






 BTC/HKD-0.06%
BTC/HKD-0.06% ETH/HKD-1.07%
ETH/HKD-1.07% LTC/HKD-3.81%
LTC/HKD-3.81% DOT/HKD-0.52%
DOT/HKD-0.52% ADA/HKD-3.17%
ADA/HKD-3.17% SOL/HKD-2.08%
SOL/HKD-2.08% XRP/HKD-2%
XRP/HKD-2% DOGE/US-2.83%
DOGE/US-2.83%原標題:《加密貨幣價格預測:交易,技術和社交情緒指標的深度學習研究》
幣圈深度參與者和holder獲得更高收益,而不是trader,這或許是我們的錯覺,因為加密貨幣資產天然適合種套利高頻機器人交易。
雖然像我們這些有點信仰又不是老炮的散戶韭菜,對交易技術指標有點不屑。但面對幣價波動,我們也不那么佛系,價格漲跌或多或少擾亂我們的情緒。
而對于幣價的預測或感覺,僅憑社交情緒。本文從大量的技術,交易,社交情緒指標通過各種深度學習算法得出的結論是,綜合技術,交易,社交情緒指標的深度學習結果對預測幣價比單一指標要好。而Github和Reddit的基于技術開發人員的情緒指標更具有參考價值。
雖然這不一定正確更不是真理,畢竟深度學習算法和數據都可能有問題。然而這足足30來頁的論文足已令我們恐懼,如今能用到如此高深的算法和有如此開放豐富的數據對加密資產交易預測,我們散戶韭菜如何是好?
也許只有做好個人功課。我們為什么要投資這個項目?我們如何能為項目貢獻?我如何才能不在乎幣價?
Title:OnTechnicalTradingandSocialMediaIndicatorsinCryptocurrencies'PriceClassificationThroughDeepLearning
Author(s):MarcoOrtu,NicolaUras,ClaudioConversano,GiuseppeDestefanis,SilviaBartolucci
URL:http://arxiv.org/abs/2102.08189
摘要
由于加密貨幣市場的高波動性和新機制的存在,預測加密貨幣的價格是一項眾所周知的艱巨任務。在這項工作中,我們重點研究了2017-2020年期間兩種主要加密貨幣以太坊和比特幣。通過比較四種不同的深度學習算法、卷積神經網絡、長短期記憶神經網絡和注意長短期記憶)和三類特征,對價格波動的可預測性進行了綜合分析。特別是,我們考慮將技術指標、交易指標和社交指標作為分類算法的輸入。我們比較了一個僅由技術指標組成的受限模型和一個包括技術、交易和社交媒體指標的非受限模型。結果表明,不受限制的模型優于受限制的模型,即包括交易和社交媒體指標,以及經典的技術變量,使得所有算法的預測精度都有顯著提高。
1簡介
在過去十年中,全球市場見證了加密貨幣交易的興起和指數增長,全球每日市值達數千億美元。
最近的調查顯示,盡管存在價格波動和市場操縱相關的風險,但機構投資者對新加密資產的需求和興趣仍在飆升,原因是這些資產的新特性以及當前金融風暴中潛在的價值上升。
繁榮和蕭條周期往往由網絡效應和更廣泛的市場采用引起,使價格難以高精度預測。關于這一問題有大量文獻,并提出了許多加密貨幣價格預測的定量方法。加密貨幣的波動性、自相關和多重標度效應的快速波動也得到了廣泛的研究,同時也研究了它們對初始硬幣發行的影響。
文獻中逐漸出現的一個重要考慮因素是加密貨幣交易的“社會”的相關性。區塊鏈平臺的底層代碼在Github上以開源方式開發,加密生態系統的最新添加內容在Reddit或Telegram的專業頻道上討論,Twitter提供了一個經常就最新發展進行激烈辯論的平臺。更準確地說,已經證明,情緒指數可以用來預測價格泡沫,而且從Reddit專題討論中提取的情緒與價格相關。
開源開發在塑造加密貨幣的成功和價值方面也扮演著重要的角色。特別是,Bartoluccietal.之前的一項工作表明,從開發人員對Github的評論中提取的情緒時間序列與加密貨幣的回報之間存在格蘭杰因果關系。對于比特幣和以太坊這兩種主要的加密貨幣,還顯示了如何將開發者的情緒時間序列納入預測算法中,從而大大提高預測的準確性。
在本文中,我們使用深度學習方法進一步擴展了以前對價格可預測性的研究,并將重點放在按市值最高的兩種主要加密貨幣,比特幣和以太坊。
我們通過將準時價格預測映射到一個分類問題來預測價格變動:我們的目標是一個具有兩個獨特類別的二元變量,向上和向下的變動,表示價格上漲或下跌。下面我們將比較四種深度學習算法的性能和結果:多層感知器、多變量注意長短時記憶完全卷積網絡、卷積神經網絡和長短時記憶神經網絡。
我們將使用以下類別的指標作為輸入:技術指標,如開盤和收盤價格或成交量,交易指標,如根據價格計算的動量和移動平均線,社交媒體指標,即從Github和Reddit評論中提取的情緒要素。
對于每一個深度學習算法,我們考慮一個按小時和按每天頻率的受限和非受限數據模型。受限模型由比特幣和以太坊的技術變量數據組成。在無限制模型中,我們包含了Github和Reddit的社交媒體指標和技術、交易變量。
在所有四種深度學習算法中,我們都能證明無限制模型優于限制模型。在每小時數據頻率下,將交易和社交媒體指標與經典技術指標結合起來,能提高比特幣和以太坊價格預測的準確性,從限制模式的51-55%提高到非限制模式的67-84%。對于每日頻率分辨率,在以太坊的情況下,使用限制模型實現最精確的分類。相反,對于比特幣而言,僅包括社交媒體指標的無限制模式實現了最高的性能。
在下面的部分中,我們將詳細討論實現的算法和用于評估模型性能的引導驗證技術。
本文的結構如下。在第2節中,我們詳細描述了使用的數據和指標。在第三節中,我們討論了實驗的方法。在第4節中,我們介紹了研究結果及其意義,在第5節中,我們討論了本研究的局限性。最后,在第6節中,我們總結了我們的發現并概述了未來的發展方向。
“華爾街之狼”:正研究如何“大規模”進入加密市場:美國億萬富翁、“華爾街之狼”Carl Icahn表示,正在研究如何“大規模”進入加密市場。 (金十)[2021/5/27 22:48:08]
2數據集:技術和社交媒體指標
本節討論數據集和用于實驗的三類指標。
2.1技術指標
我們以每小時和每天的頻率對比特幣和以太坊價格時間序列進行了分析。我們從加密數據下載web服務中提取的所有可用技術變量,特別是來自Bitfinex.com網站交易數據服務。我們考慮了過去4年,從2017/01/01到2021/01/01,共35,638個小時的觀測值。
在我們的分析中,我們將技術指標分為兩大類:純技術指標和交易指標。技術指標指的是開盤價和收盤價等“直接”的市場數據。交易指標是指移動平均線等衍生指標。
技術指標如下:
收盤價:加密貨幣在交易期間的最后交易價格。
開盤價:加密貨幣在交易期開始時首次交易的價格。
最低:加密貨幣在一個交易周期內交易的最低價格。
最高:加密貨幣在交易期間交易的最高價格。
交易量:完成的加密貨幣交易數量。
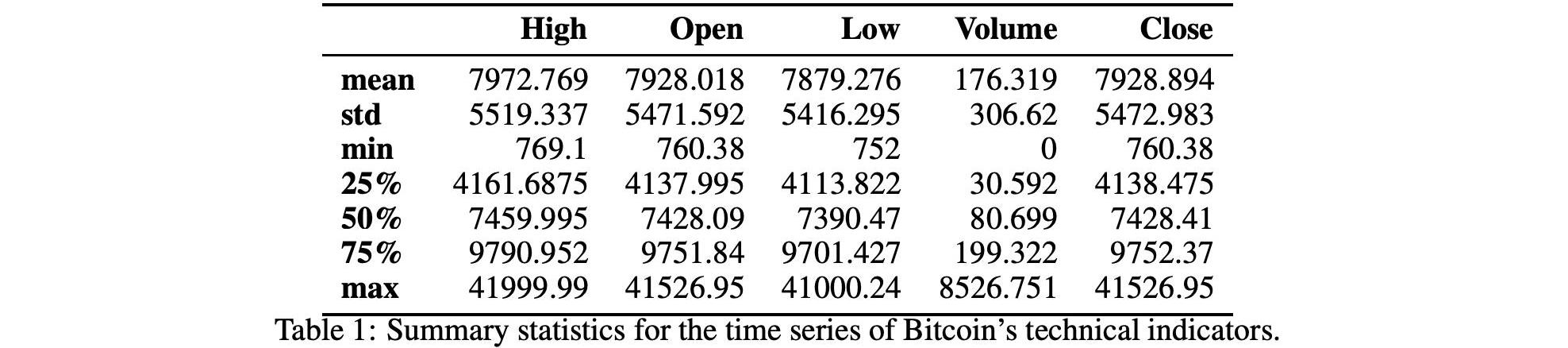
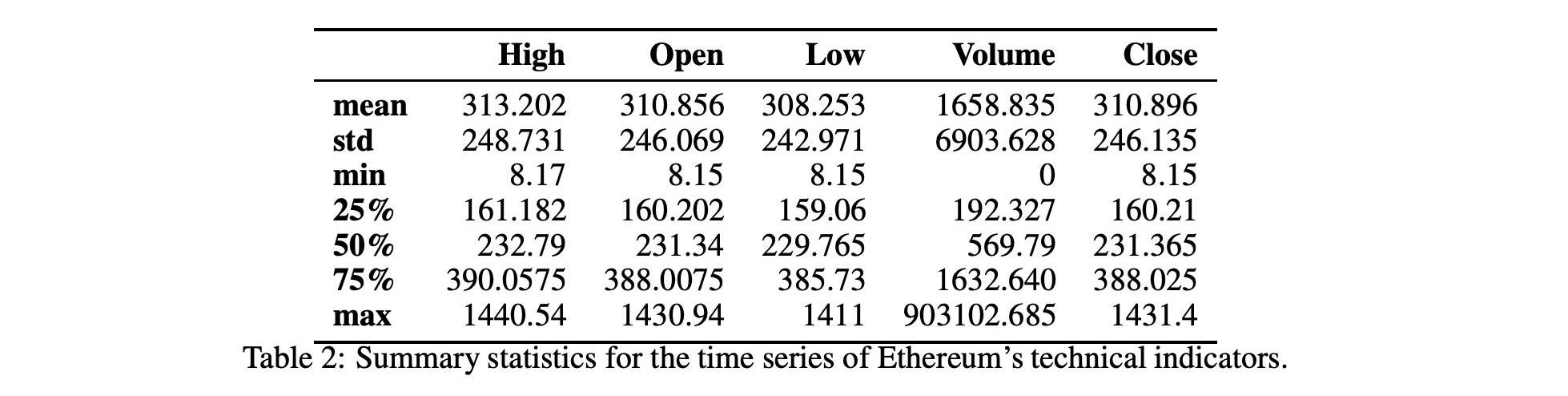
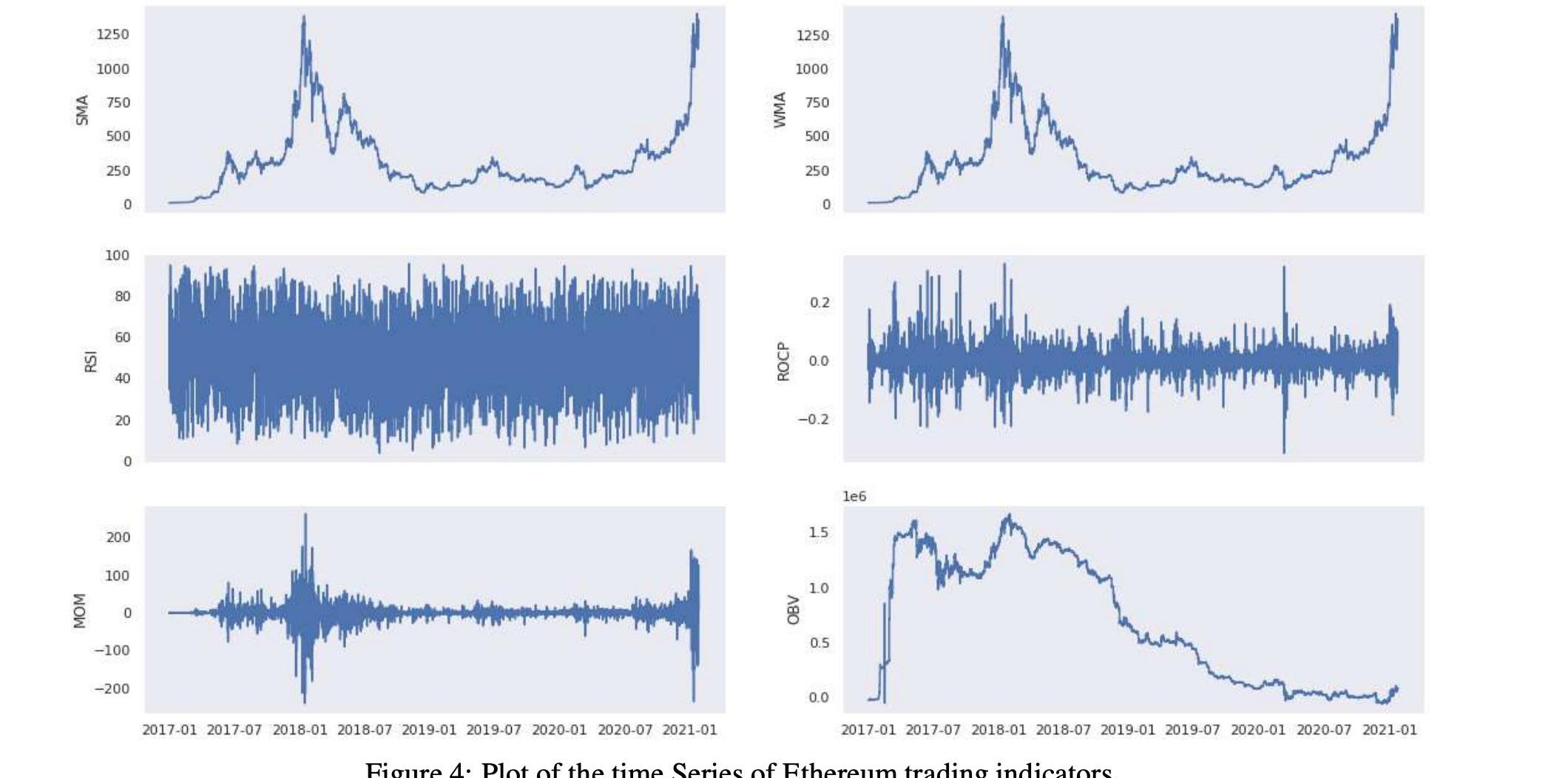
表1和表2顯示了技術指標的匯總統計數字。在圖1和圖2中,我們還顯示了技術指標的歷史時間序列圖。
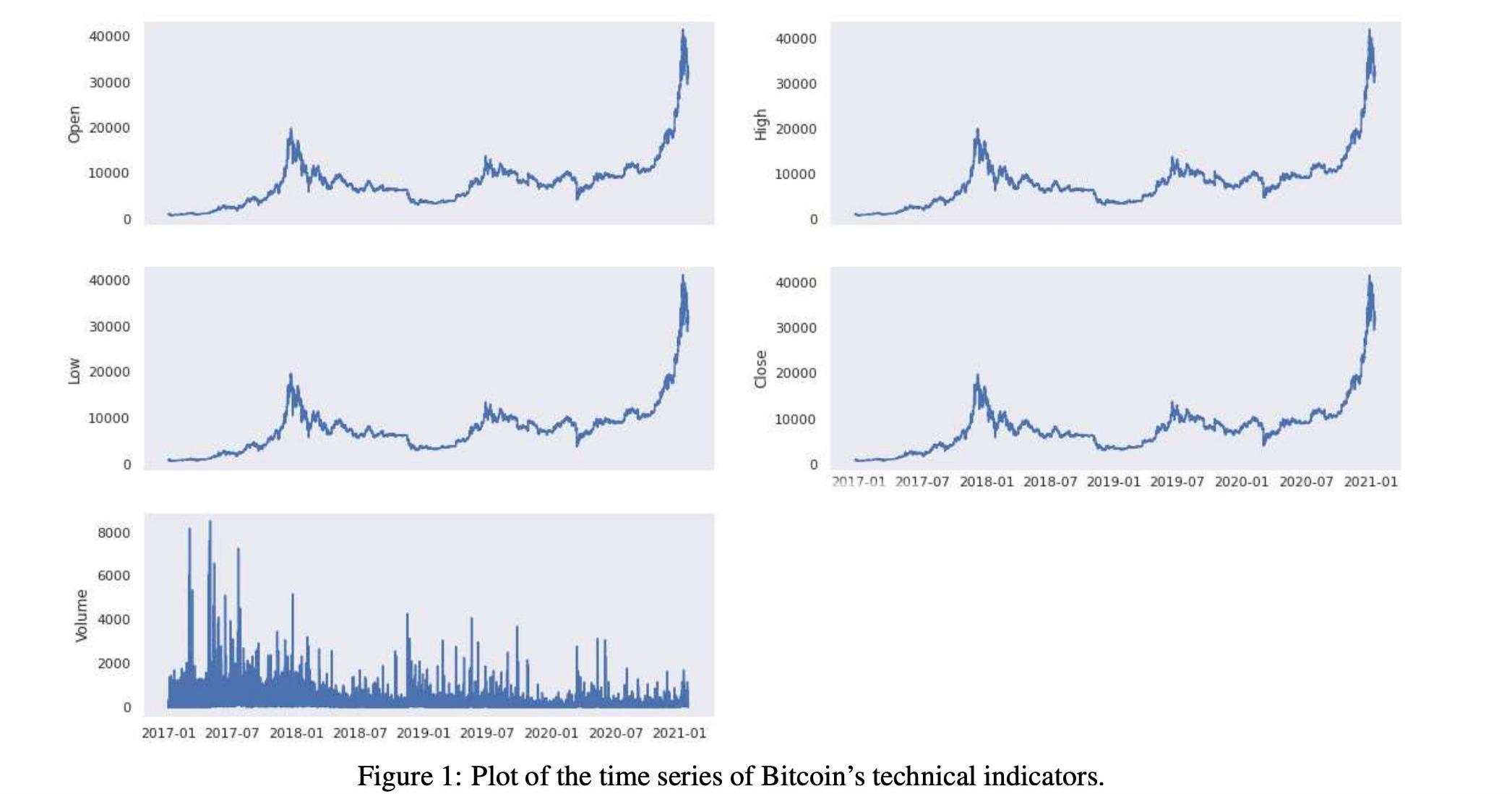
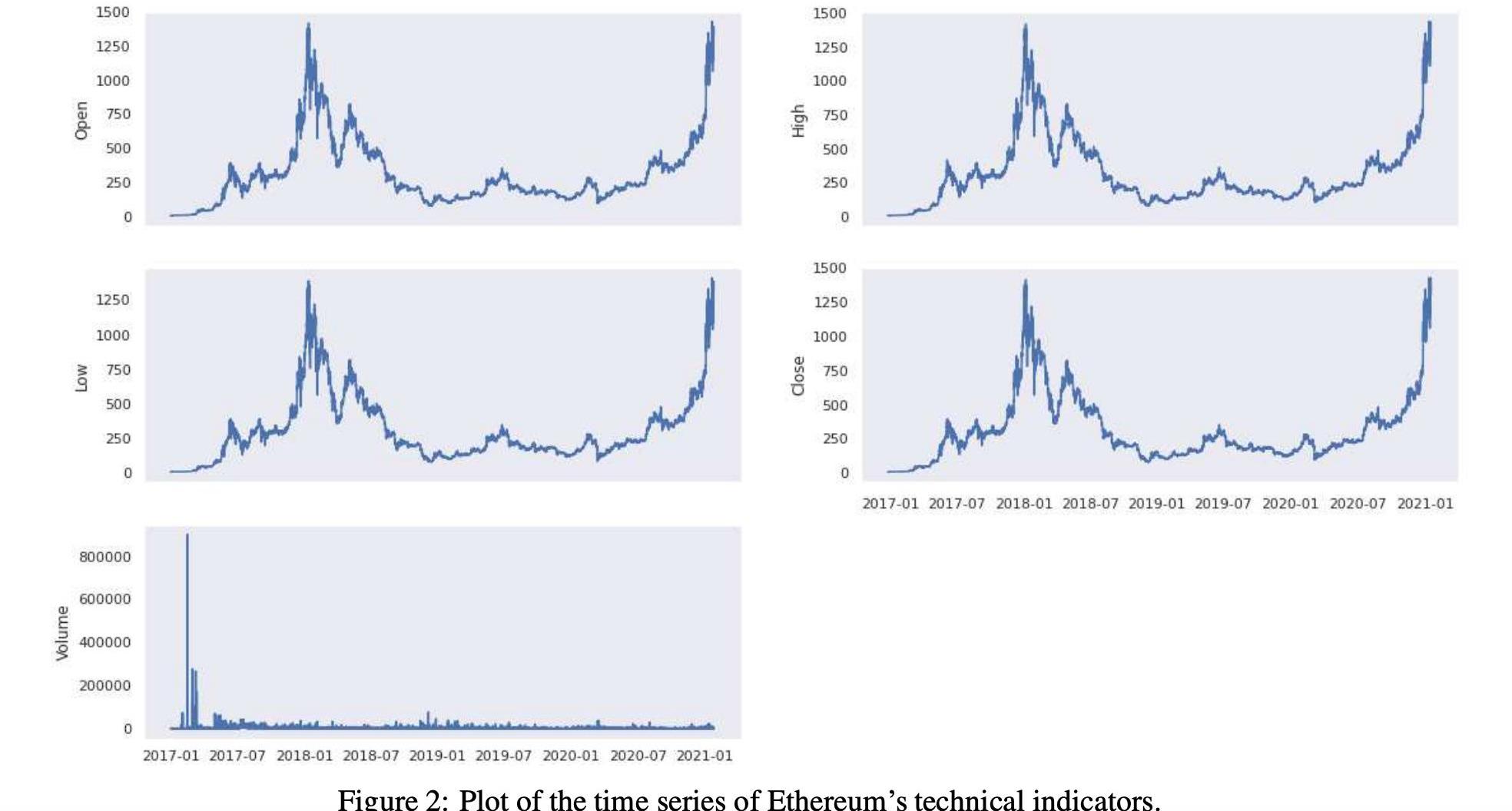
根據對這些技術指標,可以計算交易指標,如移動平均值。更準確地說,我們使用StockStatsPython庫來生成它們。
我們使用了36個不同的交易指標,如表4所示。滯后值表示以前的值用作輸入。窗口大小表示用于在時間t評估指標的先前值的數目,例如,為了計算時間t的ADXRt,我們使用ADXt?1,…,ADXRt?10,十個先前值。
我們在這里提供五個主要交易指標的定義。
簡單移動平均:加密貨幣在某一時期收盤價的算術平均值。
加權移動平均:移動平均計算,為最新的價格數據賦予更高的權重。
相對強度指數:是衡量近期價格變化幅度的動量指標。它通常用于評估股票或其他資產是否超買或超賣。
價格變化率:衡量當前價格與一定時期前價格之間的百分比變化。
動量:是價格的加速率,即價格變化的速度。這一措施對于確定趨勢特別有用。
平衡成交量:是基于資產交易量的技術動量指標,用于預測股價變化。
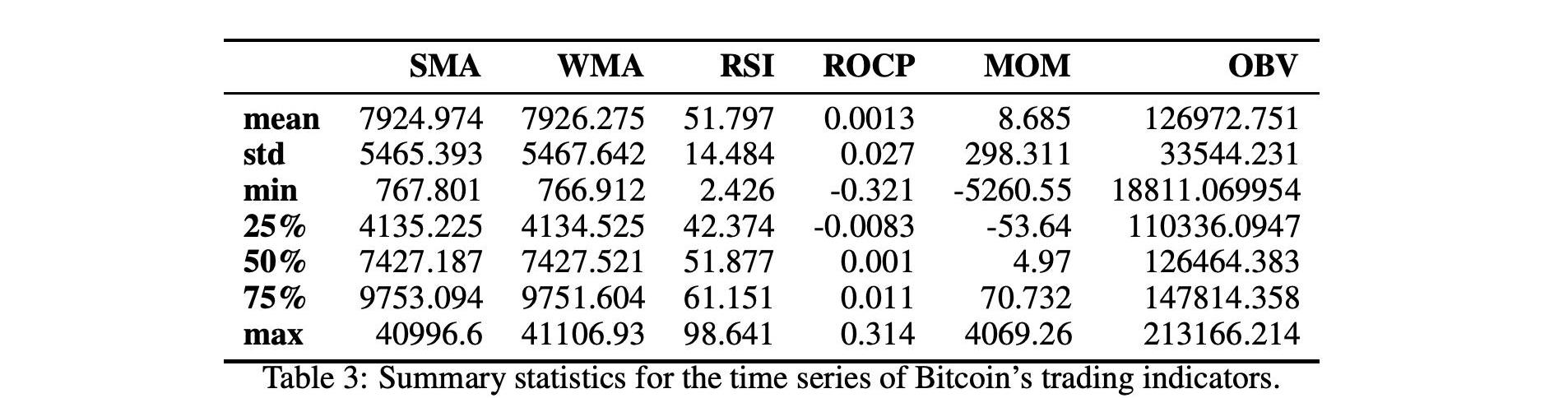
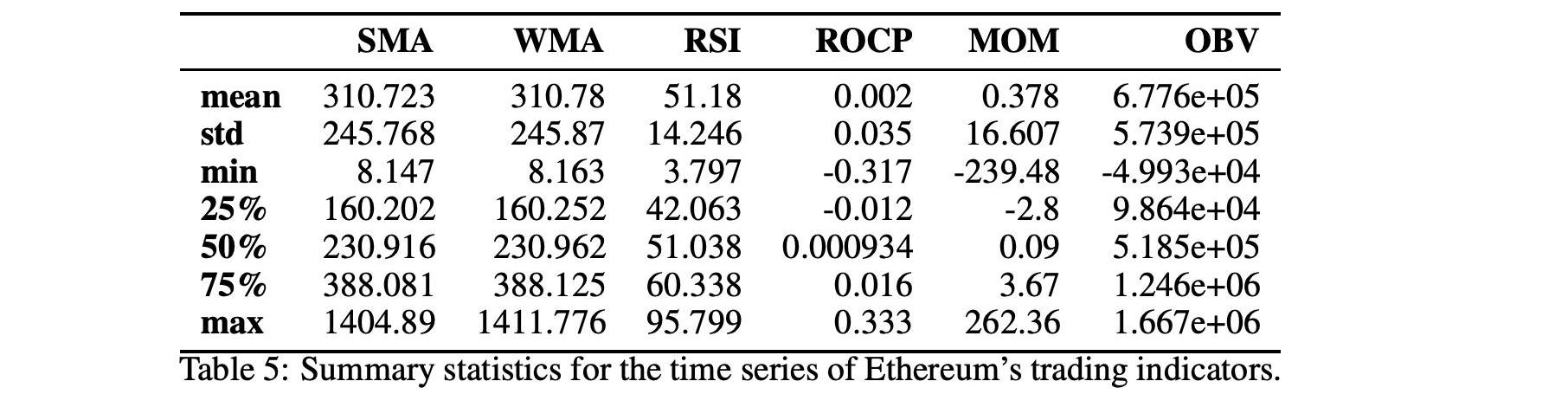
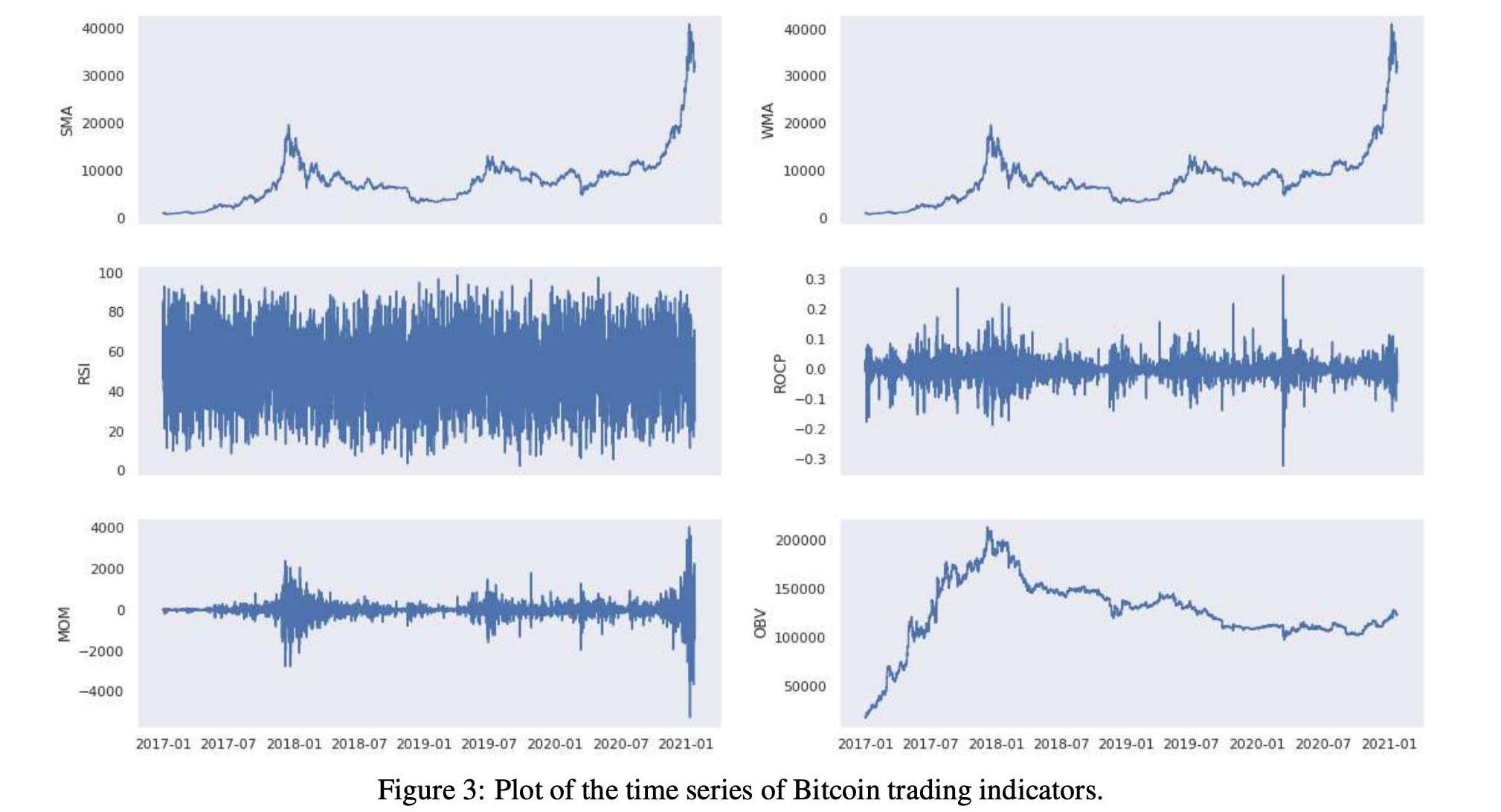
表3和表5顯示了所考慮的分析期間的交易指標統計數字。在圖3和圖4中,我們可以在歷史時間序列圖中看到相同的交易指標。下一節將使用技術和交易指標來創建價格分類模型。

2.2社交媒體指標
本節描述了社交媒體指標的時間序列是如何分別從以太坊和比特幣開發者對Github的評論和用戶對Reddit的評論構建的。特別是,對于Reddit,我們考慮了表6中列出的四個子Reddit通道。考慮的時間段為2017年1月至2021年1月。

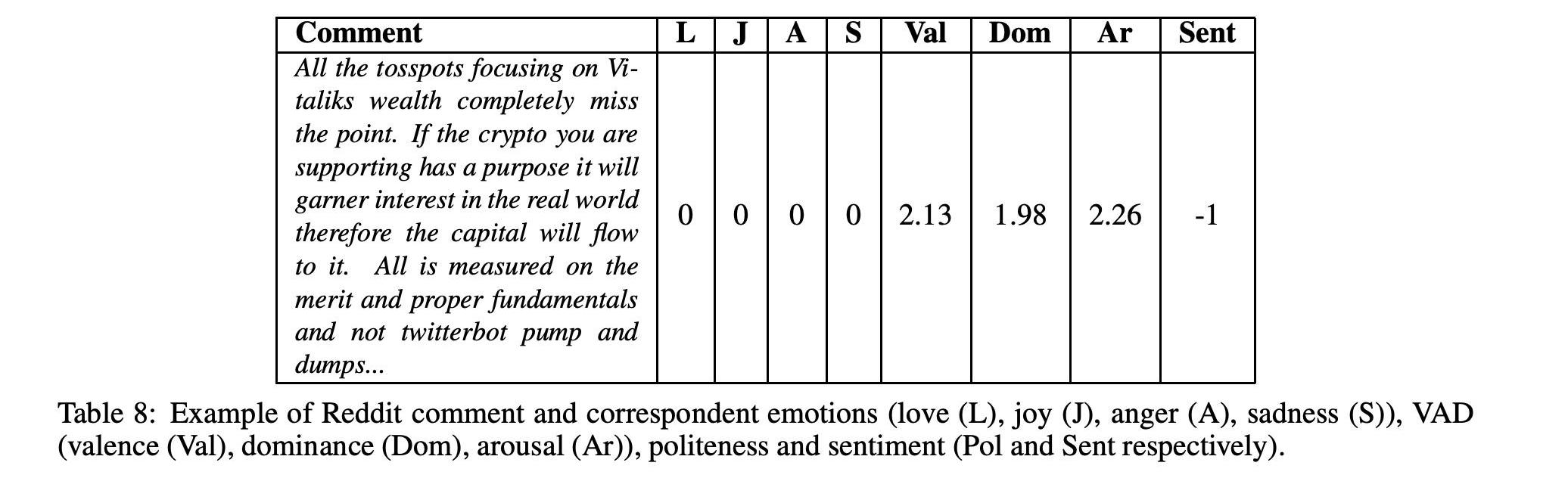
從GithubforEthereum中提取的開發人員注釋和從Redditr/Ethereum中提取的用戶注釋的示例可以在表7和表8中看到。如本例所述,與評論相關的情緒的定量度量是使用最先進的文本分析工具計算的。為每條評論計算的這些社交媒體指標是情感,如愛、快樂、憤怒、悲傷、VAD、支配、喚醒)和情感。

2.3通過深度學習評估社交媒體指標
美國FDA政策藍圖:應研究如何利用區塊鏈跟蹤產品:金色財經報道,美國食品藥品監督管理局(FDA)周一公布了一項針對食品安全的新計劃,在發布的一份政策藍圖中引用了區塊鏈技術在跟蹤產品中的潛在作用。根據該藍圖文件,總體計劃的主要組成部分是使用新興技術來增強現有系統并構建新系統。文件稱,當研究行業如何通過數字方式跟蹤飛機、行程共享和包裝貨物的實時移動,或者企業如何利用大數據來識別趨勢時,很明顯,FDA和利益相關者應該研究如何利用新技術,包括但不限于人工智能、物聯網、傳感器技術和區塊鏈。[2020/7/15]
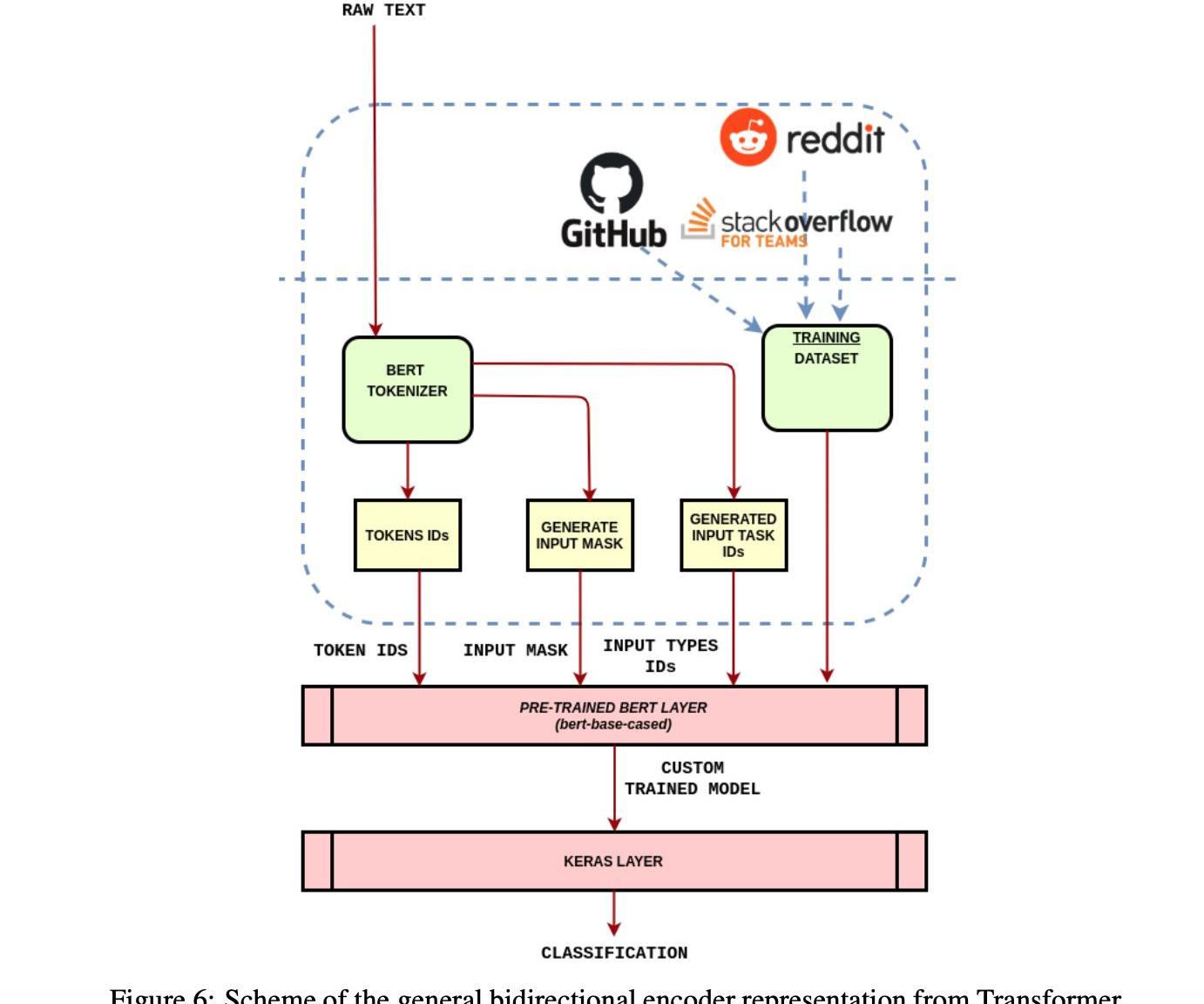
我們使用深度、預訓練的神經網絡從BERT模型中提取社交媒體指標,稱為雙向編碼器表示。BERT和其他轉換器編碼器結構已經成功地運行在自然語言處理中的各種任務,代表了自然語言處理中常用的遞歸神經網絡的發展。他們計算適合在深度學習模型中使用的自然語言的向量空間表示。BERT系列模型使用Transformer編碼器體系結構在所有標記前后的完整上下文中處理輸入文本的每個標記,因此得名:Transformers的雙向編碼器表示。BERT模型通常是在一個大的文本語料庫上進行預訓練,然后針對特定的任務進行微調。這些模型通過使用一個深度的、預先訓練的神經網絡為自然語言提供了密集的向量表示,較換器結構如圖5所示。
轉換器基于注意力機制,RNN單元將輸入編碼到一個隱藏向量ht,直到時間戳t。后者隨后將被傳遞到下一個時間戳。通過使用注意力機制,人們不再試圖將完整的源語句編碼成一個固定長度的向量。相反,在輸出生成的每個步驟中,允許解碼器處理源語句的不同部分。重要的是,我們讓模型根據輸入的句子以及到目前為止它產生了什么來學習要注意什么。
Transformer體系結構允許創建在非常大的數據集上訓練的NLP模型,正如我們在這項工作中所做的那樣。由于預先訓練好的語言模型可以在特定的數據集上進行微調,而無需重新訓練整個網絡,因此在大數據集上訓練這樣的模型是可行的。
通過廣泛的預訓練模型學習的權重,可以在以后的特定任務中重用,只需根據特定的數據集調整權重即可。這將允許我們通過捕獲特定數據集的較低層次的復雜性,利用預先訓練的語言模型通過更精細的權重調整所學到的知識。
我們在Transformer包中使用Tensorflow和KerasPython庫來利用這些預訓練神經網絡的功能。特別地,我們使用了BERT基案例預訓練模型。圖6顯示了用于訓練用于提取社交媒體指標的三個NN分類器的體系結構設計。此圖顯示了用于訓練最終模型的三個gold數據集,即Github、StackOverflow和Reddit。
特別是,我們使用了一個情感標簽數據集,該數據集由從Stackoverflow用戶評論中挖掘出來的4,423條帖子組成,用于訓練Github的情感模型:兩個平臺上的評論都是使用軟件開發人員和工程師的技術術語編寫的。我們還使用了來自Github的4,200個句子的情感標記數據集。最后,我們使用了一個情感標簽數據集,其中包含超過33K個標簽Reddit用戶的評論.
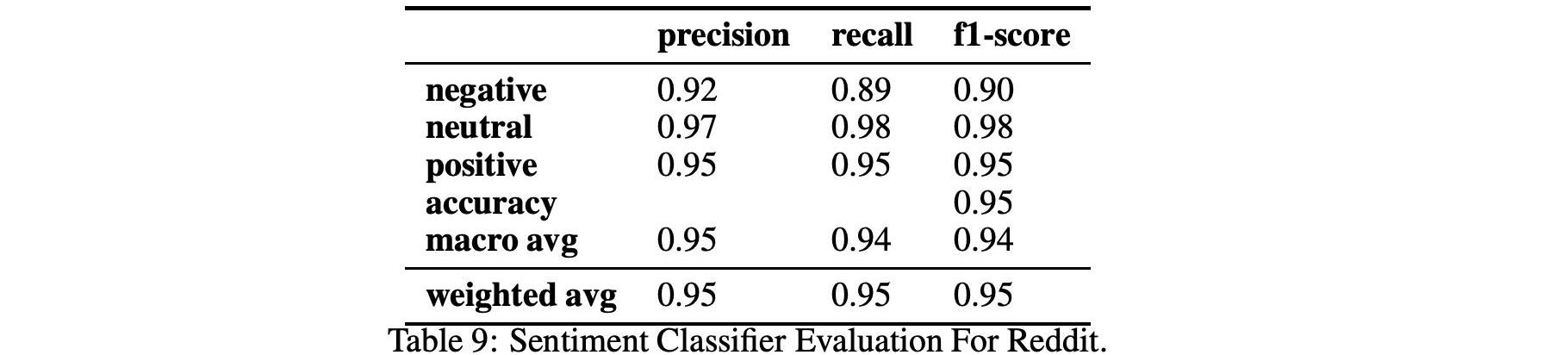
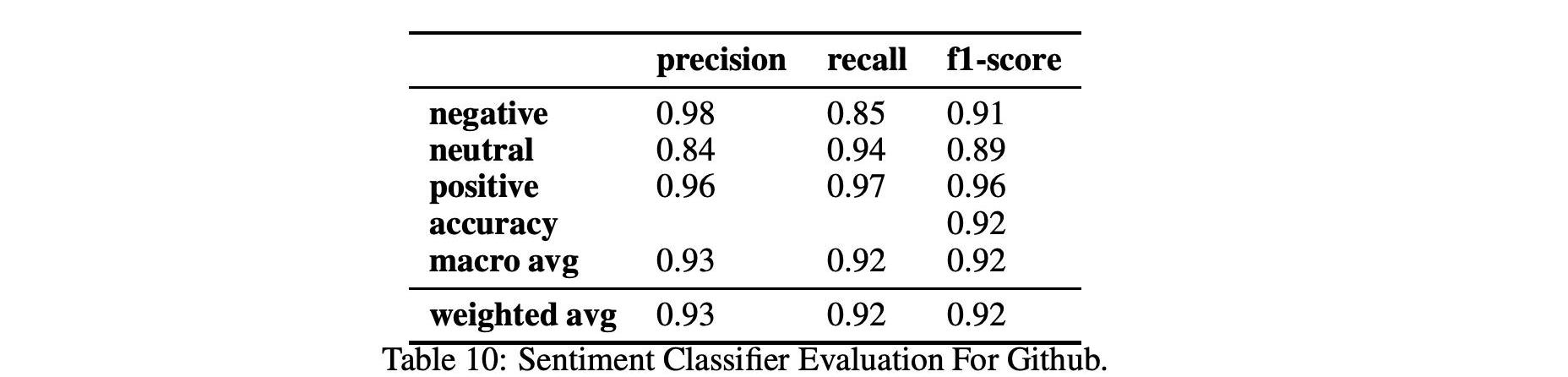
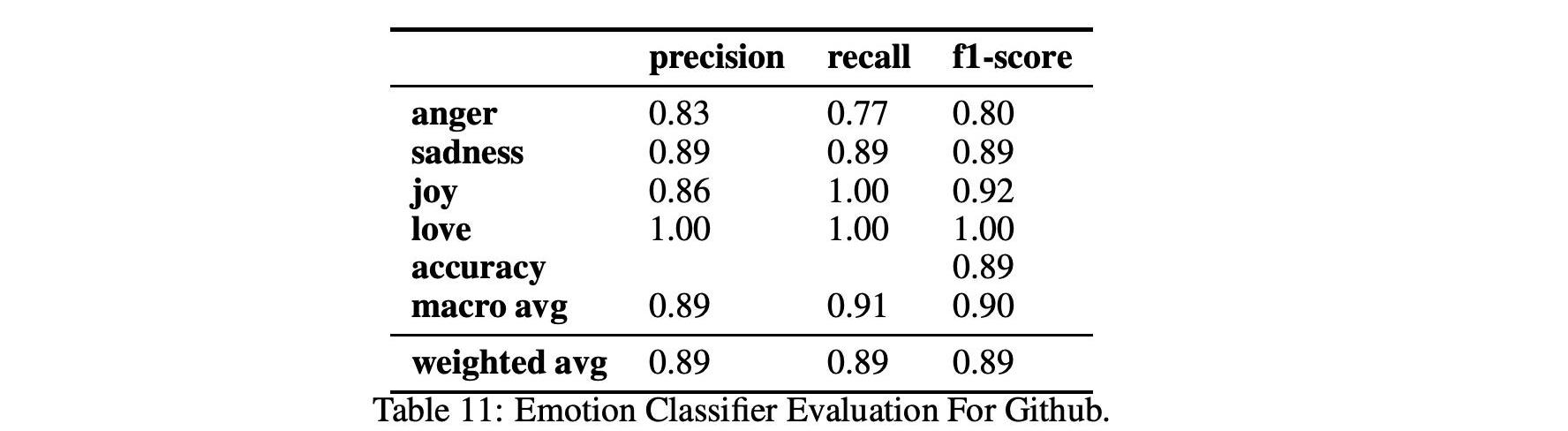
表9、10和11顯示了情緒和情緒分類在兩個不同數據集Github和Reddit上的性能。
2.3.1Github上的社交媒體指標
比特幣和以太坊項目都是開源的,因此代碼和貢獻者之間的所有交互都可以在GitHub上公開獲得。積極的貢獻者不斷地打開、評論和關閉所謂的“問題/issue”。問題是開發過程的一個元素,它包含有關發現的bug的信息、關于代碼中要實現的新功能的建議、新特性或正在開發的新功能。它是跟蹤所有開發過程階段的一種優雅而有效的方法,即使在涉及大量遠程開發人員的復雜和大型項目中也是如此。一個問題可以被“評論”,這意味著開發人員可以圍繞它展開子討論。他們通常會對某一特定問題添加評論,以強調正在采取的行動或就可能的解決方案提出建議。發布在GitHub上的每個評論都有時間戳;因此,可以獲得準確的時間和日期,并為本研究中考慮的每個影響度量生成一個時間序列。
對于情緒分析,我們使用2.3中解釋的BERT分類器,該分類器使用由Ortu等人開發并由Murgia等人擴展的公共Github情感數據集進行訓練。這個數據集特別適合我們的分析,因為情緒分析算法是根據從Apache軟件基金會的Jira問題跟蹤系統中提取的開發人員評論進行訓練的,因此在Github和Reddit的軟件工程領域和上下文中。該分類器可以分析出愛、憤怒、喜悅和悲傷,F1得分接近0.89。
Valence、Arousal、Dominance就是所謂的VAD代表了概念化的情感維度,分別描述了受試者對特定刺激的興趣、警覺性和控制感。在軟件開發的上下文中,VAD度量可以表示開發人員對項目的參與程度,以及他們完成任務的信心和響應能力。Warriner等人創建了一個參考詞典,其中包含14000個英語單詞,其VAD分數可用于訓練分類器,類似于Mantyla等人的方法。在中,他們從70萬份Jira問題報告中提取了VAD指標,其中包含超過200萬條評論,并表明不同類型的問題報告具有情緒變化。相比之下,問題優先級的增加通常會增加Arousal。
歐科集團徐明星對話全國政協委員 談抗擊疫情區塊鏈如何發揮作用:3月20日,全國政協云上“小雙周”座談會今天舉行。全國政協委員,中國證監會原主席肖鋼等多位全國政協委員、業界專家代表出席。會上,歐科集團創始人徐明星發表“區塊鏈+供應鏈抗疫期間‘扛大旗’”主題演講。徐明星表示:“除了供應鏈外,區塊鏈技術在其他領域也有重要應用。隨著下一代高新技術產業的發展,區塊鏈技術將展現出更大的應用潛力。”[2020/3/20]
最后,使用2.3中解釋的BERT分類器和類似研究中使用的公共數據集對情緒進行測量。該算法從正、中性和負三個層次提取短文本中表達的情感極性。
我們的分析主要集中在三類情感指標上:情感、VAD和情感。正如我們在第2.3節中指定的,我們使用定制的工具從每個影響度量類的注釋文本中提取它。
一旦為所有評論計算了影響度量的數值,我們就會考慮評論時間戳來構建相應的社交媒體時間序列。情感時間序列是根據所考慮的時間頻率在每小時和每天聚合多個評論的情感和情緒。
對于給定的社交媒體指標和特定的時間頻率,我們通過平均當天發布的所有評論的影響度量值來構建時間序列。
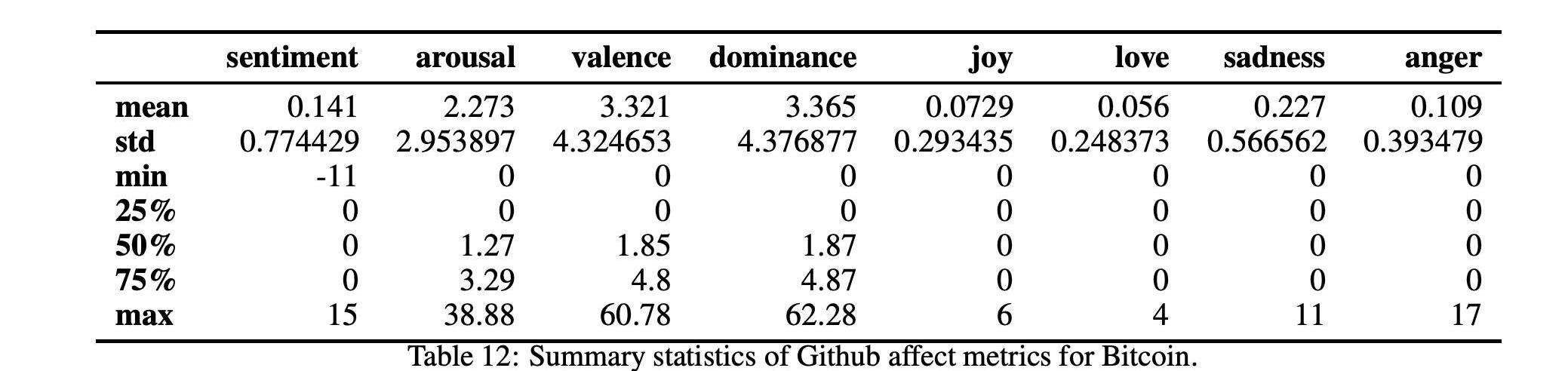
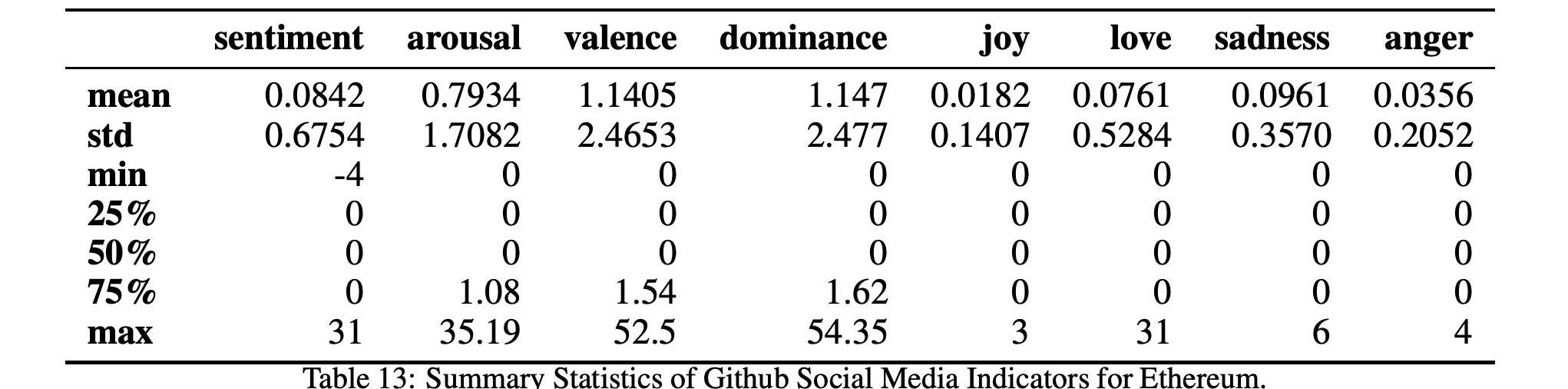
在表12和13中,我們分別詳細報告了兩種加密貨幣的社會指標時間序列的匯總統計數據。我們還在圖7和圖8中分別報告了比特幣和以太坊的所有社交媒體指標的時間序列
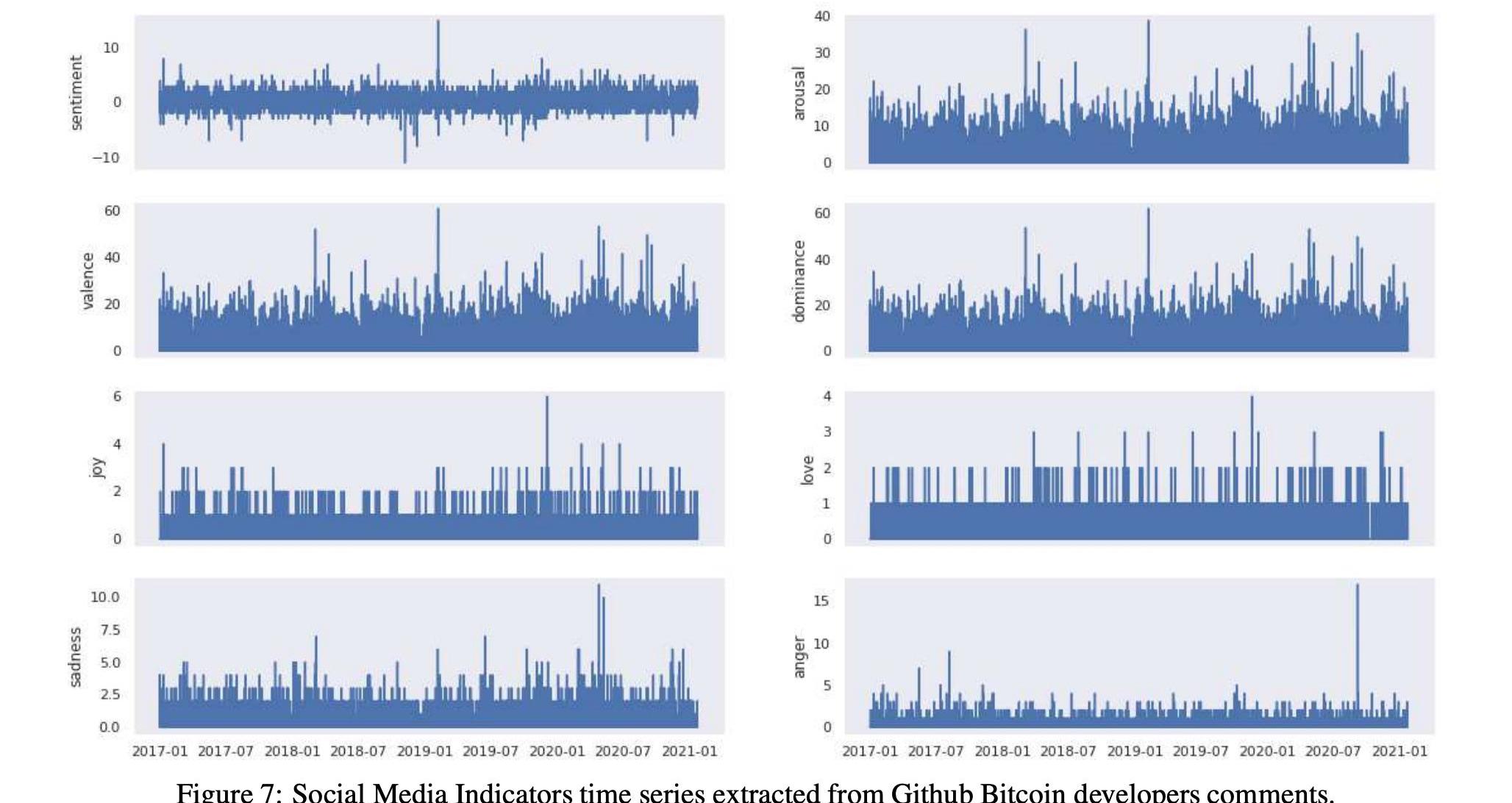
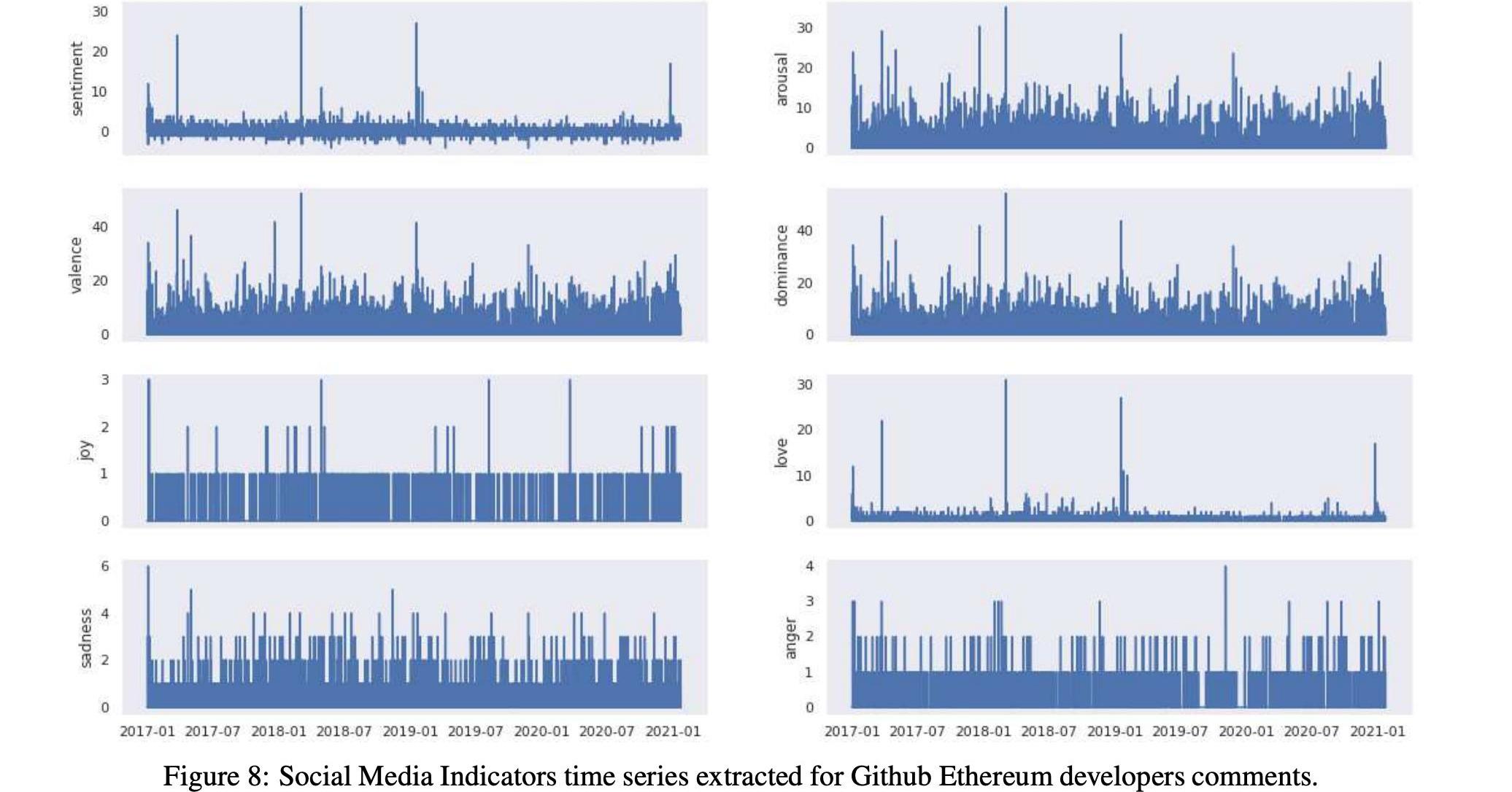
2.3.2測量Reddit的影響度量
社交媒體平臺Reddit是一個美國社交新聞聚合、網絡內容評級和討論網站,每月訪問量約80億次。在英語國家,尤其是加拿大和美國,它是一個最受歡迎的社交網絡。幾乎所有的信息都是用英語寫的,少數是用西班牙語、意大利語、法語和德語寫的。
Reddit構建在多個子Reddit之上,每個子Reddit都致力于討論特定的主題。因此,主要的加密貨幣項目有特定的子項。對于這項工作中的每一種加密貨幣,分析了兩個子項,一個是技術性的,一個是交易相關的。在選項卡中,被考慮的子項。如圖所示,對于每個subreddit,我們收集了從2017年1月到2021年1月的所有評論。
對于情感檢測,我們使用2.3中解釋的BERT分類器,該分類器使用由Ortu等人開發并由Murgia等人擴展的公共Github情感數據集進行訓練。這個數據集特別適合我們的分析,如前一節所述。
該分類器可以檢測出愛、憤怒、喜悅和悲傷,F1得分接近0.89。對于VAD指標,我們使用了2.3.1中相同的方法,而對于情緒,我們使用了之前的方法,即BERT深度學習算法,該算法使用了一個公共黃金數據集進行訓練,用于在最大和知名的共享數據集的web平臺上提供的Reddit評論Kaggle.com.
表14和16以及圖9和11顯示了這兩個比特幣子Reddits的統計數據和時間序列,
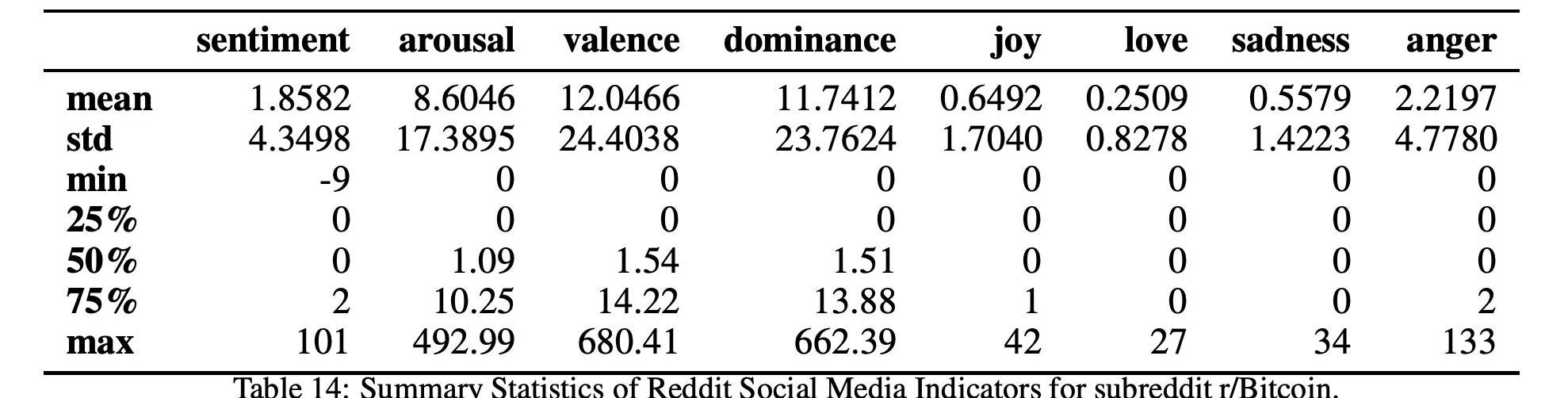
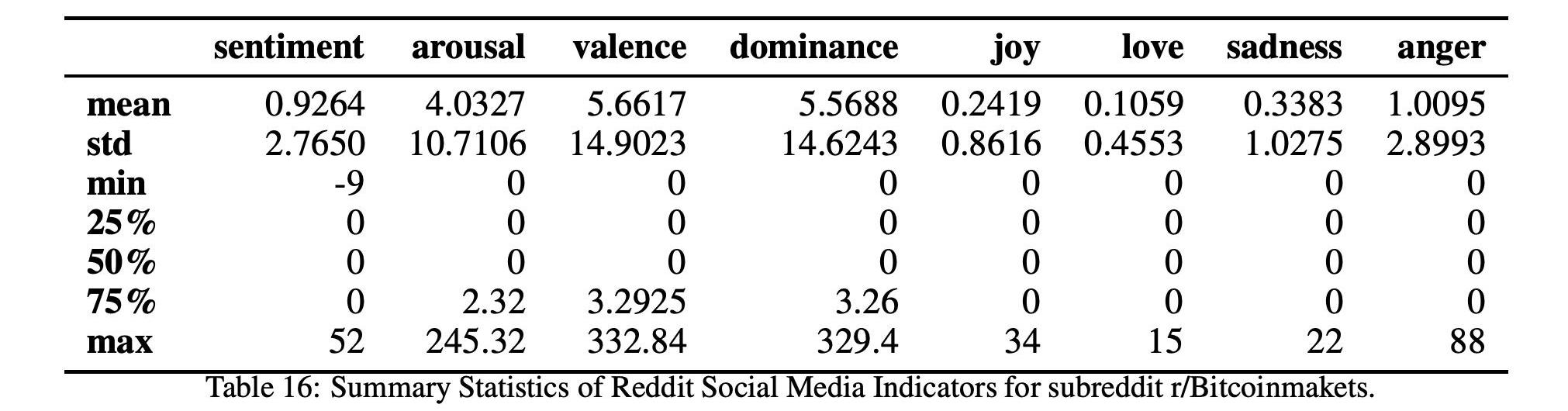
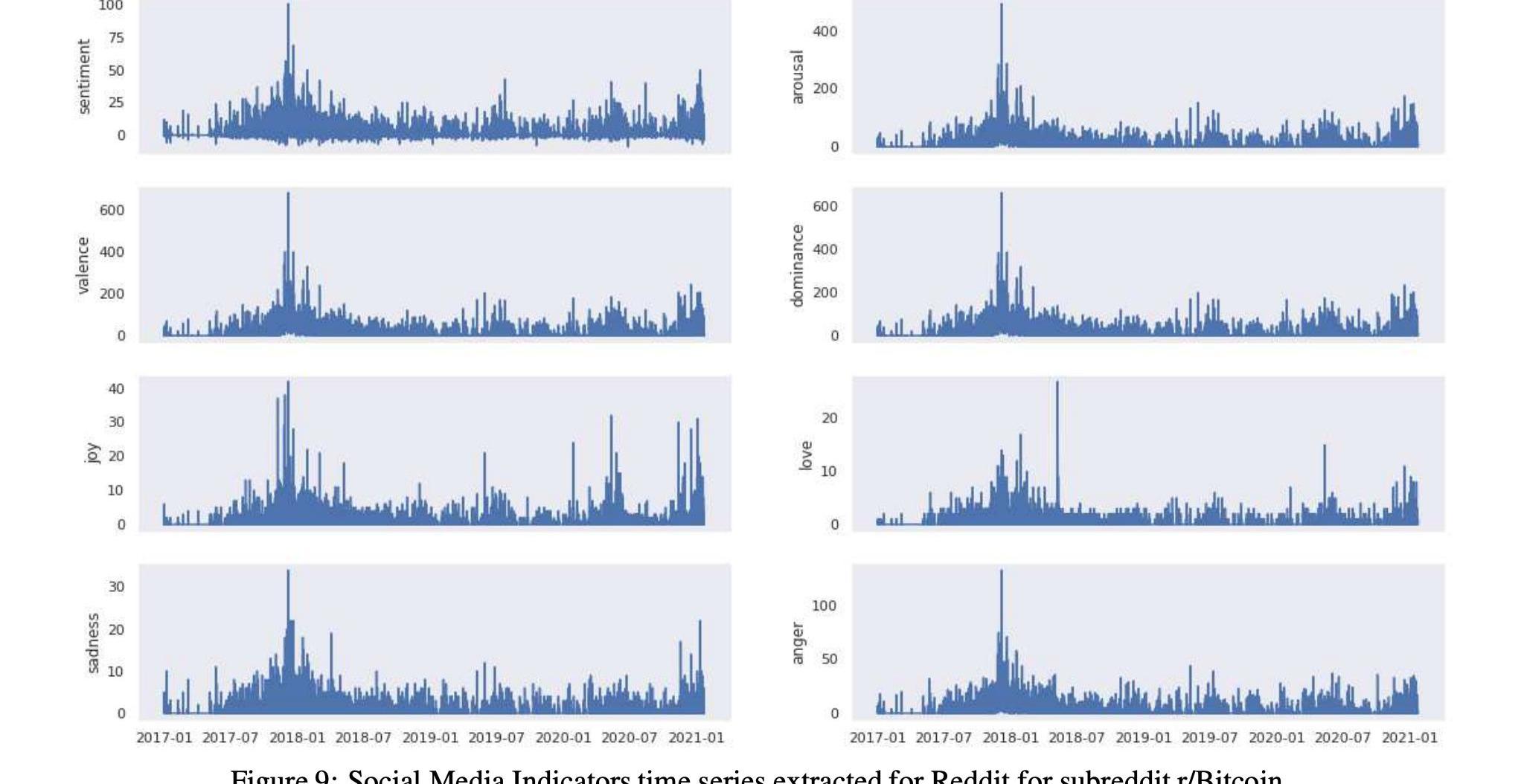
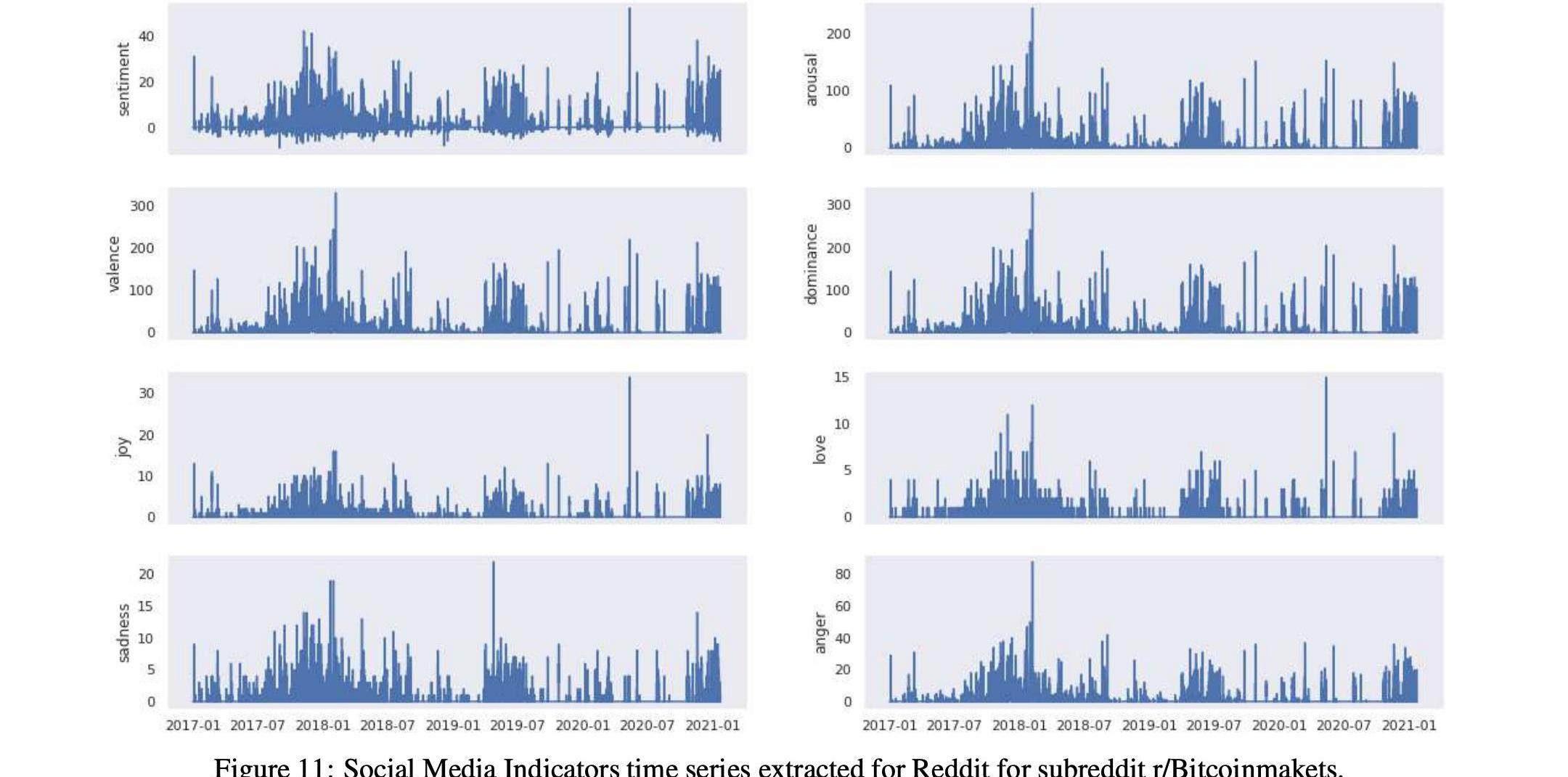
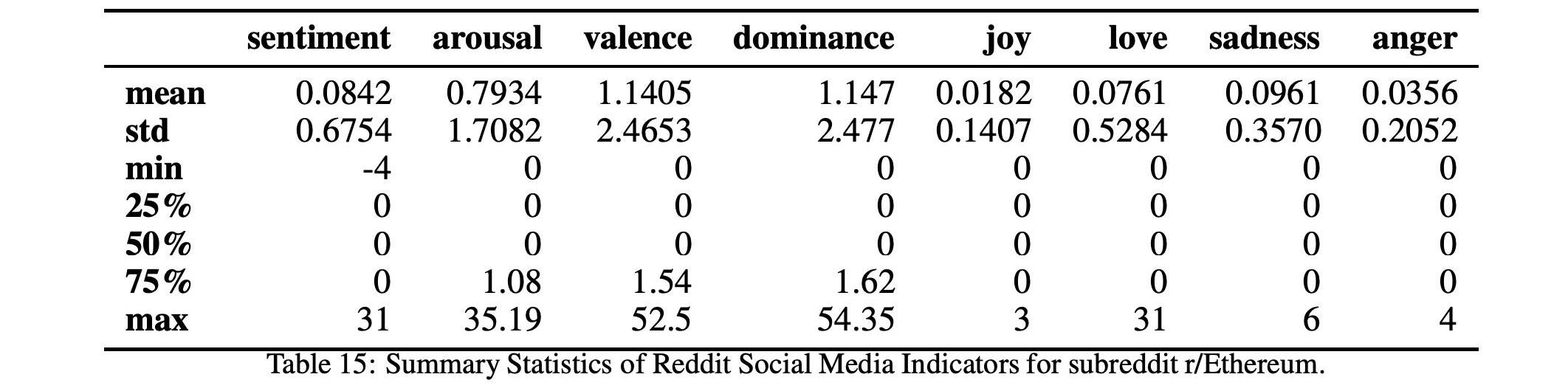
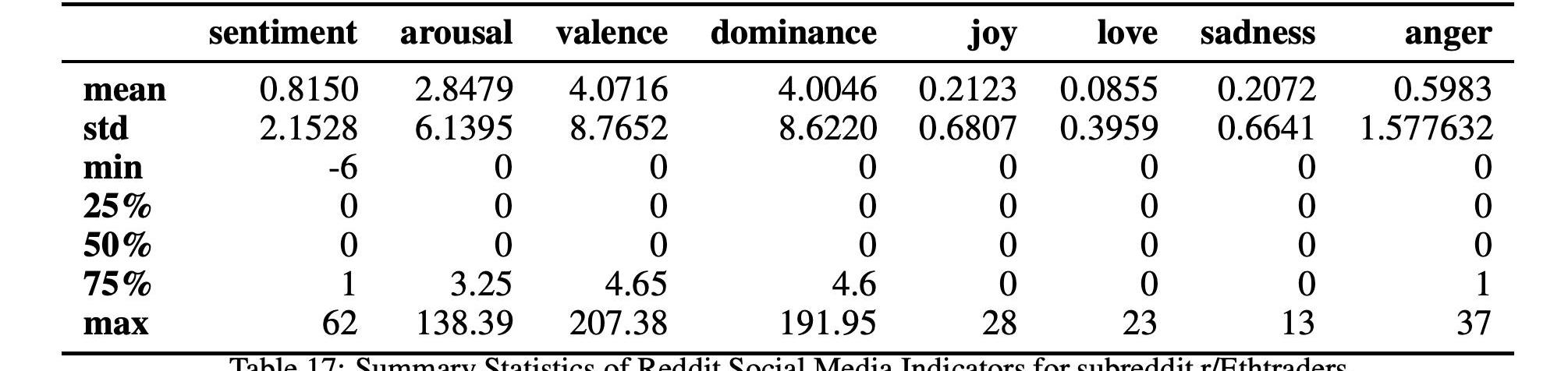
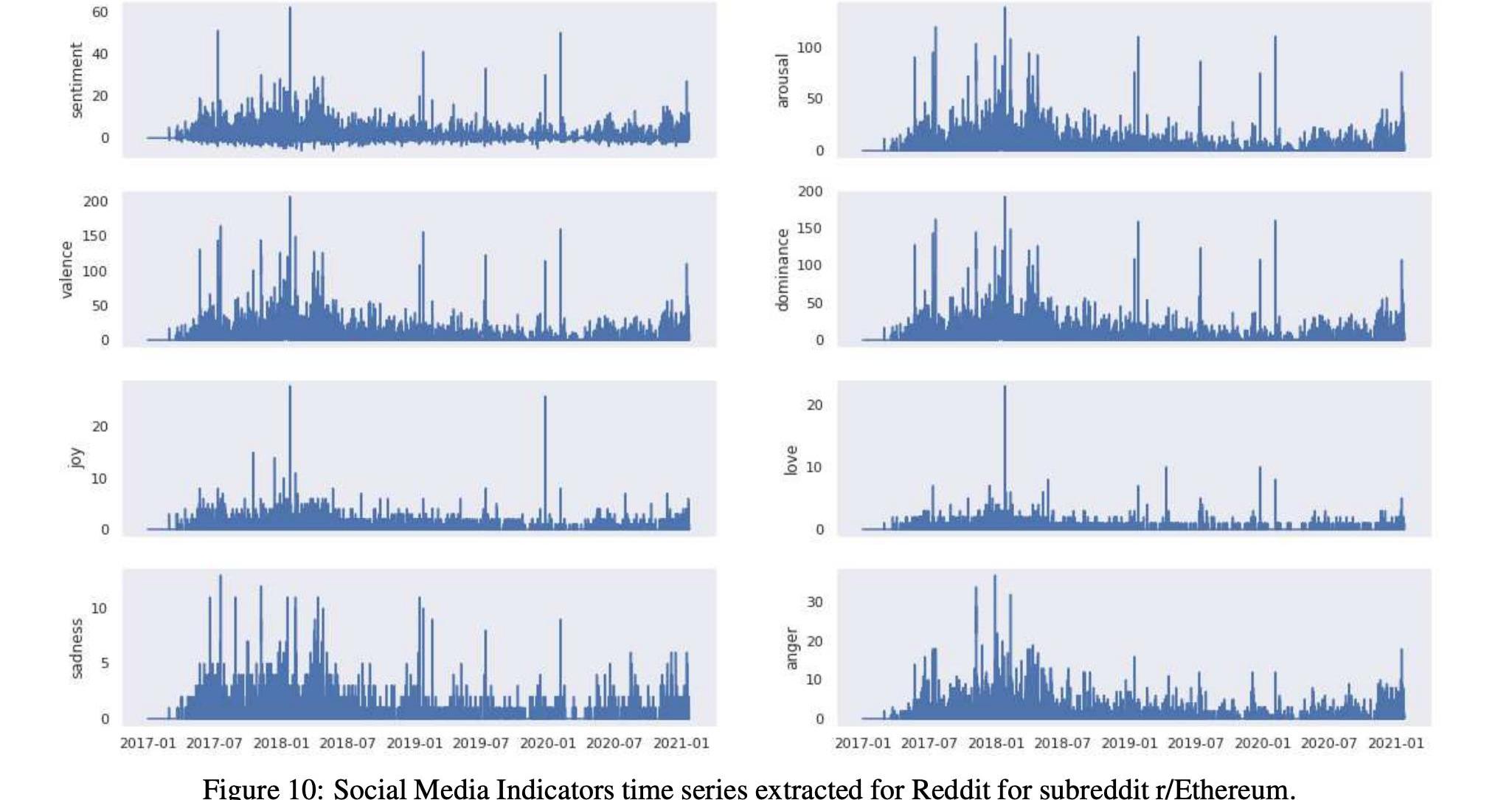
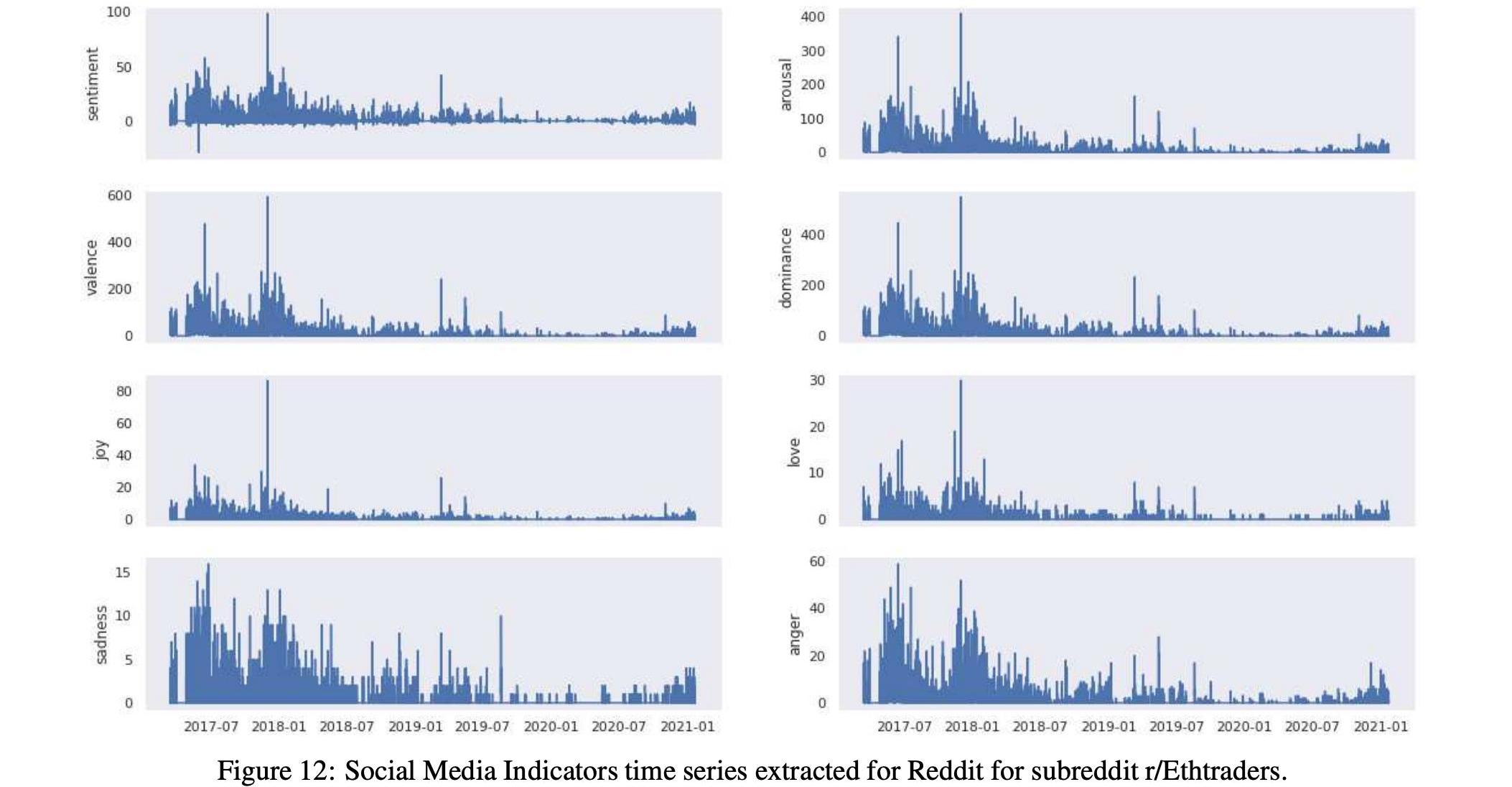
而表17和15以及圖10和12顯示了這兩個以太坊子Reddits的統計數據和時間序列。
2.4價格變動分類
目標變量是一個二進制變量,下面列出了兩個唯一的類。
上漲:這個類,標記為向上,編碼為1,表示價格上漲的情況。
下跌:此類標記為向下并用0編碼,表示價格下跌的情況。
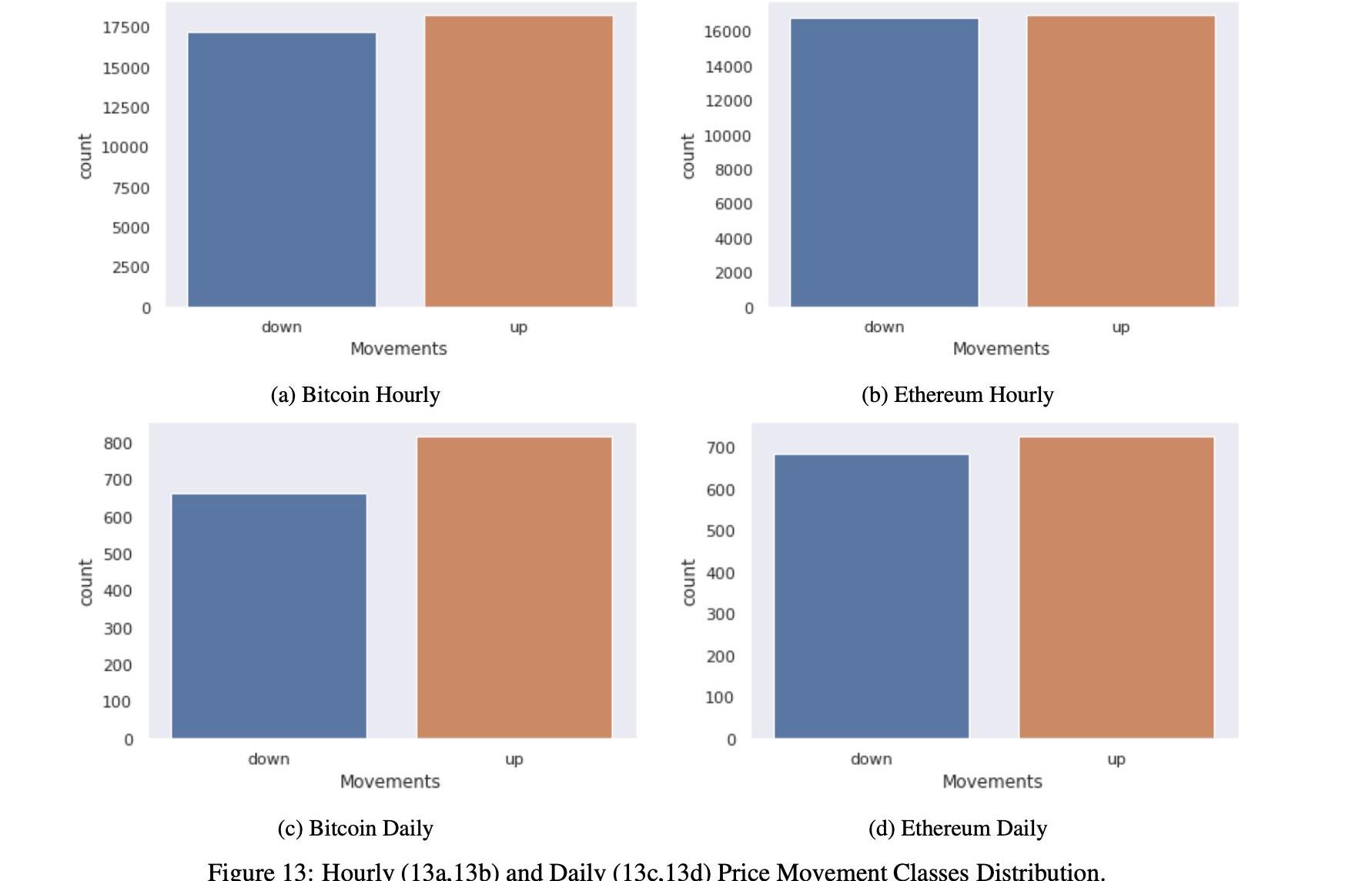
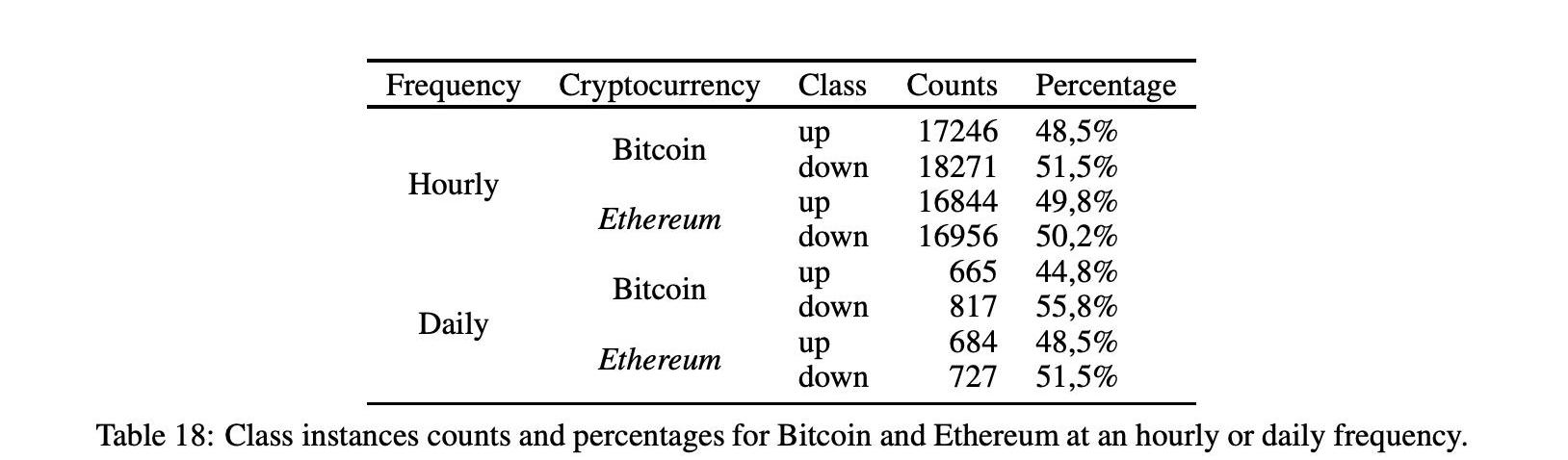
圖13顯示了每小時和每日頻率的類分布和數據集,突出顯示了我們在每小時頻率的情況下處理的是相當平衡的分類問題,在每日頻率的情況下處理的是稍微不平衡的分類問題。
動態 | Poloniex回應CLAM“閃崩事件”:無論如何損失將得到解決:Poloniex在推特發布了對于CLAM事件更新:“毫無疑問,我們致力于讓受影響的債權人成為一個整體,無論遇到什么樣的困境。我們正在努力實現這一目標,包括(但不限于)收回違約借款人欠貸款人的債務。無論如何,損失將得到解決。”據金色財經此前報道,用戶考慮起訴Poloniex,指責其處理加密貨幣CLAM閃崩虧損之舉為盜竊。[2019/6/8]
表18顯示了上漲下跌實例的詳細信息,比特幣的實例分別為48%、5%和51.5%,以太坊的實例分別為49%、8%和50%、2%。對于每日頻率,比特幣為44%、8%和55.2%,以太坊為48%、5%和51%、5%。對于比特幣的日頻率,我們有一個稍微不平衡的分布向上類,在這種情況下,我們將考慮f1分數連同準確性,以評估模型的性能。
2.5時間序列處理
由于我們使用的是有監督學習問題,我們準備我們的數據有一個向量的x輸入和y輸出與時間相關。在這種情況下,輸入向量x稱為回歸量。x輸入包括模型的預測值,即過去的一個或多個值,即所謂的滯后值。輸入對應于前面章節中討論的選定特征的值。目標變量y是二進制變量,可以是0或1。0實例表示價格向下跌。當時間t的收盤價與時間t+1的開盤價之差小于或等于0時,獲得時間t的0實例。1實例表示價格向上,即價格上漲情況。當時間t的收盤價與下一時間步t+1的開盤價之差大于0時,得到1實例。我們考慮了兩個時間序列模型:
受限:輸入向量x僅包含技術指標。
無限制:輸入向量x由技術、交易和社交媒體指標組成。
對于限制模型和非限制模型,我們對每個指標使用1個滯后值。這種區分的目的是確定和量化回歸向量中添加的交易和社交媒體情緒指標是否會有效改善比特幣和以太坊的價格變化分類。
3方法論
本節描述了我們分析中考慮的深度學習算法,然后討論了超參數的微調。
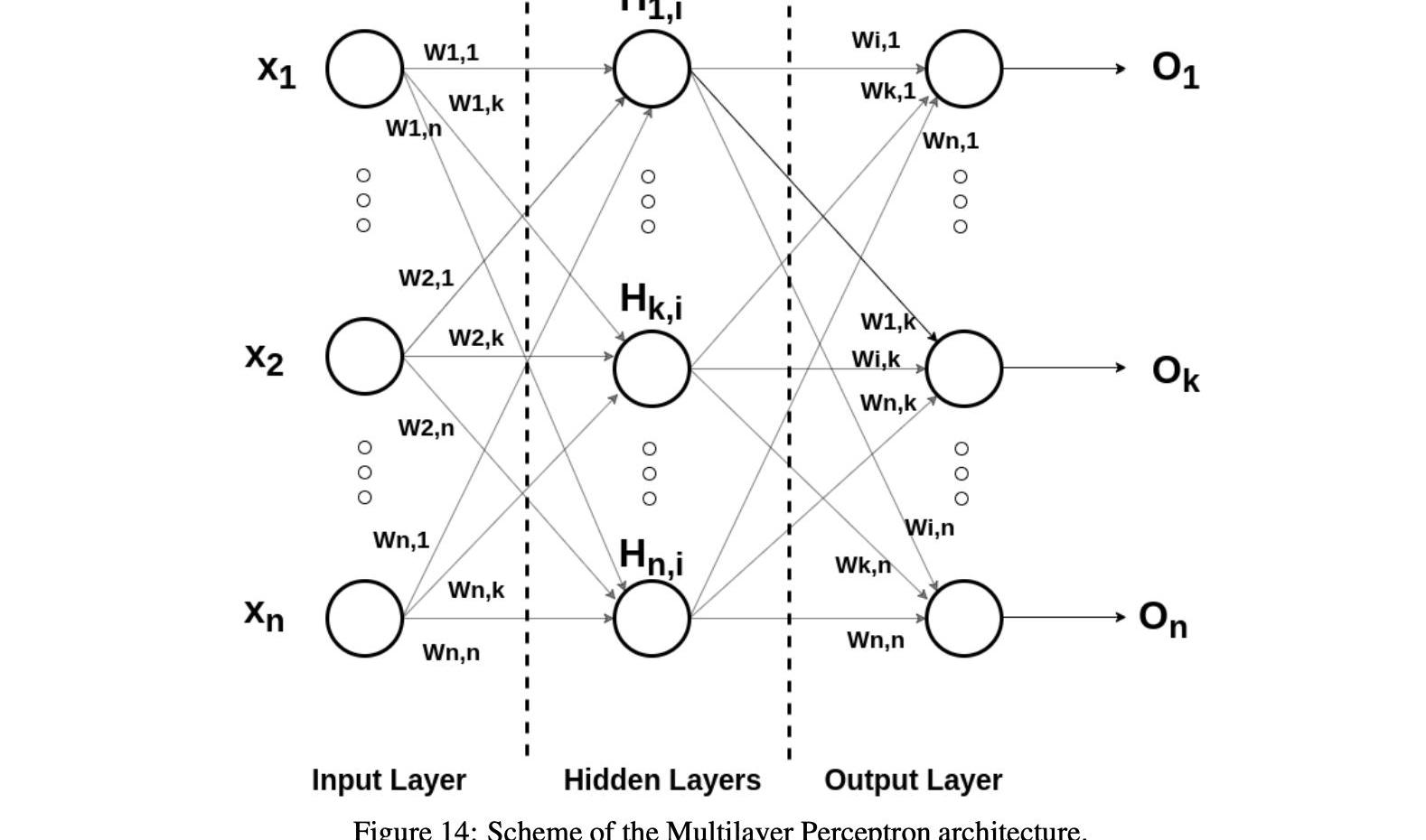
3.1多層感知器
多層感知器是一類前饋人工神經網絡,具有多層感知器和典型的激活函數的特點。
最常見的激活功能有:
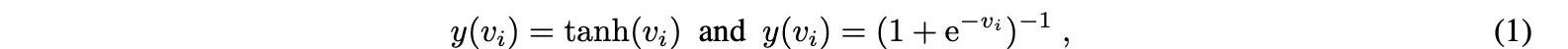
其中Vi是輸入的加權向量。
MLP包含三個主要節點類別:輸入層節點、隱藏層節點和輸出層節點。除了輸入節點外,神經網絡的所有節點都是使用非線性激活函數的感知器。MLP不同于線性感知器,因為它具有多層結構和非線性激活函數。
一般來說,MLP神經網絡對噪聲有很強的抵抗能力,并且在缺失值時也能支持學習和推理。神經網絡對映射函數沒有很強的假設,很容易學習線性和非線性關系。可以指定任意數量的輸入特征,為多維預測提供直接支持。可以指定任意數量的輸出值,為多步甚至多變量預測提供直接支持。基于這些原因,MLP神經網絡可能對時間序列預測特別有用。
在深度學習技術的最新發展中,整流線性單元是一種分段線性函數,經常被用來解決與sigmoid函數相關的數值問題。ReLU的例子是在-1和1之間變化的雙曲正切函數,或者在0和1之間變化的logistic函數。這里第i個節點的輸出是yi,輸入連接的加權和是vi。
通過包含整流器和softmax函數,開發了替代激活函數。徑向基函數包括更高級的激活函數。
由于MLPs是完全連接的架構,因此一層中的每個節點用特定的權重wi,j連接到下一層中的每個節點。神經網絡的訓練采用有監督的反向傳播法和最優化方法。數據處理后,感知機通過調整連接權值進行學習,這取決于輸出中相對于預期結果的誤差量。感知器中的反向傳播是最小均方算法的推廣。
當第n個訓練樣本呈現給輸入層時,輸出節點j中的誤差量為ej=dj?yj,其中d是預測值,y是感知器應生成的實際值。然后,反向傳播方法調整節點權重以最小化等式提供的整個輸出誤差:
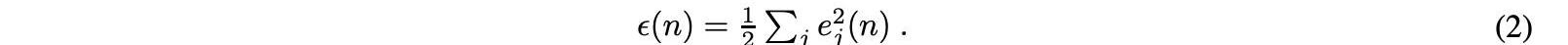
使用公式中的梯度下降法進一步計算每個節點權重的調整,其中yi是前一個神經元的輸出,η是學習率:
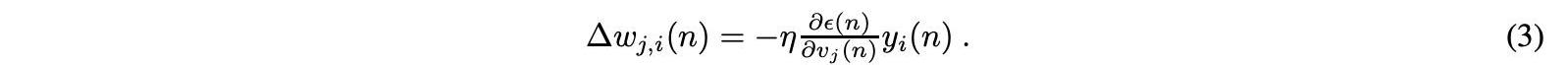
參數η通常被設置為權值收斂到響應和響應周圍振蕩之間的權衡。
感應局部場vj變化,可以計算其導數:
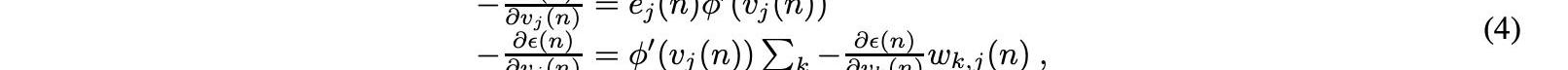
式中,φ′是上述激活函數的導數,激活函數本身不變。當修改隱藏節點的權重時,分析更為困難,但可以證明,相關的量是等式中所示的量。該算法表示激活函數的反向傳播,如等式所示,取決于表示輸出層的第k層的權重的調整,而該調整又取決于隱藏層權重的激活函數的導數。
3.2長短期記憶網絡
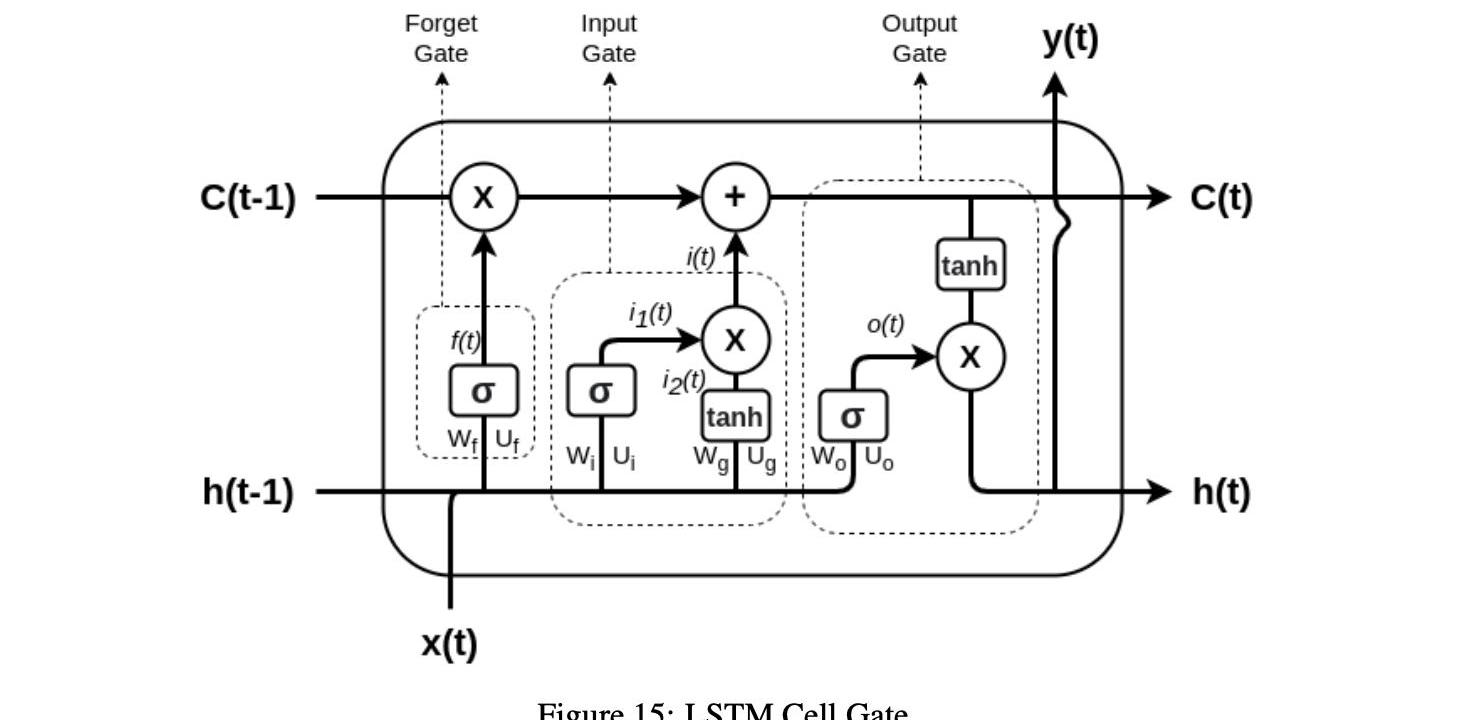
長短期記憶網絡是遞歸神經網絡的一種特殊形式,能夠捕捉數據序列中的長期依賴關系。RNN是一種具有特定拓撲結構的人工神經網絡,專門用于識別不同類型數據序列中的模式:例如,自然語言、DNA序列、手寫、單詞序列或來自傳感器和金融市場的數字時間序列數據流。經典的遞歸神經網絡有一個顯著的缺點,那就是它們不能處理長序列和捕捉長期的依賴關系。RNN只能用于具有短期內存依賴性的短序列。LSTM是用來解決長期記憶問題的,它是直接從RNN派生出來的,用來捕獲長期的依賴關系。LSTM神經網絡以單元為單位組織,通過應用一系列運算來執行輸入序列變換。內部狀態變量在從一個單元轉發到下一個單元時由LSTM單元保留,并由所謂的操作門更新,如圖16所示。所有三個門都有不同且獨立的權值和偏差,因此網絡可以了解要維持多少以前的輸出和電流輸入,以及有多少內部狀態要傳遞給輸出。這樣的門控制有多少內部狀態被傳輸到輸出,并且與其他門的操作類似。LSTM單元包括:
HeroNode創始人劉國平:工業革命以來最大的技術革命——區塊鏈如何實現去中心化:近日,HeroNode 創始人劉國平受邀前往平安總部進行區塊鏈技術演講。會上,劉國平就“區塊鏈到底是什么”和“區塊鏈有什么特點”兩個問題,用通俗易懂的語言深入淺出地進行講解,并著重介紹了區塊鏈對現有公司業務的挑戰。劉國平,區塊鏈應用技術專家、比特幣第一批礦工、Hero 移動跨平臺框架開發創始人,Hero 理事會會長。曾任職萬得資訊、第九城市、點融網等知名互聯網公司負責技術研發、并深度參與點融網區塊鏈應用場景開發。[2018/4/2]
1單元狀態:這個狀態帶來整個序列的信息,并代表網絡的內存。
2遺忘門:它過濾從以前的時間步中保留的相關信息。
3輸入門:它決定從當前時間步添加哪些相關信息。
4輸出門:它控制當前時間步的輸出量。
第一步是忘記門。這個門將過去的或滯后的值作為輸入,并決定應該忘記多少過去的信息以及應該保存多少。先前隱藏狀態的輸入和當前輸入通過sigmoid函數傳輸到輸出門。當可以忘記該信息時,輸出接近0,而當要保存該信息時,輸出接近1,如下所示:
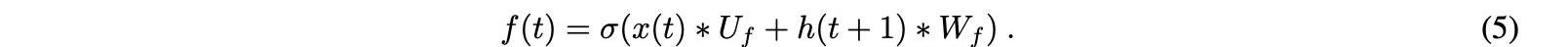
矩陣Wf和Uf分別包含輸入連接和循環連接的權重。下標f可以表示忘記門。xt表示LSTM的輸入向量,ht+1表示LSTM單元的隱藏狀態向量或輸出向量。
第二個門是輸入門。在這個階段,單元狀態被更新。先前的隱藏狀態和當前輸入最初表示為sigmoid激活函數的輸入。為了提高網絡調諧,它還將隱藏狀態和電流輸入傳遞給tanh函數,以壓縮?1和1之間的值。然后將tanh和sigmoid的輸出逐元素相乘。等式6中的sigmoid輸出確定了要從tanh輸出中保留的重要信息:
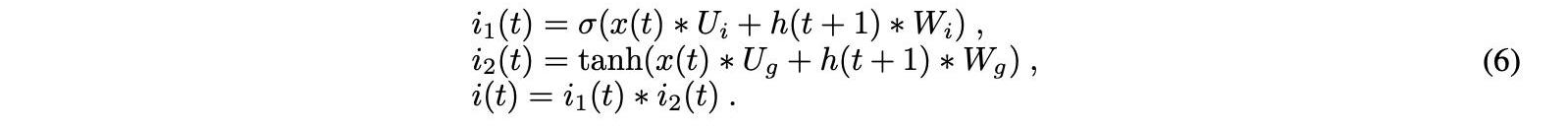
單元狀態可以在輸入門激活之后確定。接下來,將上一時間步的單元狀態逐元素乘以遺忘門輸出。這會導致在單元格狀態下,當值與接近0的值相乘時,忽略值。輸入門輸出按元素添加到單元狀態。方程7中的新單元狀態是輸出:
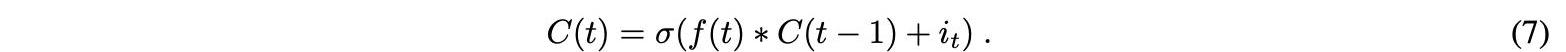
最后一個門是輸出門,它指定下一個隱藏狀態的值,該值包含一定量的先前輸入信息。在這里,當前輸入和先前的隱藏狀態相加并轉發到sigmoid函數。然后新的細胞狀態被轉移到tanh函數。最后,將tanh輸出與sigmoid輸出相乘,以確定隱藏狀態可以攜帶哪些信息。輸出是一個隱藏的新狀態。新的單元狀態和新的隱藏狀態然后通過等式8移動到下一階段:
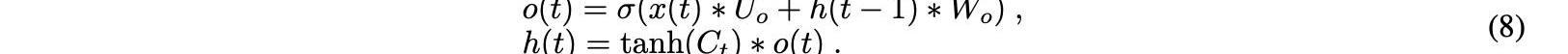
為了進行這一分析,我們使用Keras框架進行深度學習。我們的模型由一個堆疊的LSTM層和一個密集連接的輸出層和一個神經元組成。
3.3注意機制神經網絡
注意函數是深度學習算法的一個重要方面,它是編碼器-譯碼器范式的擴展,旨在提高長輸入序列的輸出。圖16顯示了AMNN背后的關鍵思想,即允許解碼器在解碼期間有選擇地訪問編碼器信息。這是通過為每個解碼器步驟創建一個新的上下文向量來實現的,根據之前的隱藏狀態以及所有編碼器的隱藏狀態來計算它,并為它們分配可訓練的權重。通過這種方式,注意力技巧賦予輸入序列不同的優先級,并更多地關注最重要的輸入。
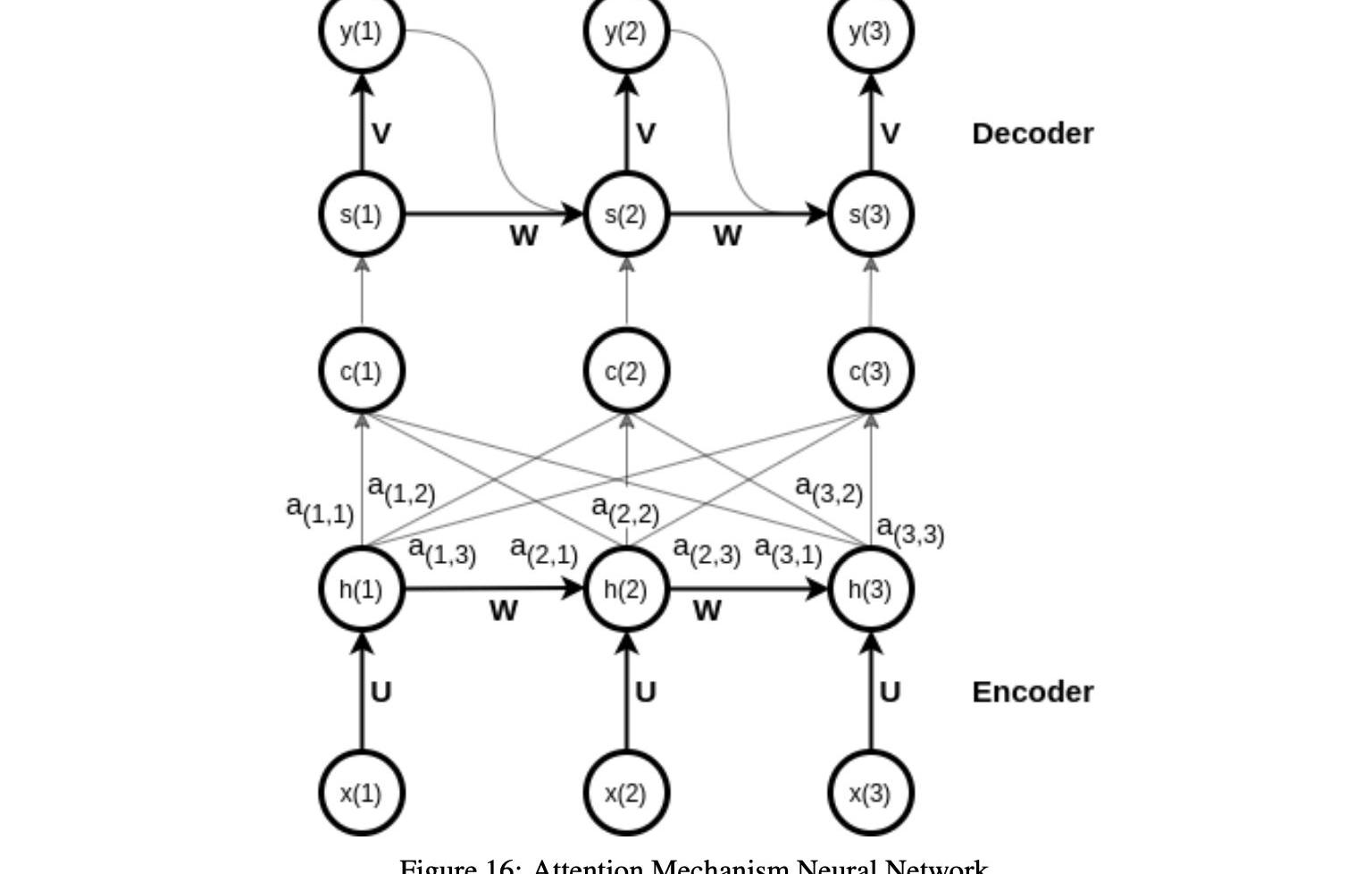
編碼器操作與編碼器-解碼器混合操作本身非常相似。每個輸入序列的表示在每個時間步確定,作為前一時間步的隱藏狀態和當前輸入的函數。
最終隱藏狀態包括來自先前隱藏表示和先前輸入的所有編碼信息。
注意機制和編解碼器模型之間的關鍵區別在于,對于每個解碼器步驟t,計算一個新的背景向量c。我們如下進行以測量時間步長t的上下文向量c。首先,對于編碼器的時間步長j和解碼器的時間步長t的每個組合,使用等式中的加權和來計算所謂的對齊分數e:
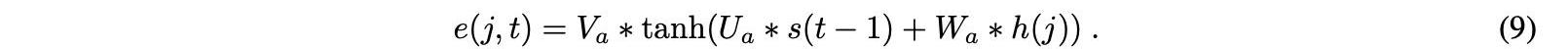
Wa、Ua和Va是這個公式中的學習權重,它們被稱為注意權重。Wa權重鏈接到編碼器的隱藏狀態,Ua權重鏈接到解碼器的隱藏狀態,Va權重確定計算對齊分數的函數。分數e在編碼器j的時間段上使用softmax函數在每個時間步t處歸一化,獲得如下注意權重α:
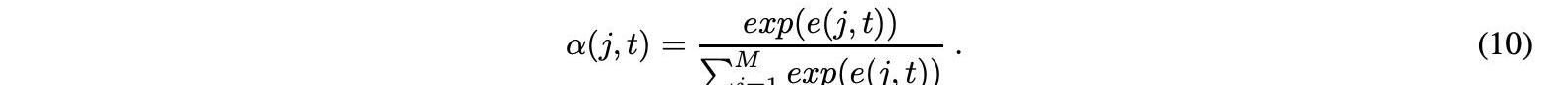
時間j處的輸入的重要性由用于解碼時間t的輸出的注意權重α表示。根據作為編碼器的所有隱藏值的加權和的注意權重來估計上下文向量c,如下所示:
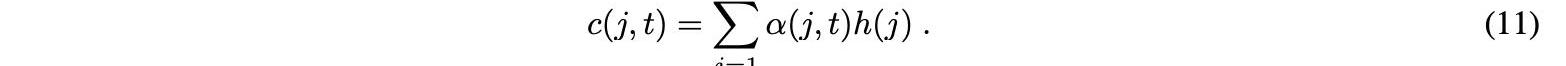
根據這種方法,所謂的注意功能是由上下文數據向量觸發的,對最重要的輸入進行加權。
上下文向量c現在被轉發到解碼器以計算下一個可能輸出的概率分布。此解碼操作涉及輸入中存在的所有時間步長。然后根據循環單位函數計算當前隱藏狀態s,將上下文向量c、隱藏狀態s和輸出y?作為輸入,根據以下等式:
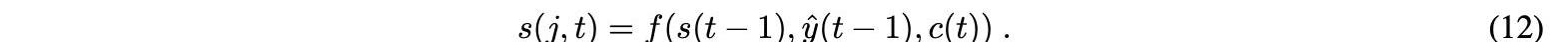
利用該函數,模型可以識別輸入序列不同部分與輸出序列相應部分之間的關系。softmax函數用于在每個時刻t計算處于加權隱藏狀態的解碼器的輸出:
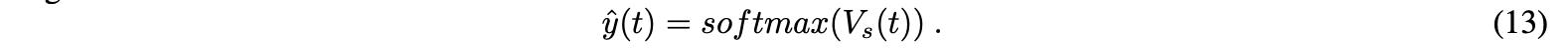
對于LSTM,由于注意權值的存在,注意機制在長輸入序列下提供了更好的結果。
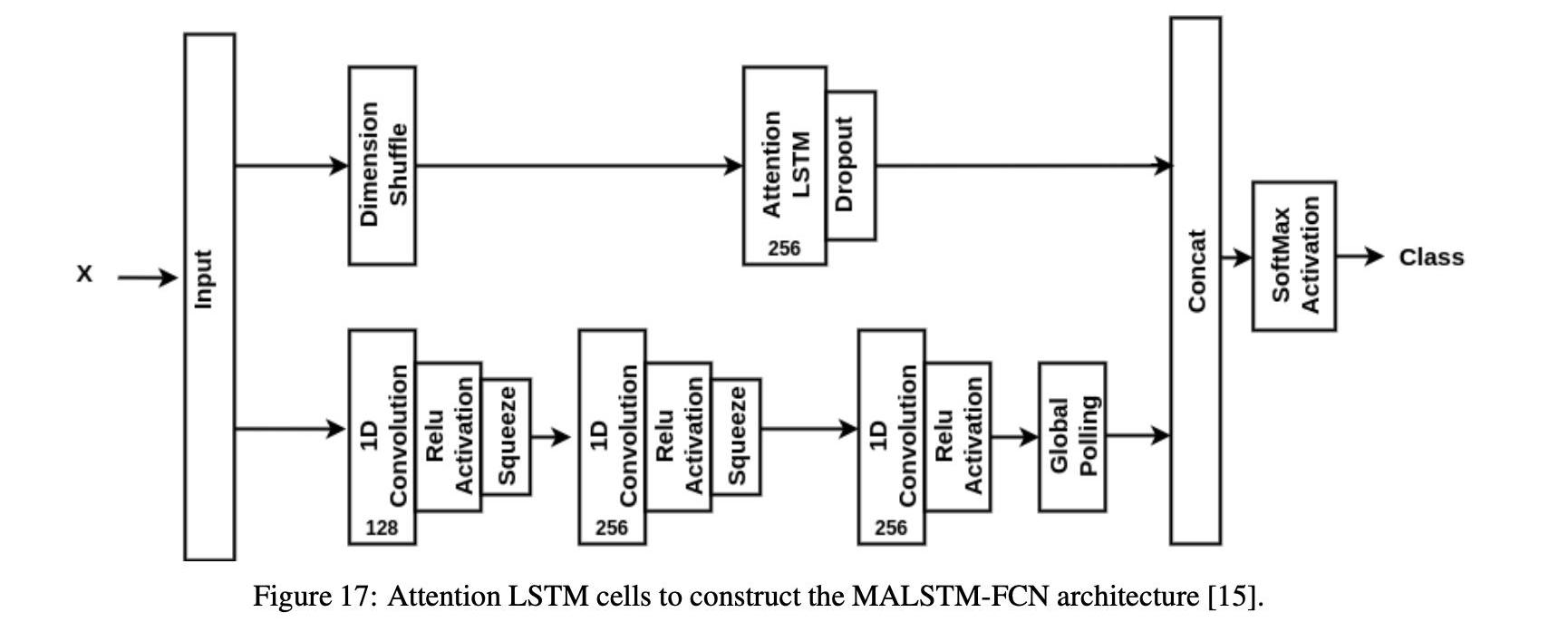
在這項研究中,我們特別使用了Fazle等人提出的具有完全卷積網絡的多元注意LSTM。圖17顯示了MALSTM-FCN的體系結構,包括每層的神經元數量。輸入序列與完全卷積層和注意LSTM層并行,并通過用于二進制分類的softmax激活函數連接和傳遞到輸出層。全卷積塊包含三個分別由128、256和256個神經元組成的時間卷積塊,用作特征抽取器。在級聯之前,每個卷積層通過批量歸一化來完成。維洗牌變換輸入數據的時間維,使得LSTM一次獲得每個變量的全局時間信息。因此,對于時間序列分類問題,維數洗牌操作減少了訓練和推理的計算時間,同時又不損失精度。
3.4卷積神經網絡
卷積神經網絡是一類特殊的神經網絡,最常用于圖像處理、圖像分類、自然語言處理和金融時間序列分析等深度學習應用。
CNN架構中最關鍵的部分是卷積層。這層執行一個稱為卷積的數學運算。在這種情況下,卷積是一種線性運算,它涉及輸入數據矩陣和二維權值數組之間的乘法。這些網絡在至少一層中使用卷積運算。
卷積神經網絡具有與傳統神經網絡相似的結構,包括輸入輸出層和多個隱層。CNN的主要特征是其隱藏層通常由執行上述操作的卷積層組成。圖18描述了用于時間序列分析的CNNs的一般架構。我們使用一個一維卷積層,而不是通常的二維卷積層典型的圖像處理任務。然后用輪詢層對第一層進行歸一化,然后將其展平,以便輸出層可以在每個步驟t處處理整個時間序列。在這種情況下,許多一維卷積層可以組合在深度學習網絡中。
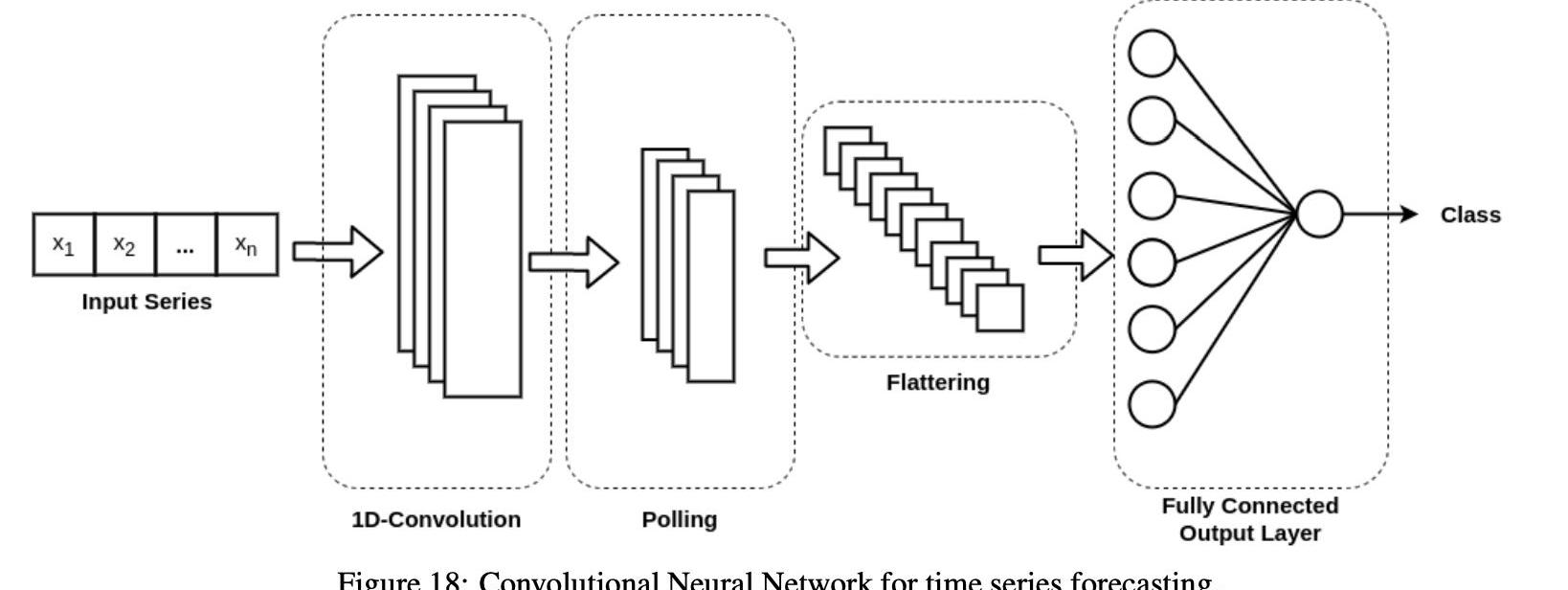
對于CNN的實現,我們使用Keras框架進行深入學習。我們的模型由兩個或多個堆疊的一維CNN層組成,一個密接層有N個神經元用于輪詢,一個密接層有N個神經元用于平坦化,最后一個密接輸出層有一個神經元。
3.5超參數調整
超參數調整是對給定算法的超參數進行優化的一種方法。它用于確定超參數的最佳配置,以使算法獲得最佳性能,并根據特定的預測誤差進行評估。對于每個算法,選擇要優化的超參數,并為每個超參數定義適當的搜索間隔,包括所有要測試的值。然后將該算法與第一個選定的超參數配置匹配到數據集的特定部分。擬合模型在訓練階段以前沒有使用過的部分數據上進行測試。此測試程序返回所選預測誤差的特定值。
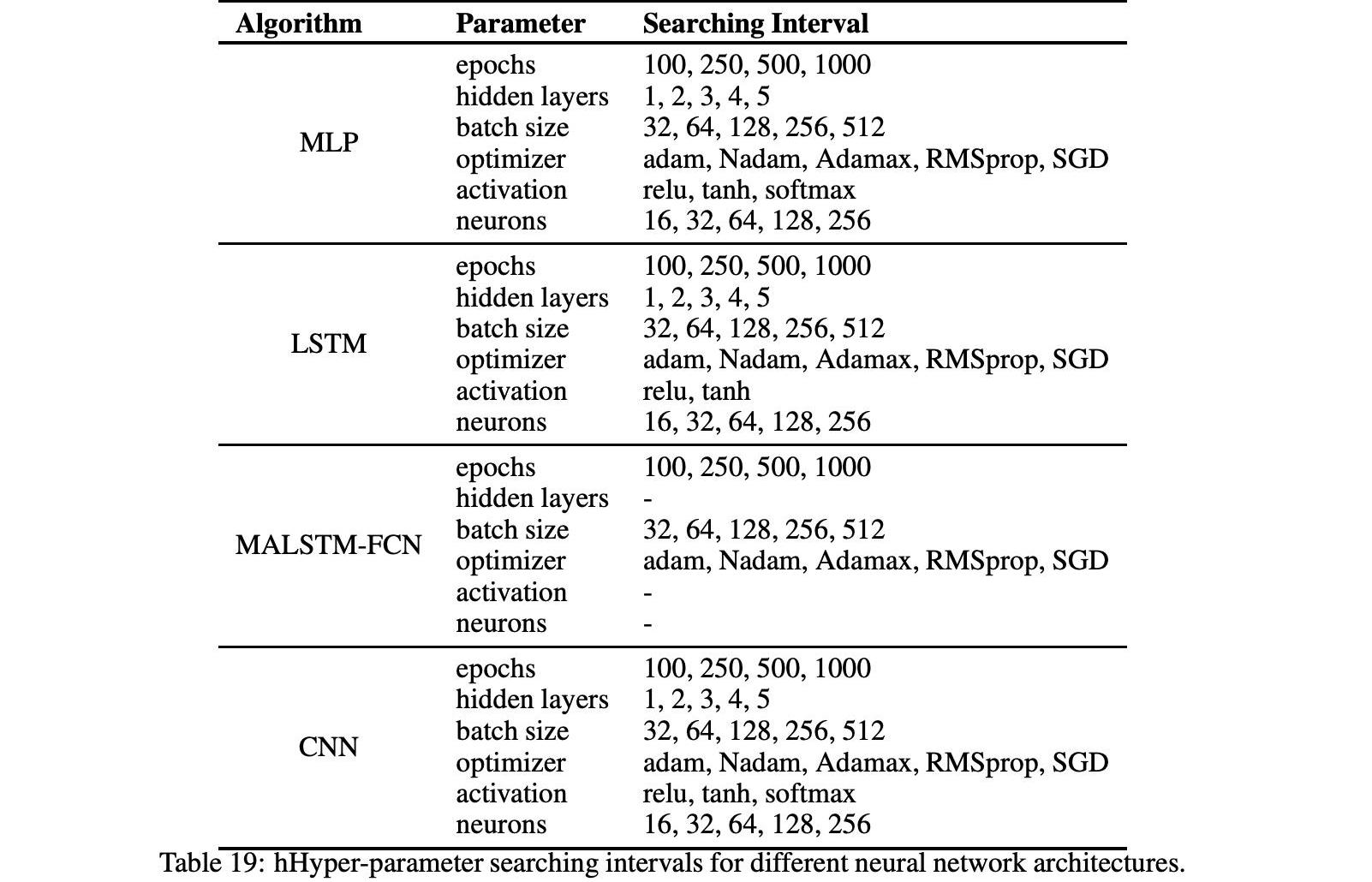
通過網格搜索程序的優化程序在測試了所有可能的超參數值組合后結束。因此,選擇在所選預測誤差方面產生最佳性能的超參數配置作為優化配置。表19顯示了每個實現算法的超參數搜索間隔。由于MALSTM-FCN是一種特定于深層神經網絡的體系結構,層的數量、每層的神經元數以及每層的激活函數已經預先指定。
為了確保超參數優化過程的魯棒性,我們使用模型驗證技術來評估給定模型所獲得的性能如何推廣到一個獨立的數據集。此驗證技術涉及將數據樣本劃分為訓練集、驗證集和測試集。在我們的分析中,我們使用37.8%的袋外樣本和10000次迭代來實現Boostrap方法,以驗證最終的超參數。
4實驗證據
在本節中,我們報告并討論分析的主要結果。特別地,我們討論了限制模型和非限制模型的結果。這些結果是根據標準的分類錯誤度量來評估的:準確度、f1分數、準確度和召回率。
4.1受限模型的超參數
我們在這里簡要討論了3.5節中提到的四種深度學習算法的超參數的微調,考慮到每小時的頻率。表20顯示了在分類誤差度量方面使用網格搜索技術對不同神經網絡模型獲得的最佳結果。表20列出了MALSTM-FNC和MLP模型的最佳識別參數和相關結果。
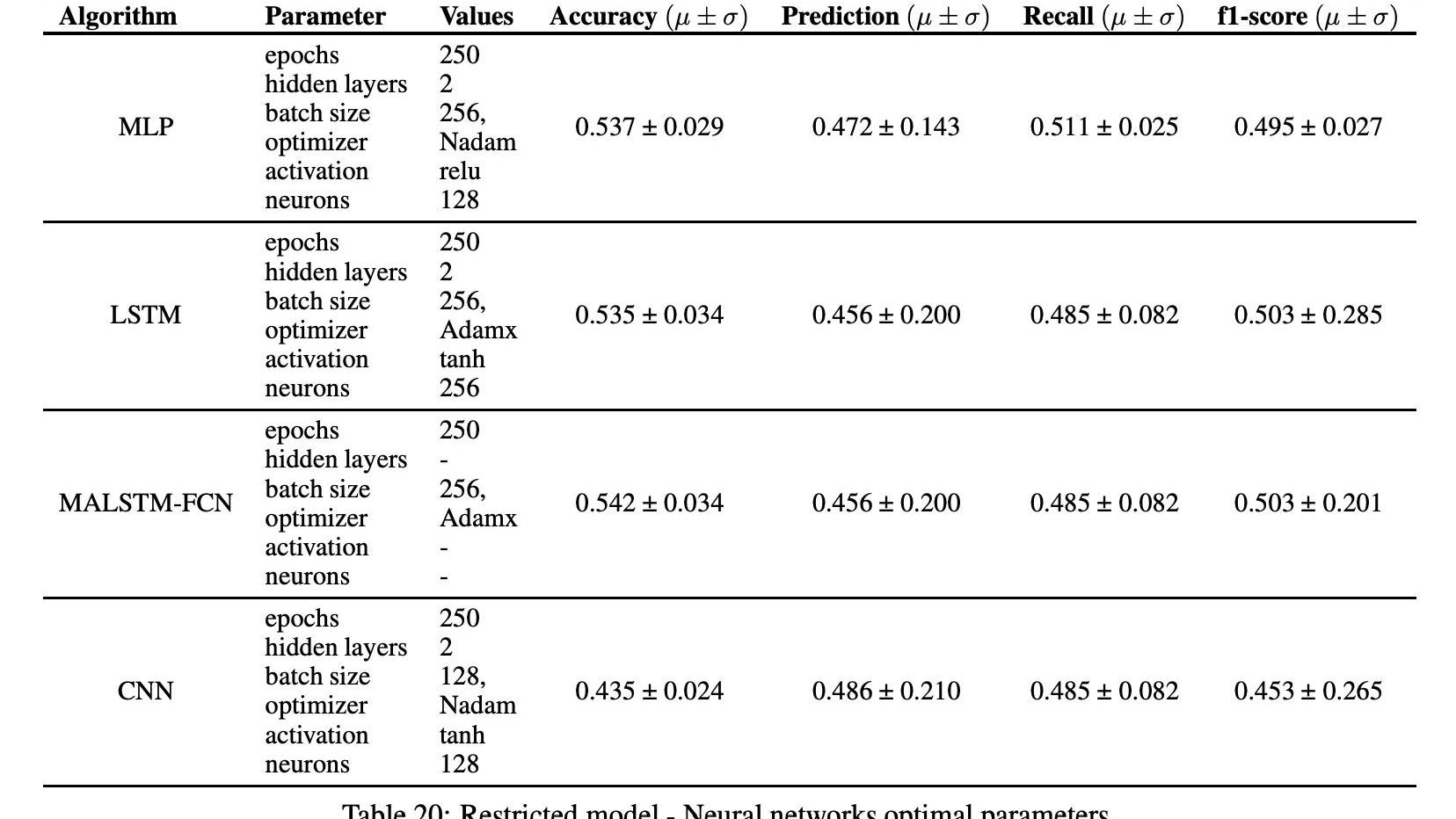
獲得最佳精確度的神經網絡是MALSTM-FNC,平均精確度為53.7%,標準偏差為2.9%。在實施的機器學習模型中,獲得最佳f1分數的是MALSTM-FNC,平均準確率為54%,標準偏差為2.01%。
4.2無限制模型的超參數
表21顯示了神經網絡模型通過網格搜索技術獲得的關于分類誤差度量的最佳結果。CNN和LSTM模型的最佳識別參數和相關結果見表21。
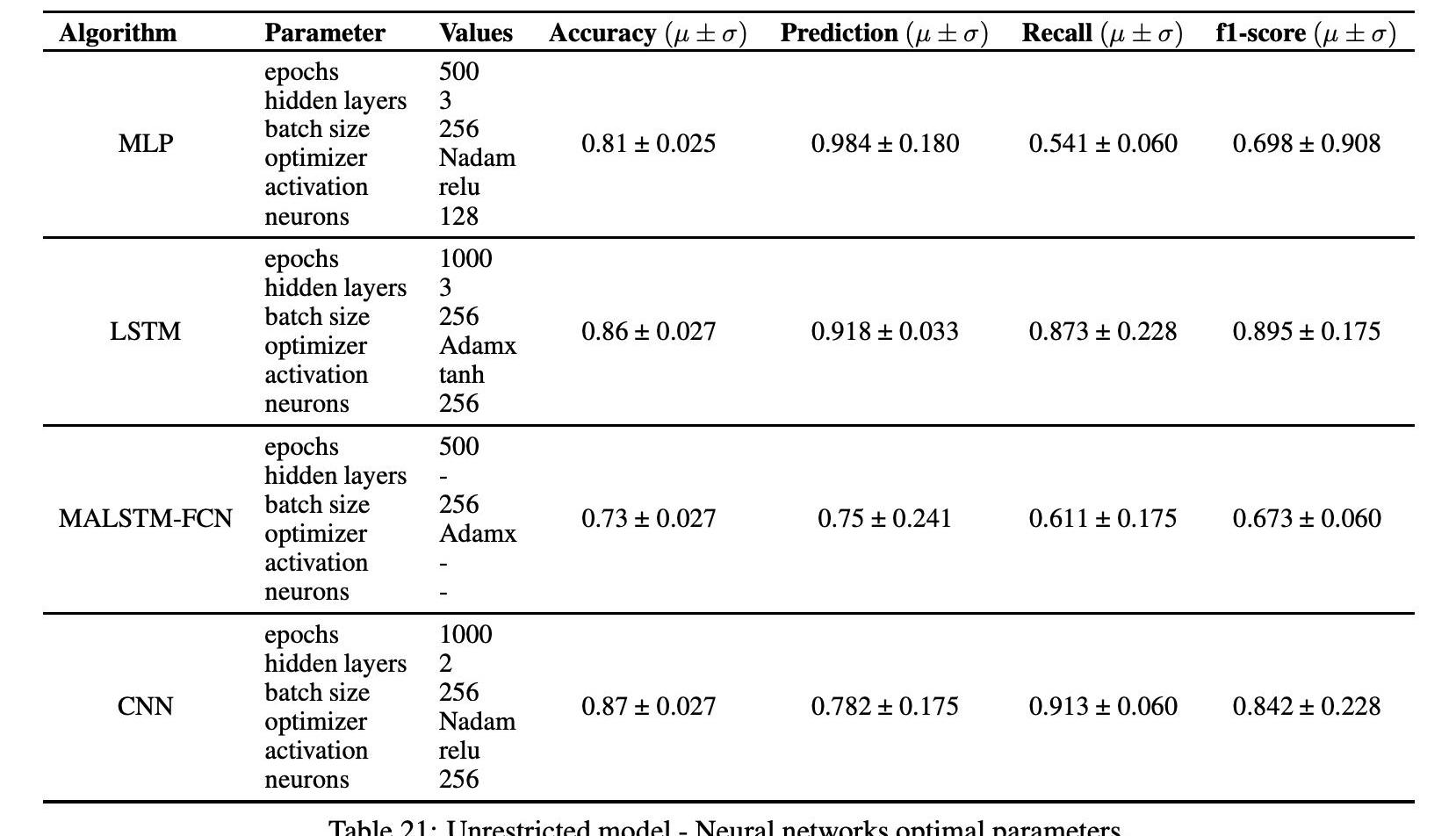
對于無限制模型的結果表明,在模型中加入交易和社交媒體指標可以有效地提高平均準確度,即預測誤差。對于所有實現的算法,這個結果都是一致的,這允許我們排除這個結果是統計波動,或者它可能是實現的特定分類算法的人工制品。利用CNN模型得到了無約束模型的最佳結果,平均準確率為87%,標準差為2.7%。
4.3結果和討論
表22顯示了使用四種深度學習算法進行時頻價格變動分類任務的結果。此表顯示了受限和非受限模型的結果。首先,可以注意到,對于所有四種深度學習算法,無限制模型在精確度、查全率、召回率和F1分數方面都優于限制模型。準確率范圍從限制MLP的51%到CNNs和LSTM的84%。
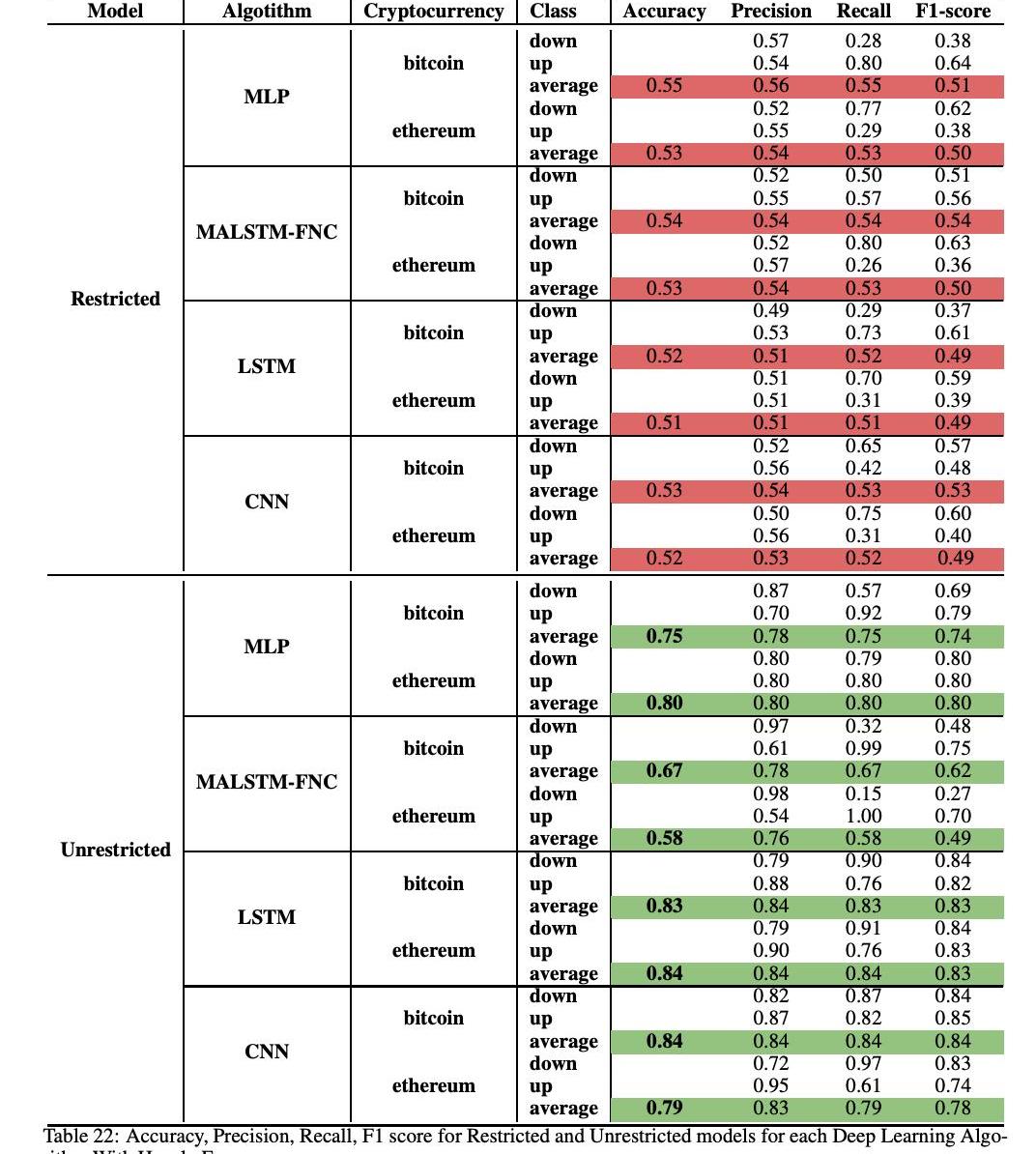
事實上,這四個分類器的結果是一致的,進一步證實了這不是由于統計波動,而是由于較高的預測無限制模型。對于比特幣,最高的性能是通過CNN架構獲得的,而對于以太坊則是通過LSTM獲得的。
我們還進一步探討了按小時頻率的無限制模型的分類,考慮了兩個子模型:一個子模型包括技術和社交指標,另一個子模型包括所有指標。這樣,就可以理清社會和交易指標對模型性能的影響。我們對兩個無限制子模塊的準確度、預測、回憶和F1得分的分布進行了統計t檢驗,發現增加社會指標并不能顯著改善無限制模型。因此,在表22中,我們省略了僅包括社會和技術指標的無限制模型。
表23顯示了四種深度學習算法對日頻率價格變動分類的結果。此表顯示了受限和非受限模型的結果。將無限制模型進一步劃分為技術-社會和技術-社會-交易子模型,以更好地分別突出社會和交易指標對模型的貢獻。
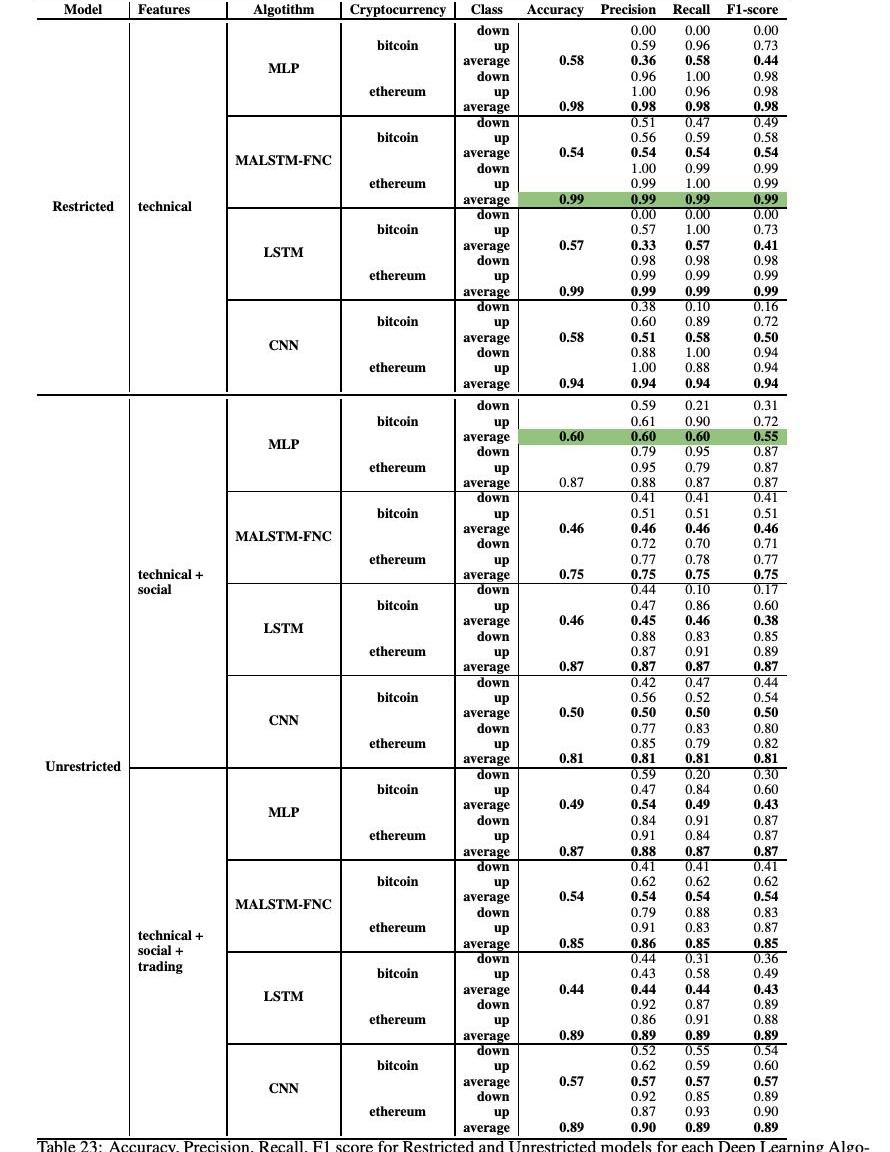
MALSTM-CNF使用僅由技術指標組成的受限模型,以99%的準確率實現了以太坊的最佳分類性能。對于比特幣而言,MLP的F1分數為55%,準確率為60%,而不受限制的模型只有社交媒體指標和技術指標。對于日頻率分類,我們可以看到,在一般技術指標單獨表現更好的分類第二天的價格走勢。我們向模型中添加的指標越多,性能下降的幅度就越大。另一個普遍的結果是,以太坊每日價格變動分類的準確性、精確性、召回率和F1分數遠遠好于比特幣。日分類的結果與其他研究一致,小時和日分類在考慮小時無限制模型時有顯著改進。社交媒體指標在比特幣案件的日常頻率上尤其重要。這一結果與最近關于社交媒體情緒對加密貨幣市場影響的結果一致:社交媒體對市場的影響表現出很長的滯后性,這種滯后性不是每小時捕捉到的,也不是每小時相關的。
5有效性的威脅
在本節中,我們將討論對我們的分析有效性的潛在限制和威脅。首先,我們的分析側重于以太坊和比特幣:這可能會對外部有效性構成威脅,因為對不同的加密貨幣進行分析可能會導致不同的結果。
第二,對內部效度的威脅與影響結果的混雜因素有關。基于經驗證據,我們假設技術、交易和社會指標在我們的模型中是詳盡無遺的。盡管如此,本研究可能忽略了其他可能影響價格變動的因素。
最后,結構效度的威脅集中在觀察結果如何準確地描述感興趣的現象上。價格變動的檢測和分類是基于描述整個現象的客觀數據。一般來說,技術指標和交易指標是以客觀數據為基礎的,通常是可靠的。社交媒體指標是基于通過使用公開數據集訓練的深度學習算法獲得的實驗測量:這些數據集可能帶有內在偏見,而這些偏見又會轉化為情感和情緒的分類錯誤。
6結論
在最近的文獻中,人們曾多次嘗試對主要加密貨幣的價格或其他市場指標的不穩定行為進行建模和預測。盡管許多研究小組致力于這一目標,密碼貨幣市場的分析仍然是最有爭議和難以捉摸的任務之一。有幾個方面使解決這個問題變得如此復雜。例如,由于其相對年輕,加密貨幣市場是非常活躍和快節奏的。新加密貨幣的出現是一個常規事件,導致市場本身的組成發生意外和頻繁的變化。此外,加密貨幣的高價格波動性及其“虛擬”性質同時也是投資者和交易員的福音,也是任何嚴肅的理論和實證模型的詛咒,具有巨大的實際意義。對這樣一個年輕市場的研究,其價格行為在很大程度上還沒有被探索,不僅在科學領域,而且對投資者和加密市場格局中的主要參與者和利益相關者都有著根本性的影響。
在本文中,我們旨在評估在“經典”技術變量中添加社會和交易指標是否會導致加密貨幣價格變化分類的實際改進。這一目標是實現和基準廣泛的深度學習技術,如多層感知器,多元注意長期短期記憶完全卷積網絡,卷積神經網絡和長期短期記憶神經網絡。我們在分析中考慮了比特幣和以太坊這兩種主要的加密貨幣,并分析了兩種模型:一種是僅考慮技術指標的受限模型,另一種是包括社會和交易指標的非受限模型。
在限制性分析中,就準確度、精確度、召回率和f1分數而言,獲得最佳性能的模型是MALSTM-FCN,比特幣的f1平均分數為54%,以太坊的CNN為小時頻率。在不受限制的情況下,LSTM神經網絡對比特幣和以太坊的平均準確率分別為83%和84%。對于無限制模型的小時頻率分類,最重要的發現是,在模型中加入交易和社會指標可以有效地提高平均準確度、精確度、召回率和f1分數。我們已經證實,這一發現不是統計波動的結果,因為所有實施的模型都取得了相同的成果。出于同樣的原因,我們可以排除結果依賴于特定的實現算法。最后,對于日常分類,當使用僅包含技術指標的受限模型時,MALSTM-CNFforEthereum以99%的準確率實現了最佳分類性能。對于比特幣而言,MLP的f1分數為55%,準確率為60%,無限制模型包括社交媒體指標和技術指標,在這種情況下,我們考慮比特幣的f1分數和準確率,因為第3.4節中描述了略微不平衡的類別分布。對于日頻率分類,我們可以看到,在一般技術指標單獨表現更好的分類第二天的價格走勢。我們向模型中添加的指標越多,性能下降的幅度就越大。
另一個普遍的結果是,以太坊每日價格變動分類的準確性、精確性、召回率和f1分數遠遠好于比特幣。我們的結果表明,通過對深度學習體系結構的具體設計和微調,可以實現加密貨幣價格變化分類的高性能。
Tags:加密貨幣比特幣LSTSTM加密貨幣市場行情走勢圖比特幣行情圖最新Doge of WallStreetBetsDecentralized Community Investment Protocol
上周加密市場震蕩,比特幣暴跌呈現“深V”走勢,最低跌破4.5萬美元關口。卡爾達諾代幣ADA異軍突起,以超10%的漲幅上升為市值排名第三的加密貨幣.
1900/1/1 0:00:00本文作者VitalikButerin“L2DeFi協議當前無法相互通信,因此V神Vitalik提出了解決方案.
1900/1/1 0:00:00本文來源:金融界,原題《銀河證券:從貴州茅臺和比特幣的表現看大類資產配置邏輯》 核心觀點 近期市場表現觀察及深層次邏輯分析2020年以來,全球寬松周期下.
1900/1/1 0:00:002月25日消息,去中心化資產管理協議Enzyme繼推出其v2版本之后,又宣布將在未來幾周內發布一個新版本:Sulu,這將是一個一站式DeFi儲蓄商店.
1900/1/1 0:00:00太和資本 加密貨幣市場分析報告 2020.2.25 宏觀基本面 本期要點摘要:????????????1.???本月比特幣持續上漲突破5萬美元大關.
1900/1/1 0:00:00金色DeFi日報|SUSHI區塊獎勵已降至40枚/區塊 金色財經月兒 剛剛 15 DeFi數據 1.DeFi總市值:686.
1900/1/1 0:00:00


