILab由100余位AI科學家和超過300名應用工程師組成,帶頭人張正友博士是騰訊首席科學家、騰訊AILab及RoboticsX實驗室主任,騰訊首位17級研究員、杰出科學家。他在美國斯坦福大學發布的2022年度“全球前2%頂尖科學家榜單”中,排名全球“終身科學影響力排行榜”第1002名,中國排名Top10。
阿里在LLM領域的研究主要由阿里巴巴達摩院負責,阿里巴巴集團資深副總裁,阿里云智能CTO、達摩院副院長周靖人主導,他是IEEEFellow,多次擔任VLDB,SIGMOD,ICDE等國際頂級會議程序委員會主編、主席,在頂尖國際期刊和會議上發表論文超百篇,并擁有幾十項技術專利。
華為也未對“類ChatGPT產品”公開表態,但在大模型方面華為亦有“盤古”大模型正在研究。該項目由華為云人工智能領域首席科學家田奇博士領導,他是計算機視覺、多媒體信息檢索專家,IEEEFellow,國際歐亞科學院院士,教育部長江講座教授,國家自然科學基金海外杰青,中國科學院海外評審專家,在國內多所高校任講席教授及客座教授。
在自己組建團隊投入研發的同時,百度、阿里、騰訊、華為等IT大廠,也與中科院計算所自然語言處理研究組、哈爾濱工業大學自然語言處理研究所、中國人民大學高瓴人工智能學院等高校研究有很多的技術合作。
“集中力量辦大事”的科研機構
數據閉環是大模型研發的關鍵,用戶越多,積累時間越長,就意味著可以用于迭代升級的數據和反饋也就越多。
在這方面OpenAI已經利用前兩代的開源GPT模型和GPT-3積累了大量數據。ChatGPT雖然才推出了3個月,但用戶量和訪問量增長速度飛快,這些都為OpenAI在大模型研發方面積累了巨大的先發優勢。
“AI大模型如果落后了,就會面臨卡脖子的風險。”很多AI專家對此都有擔心,由此國內也誕生了一些應對此種局面的非營利性AI科研機構。這些機構多數有高校研究實驗室背景加持,以及地方政策支持,人才聚攏能力非常強勁。
北京智源人工智能研究院是科技部和北京市政府共同支持,聯合北京人工智能領域優勢單位共建的非營利性創新性研發機構。智源研究院理事長張宏江,是美國國家工程院外籍院士,ACMFellow和IEEEFellow,同時也是微軟亞洲研究院的創始人之一。
2021年,智源研究院發布了1.7萬億參數的超大模型“悟道”的1.0和2.0版本,這項工作由100余位科學家共同打造。其中包括清華大學計算機系自然語言處理與社會人文計算實驗室的孫茂松教授,清華大學知識工程研究室的唐杰教授,清華大學交互式人工智能課題組的黃民烈教授。
目前“悟道”大模型已經與OPPO、好未來、淘寶、搜狗、美團等開展了落地合作。在與美團的合作中,大模型給搜索廣告帶來了2.7%的收入增長。
在南方的科技重鎮也有一家相似的研究機構,粵港澳大灣區數字經濟研究院,IDEA研究院是由深圳市政府大力支持的AI研究機構。與智源研究院有一個頗有趣的相似之處,IDEA研究院的創始人沈向洋博士同樣出身微軟亞洲研究院。沈向洋博士是美國國家工程院外籍院士和英國皇家工程院外籍院士,他參與創建了微軟亞洲研究院,擔任院長兼首席科學家,并曾擔任微軟公司全球執行副總裁,主管微軟全球研究院和人工智能產品線,并負責推動公司中長期總體技術戰略及前瞻性研究與開發工作。
IDEA研究院NLP研究中心負責人張家興博士也來自微軟亞洲研究院,他的團隊推出的開源模型“太乙”,據稱在中文文生圖領域可以達到接近StableDiffusion的水平。
目前IDEA研究院正在持續迭代開發的預訓練模型體系“封神榜”,已經開源了6個系列共10個模型,包含4種模型結構,模型參數最大為35億。其中包括:以Encoder結構為主的雙向語言系列模型的二郎神系列;面向醫療領域,擁有35億參數的余元系列;與追一科技聯合開發的新結構大模型周文王系列;以Decoder結構為主的單向語言模型聞仲系列;以Transformer結構為主的編解碼語言模型,主要解決通用任務的大模型燃燈系列;以及主要面向各種糾錯任務的比干系列。
2月20日晚,復旦大學自然語言處理實驗室對媒體宣傳邱錫鵬教授團隊發布了“國內第一個對話式大型語言模型MOSS”,并在公開平臺,邀請公眾參與內測。然而就在外界都等著看MOSS表現如何驚艷之時。MOSS的內測網站卻掛出了一則道歉公告。
目前MOSS的測試網站已經掛出了停止服務的公告。一位AI大模型專家對虎嗅表示,“邱錫鵬的實驗室學術研究的氛圍很濃。雖然這次的MOSS很少有人得到體驗機會,但是從后邊的公告來看,有可能是在工程優化,并發處理等方面的準備還沒有那么充分。”
在近期舉行的2023年世界人工智能開發者先鋒大會上,邱錫鵬教授公開表示,如果優化順利,MOSS計劃在2023年3月底開源。
雖然,沒能成功搶發“國產ChatGPT”,但AI業內人士對邱錫鵬教授團隊仍然給出了肯定的評價,“邱錫鵬教授的團隊比較偏重學術,這和早期的OpenAI在科研心態上是有共性的,非營利性的AI研究機構,沒有那么多功利的考慮。”
創業公司都有“大佬”背書
AI技術屬于計算機科學,雖然計算機技術已發展多年,但AI仍屬于前沿科技,對LLM以及其他通用大模型的研究更是興起不久,仍然需要依靠應用數據,持續迭代升級,不管MOSS是不是因為工程經驗絆了跟頭,要在AI、大模型這些領域實現突破,能推廣到市場中,接地氣的技術和產品才是王道。事實上,目前國內AI行業活躍的實驗室大多已開始嘗試商業化,在市場的磨礪中探索大模型未來的出路。
深言科技
深言科技源自清華大學計算機系自然語言處理與社會人文計算實驗室。THUNLP由清華大學人工智能研究院常務副院長孫茂松,以及劉洋、劉知遠,三位教授帶頭。實驗室在2017年推出的中文詩歌自動生成系統「九歌」則是最有影響的詩歌生成系統之一,「九歌」已經為用戶創作了超過3000萬首詩詞。
孫茂松教授領銜研發的CPM模型是智源研究院的大模型「悟道·文源」的前身,也是國內最成熟的中文生成式大模型之一。深言科技的團隊也是由CPM模型的部分研發團隊成員所組成的,目前該公司產品包括可以根據意思搜索詞語的“WantWords反向詞典”,以及根據意思查詢句子的“WantQuotes據意查句”。
智譜AI
智譜AI的前身是清華大學知識工程研究室,KEG專注研究網絡環境下的知識工程,在知識圖譜、圖神經網絡和認知智能領域已發表一系列國際領先的研究成果。2006年,智譜AI就啟動了科技信息分析引擎ArnetMiner的相關研究,先后獲得了國際頂級會議SIGKDD的十年最佳論文、國家科學進步獎二等獎、北京市發明專利獎一等獎。
2022年8月,由KEG與智譜AI共同研發的千億級模型參數的大規模中英文預訓練語言模型GLM-130B正式發布,其在多個公開評測榜單上超過GPT-3v1。此外,智譜AI還打造了認知大模型平臺,形成AIGC產品矩陣,提供智能API服務。
聆心智能
2月17日,聆心智能宣布完成由無限基金SEEFund領投的Pre-A輪融資。聆心智能的底層技術是超擬人大規模語言模型,基于大模型可控、可配置、可信的核心技術優勢,聆心智能推出“AI烏托邦”,該系統允許用戶快速定制AI角色。
聆心智能由清華大學交互式人工智能課題組(CoAI)黃民烈教授支持。CoAI是清華大學朱小燕教授及黃民烈教授領導的實驗室。2020年,就已經開源了1200萬對話數據和中文對話預訓練模型CDial-GPT。黃民烈教授也曾參與了智源研究院的“悟道”大模型研發。
西湖心辰
西湖心辰背靠西湖大學深度學習實驗室,創始人是西湖大學助理教授、博士生導師藍振忠,主要研究大規模預訓練模型的訓練與應用。藍振忠曾在谷歌擔任研究科學家,也是輕量化大模型ALBERT的第一作者。
西湖大學在人工智能領域的研發實力很強,除了藍振忠博士的深度學習實驗室,西湖大學NLP實驗室,在該領域的研究也非常領先。學術帶頭人張岳博士在MarekRei教授的頂會、期刊發文量統計中,于2012-2021年期間排名全球第四。
“目前國內LLM領域的創業公司相對IT大廠來說主要有兩個優勢,技術和數據。”西湖心辰COO俞佳對虎嗅表示,國內大模型創業公司在技術方面普遍已有多年研究經驗,構筑了一定的技術壁壘,這是很難短期超越的。同時,由于已經推出了相關產品,“數據飛輪”已經轉起來了,這些數據的質量相比互聯網數據質量要高很多,能夠對產品迭代起到很大支撐作用。
對于國內大模型創業公司未來的發展趨勢,俞佳認為可能性很多,“有些公司可能會走出自己的道路,也有的公司可能會像OpenAI一樣與IT大廠開展深度合作,甚至像DeepMind直接并入其中。”
出品|虎嗅科技組
作者|齊健
編輯|陳伊凡
來源:DeFi之道
Tags:GPT人工智能CHAHATGPT Guru人工智能chatGPT下載FLOKICHAIN價格Stripchat代幣有啥用
金色財經報道,Coinbase正著手將去中心化金融(DeFi)應用程序UniSwap和Aave引入Base。一位知情人士表示,Coinbase正在為Base招募很多協議.
1900/1/1 0:00:001.Ordinals會讓比特幣再次變得有趣嗎?NFT生態的一種新的原語Ordinals對于比特幣的發展而言,無疑打開了一扇奧弗頓之窗.
1900/1/1 0:00:003月2日,加密友好銀行SilvergateBank控股公司SilvergateCapitalCorporation宣布推遲向美國證券交易委員會(SEC)提交年度10-K報告.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:484.57億美元 DeFi總市值及前十代幣數據來源:coingecko2、過去24小時去中心化交易所的交易量20.
1900/1/1 0:00:00頭條 ▌知情人士:亞馬遜將于4月24日上線NFT平臺金色財經報道,亞馬遜將于4月24日上線NFT平臺,計劃通過“AmazonDigitalMarketplace”選項卡在亞馬遜網站上提供.
1900/1/1 0:00:00通過和客戶、合作伙伴的交談,筆者有幸從Web3和元宇宙領域的最聰明的頭腦那里學習到了一些經驗。通過這些對話和觀察,希望本文能夠刷新您對Web3和元宇宙行業的認知,以及行業在未來一年內將如何發展給.
1900/1/1 0:00:00


