






 BTC/HKD-4.4%
BTC/HKD-4.4% ETH/HKD-5.66%
ETH/HKD-5.66% LTC/HKD-3.9%
LTC/HKD-3.9% DOT/HKD-6.62%
DOT/HKD-6.62% ADA/HKD-7.19%
ADA/HKD-7.19% SOL/HKD-11.34%
SOL/HKD-11.34% XRP/HKD-6.47%
XRP/HKD-6.47% DOGE/US-9.07%
DOGE/US-9.07%導讀
首先問大家一個小問題?區塊鏈的賬本數據存儲格式主要是什么類型的?
相信聰明的你一定知道是Key-Value類型存儲。
下一個問題,這些Key-Value數據在底層數據庫如何高效組織?
答案就是我們本期介紹的內容:LSM。
LSM是一種被廣泛采用的持久化Key-Value存儲方案,如LevelDB,RocksDB,Cassandra等數據庫均采用LSM作為其底層存儲引擎。
據公開數據調研,LSM是當前市面上寫密集應用的最佳解決方案,也是區塊鏈領域被應用最多的一種存儲模式,今天我們將對LSM基本概念和性能進行介紹和分析。
LSM-Tree背景:追本溯源
LSM-Tree的設計思想來自于一個計算機領域一個老生常談的話題——對存儲介質的順序操作效率遠高于隨機操作。
如圖1所示,對磁盤的順序操作甚至可以快過對內存的隨機操作,而對同一類磁盤,其順序操作的速度比隨機操作高出三個數量級以上,因此我們可以得出一個非常直觀的結論:應當充分利用順序讀寫而盡可能避免隨機讀寫。
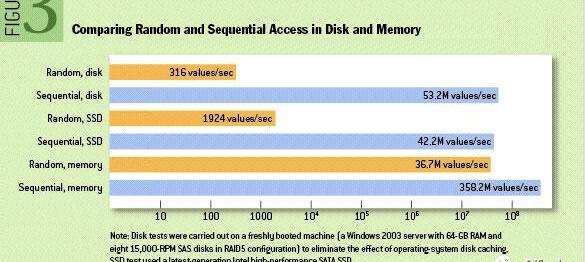
Figure1Randomaccessvs.Sequentialaccess
動態 | 美國財政部使用區塊鏈技術 測試追蹤聯邦撥款:管理美國政府收入的美國財政部目前正在進行一項通過區塊鏈技術追蹤聯邦撥款的測試。該項目于去年 9 月發起,由財政部與圣地亞哥州立大學、杜克大學和美國國家科學基金會合作展開,預計將于本月底結束。美國財政部創新計劃經理 Craig Fischer 在最近一次會議上表示,這是一項使用區塊鏈解決信用證概念證明的試點測試,具體來說,該解決方案會對信用證進行代幣化,從而得以跟蹤聯邦儲備金流向受贈人的補助金流程。Fischer 表示,代幣化有助于確定贈款接受者、贈款金額和關鍵日期,例如授予日期。[2020/1/13]
考慮到這一點,如果我們想盡可能提高寫操作的吞吐量,那么最好的方法一定是不斷地將數據追加到文件末尾,該方法可將寫入吞吐量提高至磁盤的理論水平,然而也有顯而易見的弊端,即讀效率極低,我們稱這種數據更新是非原地的,與之相對的是原地更新。
為了提高讀取效率,一種常用的方法是增加索引信息,如B+樹,ISAM等,對這類數據結構進行數據的更新是原地進行的,這將不可避免地引入隨機IO。
LSM-Tree與傳統多叉樹的數據組織形式完全不同,可以認為LSM-Tree是完全以磁盤為中心的一種數據結構,其只需要少量的內存來提升效率,而可以盡可能地通過上文提到的Journaling方式來提高寫入吞吐量。當然,其讀取效率會稍遜于B+樹。
聲音 | 林草局:要積極探索區塊鏈等技術 為業務管理提供智能化服務:林草局發布《國家林業和草原局關于促進林業和草原人工智能發展的指導》。其中提到,要積極探索基于區塊鏈、大數據、人工智能等技術,在生態管理工作領域、生態公共服務領域、生態決策服務領域,為業務管理、輿情分析和領導決策提供智能化服務。[2019/11/22]
LSM-Tree數據結構:抽絲剝繭
圖2展示了LSM-Tree的理論模型(a)和一種實現方式(b)。LSM-Tree是一種層級的數據結構,包含一層空間占用較小的內存結構以及多層磁盤結構,每一層磁盤結構的空間上限呈指數增長,如在LevelDB中該系數默認為10。
Figure2LSM與其LevelDB實現
對于LSM-Tree的數據插入或更新,首先會被緩存在內存中,這部分數據往往由一顆排序樹進行組織。
當緩存達到預設上限,則會將內存中的數據以有序的方式寫入磁盤,我們稱這樣的有序列為一個SortedRun,簡稱為Run。
隨著寫入操作的不斷進行,L0層會堆積越來越多的Run,且顯然不同的Run之前可能存在重疊部分,此時進行某一條數據的查詢將無法準確判斷該數據存在于哪個Run中,因此最壞情況下需要進行等同于L0層Run數量的I/O。
為了解決該問題,當某一層的Run數目或大小到達某一閾值后,LSM-Tree會進行后臺的歸并排序,并將排序結果輸出至下一層,我們將一次歸并排序稱為Compaction。如同B+樹的分裂一樣,Compaction是LSM-Tree維持相對穩定讀寫效率的核心機制,我們將會在下文詳細介紹兩種不同的Compaction策略。
聲音 | 博思軟件:正積極探索區塊鏈技術 公司業務不涉及數字貨幣:博思軟件(SZ300525)在互動平臺回復投資者提問表示,公司始終堅持技術為業務服務的理念,積極研究并探索在合適的業務場景應用區塊鏈技術,公司業務不涉及數字貨幣。[2019/10/9]
另外值得一提的是,無論是從內存到磁盤的寫入,還是磁盤中不斷進行的Compaction,都是對磁盤的順序I/O,這就是LSM擁有更高寫入吞吐量的原因。
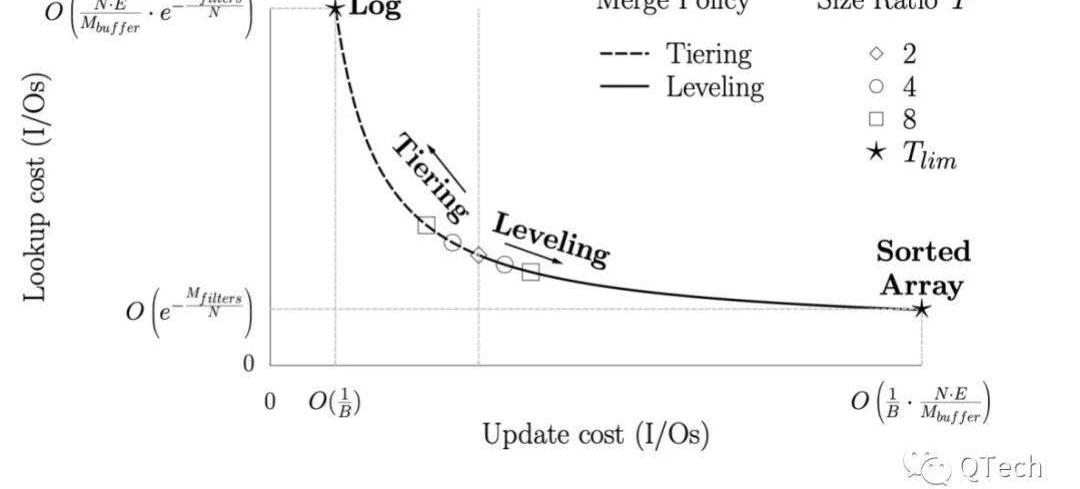
Levelingvs.Tiering:一讀一寫,不分伯仲
LSM-Tree的Compaction策略可以分為Leveling和Tiering兩種,前者被LevelDB,RocksDB等采用,后者被Cassandra等采用,稱采用Leveling策略的的LSM-Tree為LeveledLSM-Tree,采用Tiering的LSM-Tree為TieredLSM-Tree,如圖3所示。
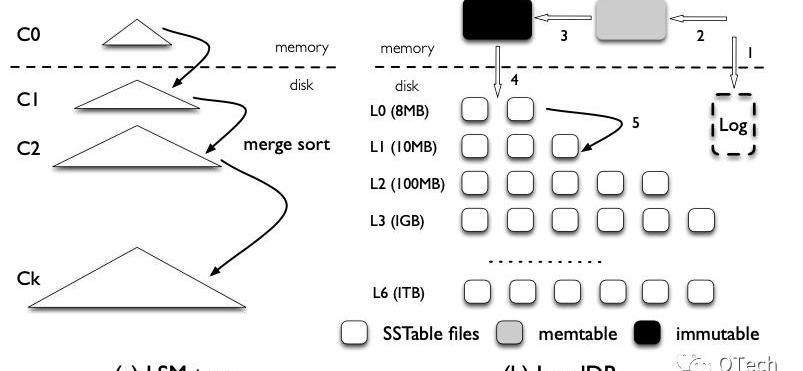
Figure3兩種Compaction策略對比
▲Leveling
簡而言之,Tiering是寫友好型的策略,而Leveling是讀友好型的策略。在Leveling中,除了L0的每一層最多只能有一個Run,如圖3右側所示,當在L0插入13時,觸發了L0層的Compaction,此時會對Run-L0與下層Run-L1進行一次歸并排序,歸并結果寫入L1,此時又觸發了L1的Compaction,此時會對Run-L1與下層Run-L2進行歸并排序,歸并結果寫入L2。
動態 | 鋼鐵電商積微物聯引入區塊鏈等新技術 打造“鋼鐵大腦”:據經濟參考報消息,西南最大鋼鐵電商、全國最大物流綜合體積微物聯。面向全國布局線下業務,構建積微循環、積微云采等線下平臺,牽手清華大學、電子科大、阿里、浙大網新等知名高校和企業,引入大數據、人工智能、區塊鏈等新技術,打造“鋼鐵大腦”,推進傳統制造業的兩化深度融合,形成了以積微物聯為核心的工業互聯網生態圈,趟出了一條發展新經濟、新業態、新模式的新路子。[2018/11/5]
▲Tiering
反觀Tiering在進行Compaction時并不會主動與下層的Run進行歸并,而只會對發生Compaction的那一層的若干個Run進行歸并排序,這也是Tiering的一層會存在多個Run的原因。
▲對比分析
相比而言,Leveling方式進行得更加貪婪,進行了更多的磁盤I/O,維持了更高的讀效率,而Tiering則相正好反。
本節我們將對LSM-Tree的設計空間進行更加形式化的分析。
LSM層數

布隆過濾器
LSM-Tree應用布隆過濾器來加速查找,LSM-Tree為每個Run設置一個布隆過濾器,在通過I/O查詢某個Run之前,首先通過布隆過濾器判斷待查詢的數據是否存在于該Run,若布隆過濾器返回Negative,則可斷言不存在,直接跳到下個Run進行查詢,從而節省了一次I/O;而若布隆過濾器返回Positive,則仍不能確定數據是否存在,需要消耗一次I/O去查詢該Run,若成功查詢到數據,則終止查找,否則繼續查找下一個Run,我們稱后者為假陽現象,布隆過濾器的過高的假陽率會嚴重影響讀性能,使得花費在布隆過濾器上的內存形同虛設。限于篇幅本文不對布隆過濾器做更多的介紹,直接給出FPR的計算公式,為公式2.
佛山禪城利用區塊鏈技術 進行青少年眼健康管理模式試點:5月初起,禪城將選取10所小學和3所中學,推進“區塊鏈+視力”,利用兒童青少年眼健康綜合平臺,開展兒童青少年眼健康管理模式試點。這是禪城利用區塊鏈技術推進的又一項公共服務改革。傳統的視力檢查結果大部分是手寫,容易丟失,且每次檢查的結果是孤立的。而“區塊鏈+視力”,通過智能篩查設備,20秒左右完成雙眼屈光度檢查,檢查結果能自動上傳至數據平臺,通過長期的視力篩查跟蹤,匯總成大數據。[2018/4/20]
其中是為布隆過濾器設置的內存大小,為每個Run中的數據總數。讀寫I/O
考慮讀寫操作的最壞場景,對于讀操作,認為其最壞場景是空讀,即遍歷每一層的每個Run,最后發現所讀數據并不存在;對于寫操作,認為其最壞場景是一條數據的寫入會導致每一層發生一次Compaction。
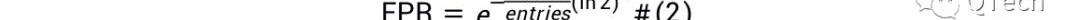
核心理念:基于場景化的設計空間
基于以上分析,我們可以得出如圖4所示的LSM-Tree可基于場景化的設計空間。
簡而言之,LSM-Tree的設計空間是:在極端優化寫的日志方式與極端優化讀的有序列表方式之間的折中,折中策略取決于場景,折中方式可以對以下參數進行調整:

當Level間放大比例時,兩種Compaction策略的讀寫開銷是一致的,而隨著T的不斷增加,Leveling和Tiering方式的讀開銷分別提高/減少。
當T達到上限時,前者只有一層,且一層中只有一個Run,因此其讀開銷到達最低,即最壞情況下只需要一次I/O,而每次寫入都會觸發整層的Compaction;
而對于后者當T到達上限時,也只有一層,但是一層中存在:

因此讀開銷達到最高,而寫操作不會觸發任何的Compaction,因此寫開銷達到最低。
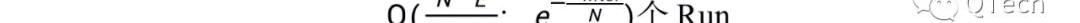
Figure4LSM由日志到有序列的設計空間
事實上,基于圖4及上文的分析可以進行對LSM-Tree的性能進一步的優化,如文獻對每一層的布隆過濾器大小進行動態調整,以充分優化內存分配并降低FPR來提高讀取效率;文獻提出“LazyLeveling”方式來自適應的選擇Compaction策略等。
限于篇幅本文不再對這些優化思路進行介紹,感興趣的讀者可以自行查閱文獻。
小結
LSM-Tree提供了相當高的寫性能、空間利用率以及非常靈活的配置項可供調優,其仍然是適合區塊鏈應用的最佳存儲引擎之一。
本文對LSM-Tree從設計思想、數據結構、兩種Compaction策略幾個角度進行了由淺入深地介紹,限于篇幅,基于本文之上的對LSM-Tree的調優方法將會在后續文章中介紹。
作者簡介葉晨宇來自趣鏈科技基礎平臺部,區塊鏈賬本存儲研究小組
參考文獻
.O’NeilP,ChengE,GawlickD,etal.Thelog-structuredmerge-tree(LSM-tree).ActaInformatica,1996,33(4):351-385.
.JacobsA.Thepathologiesofbigdata.CommunicationsoftheACM,2009,52(8):36-44.
.LuL,PillaiTS,GopalakrishnanH,etal.Wisckey:Separatingkeysfromvaluesinssd-consciousstorage.ACMTransactionsonStorage(TOS),2017,13(1):1-28.
.DayanN,AthanassoulisM,IdreosS.Monkey:Optimalnavigablekey-valuestore//Proceedingsofthe2017ACMInternationalConferenceonManagementofData.2017:79-94.
.DayanN,IdreosS.Dostoevsky:Betterspace-timetrade-offsforLSM-treebasedkey-valuestoresviaadaptiveremovalofsuperfluousmerging//Proceedingsofthe2018InternationalConferenceonManagementofData.2018:505-520.
.LuoC,CareyMJ.LSM-basedstoragetechniques:asurvey.TheVLDBJournal,2020,29(1):393-418.
以太坊上的代幣是一系列所有權:從藝術品到穩定幣,再到整個去中心化協議。這些代幣有助于Swap互換以及借貸,并為衍生品市場奠定了基礎.
1900/1/1 0:00:00最近,在新加坡和香港都有機構率先獲得所在地頒發的數字資產交易牌照。依據這些牌照,它們可以向機構和高凈值用戶提供加密數字貨幣的交易服務,為用戶的數字資產提供托管服務以及開展STO業務.
1900/1/1 0:00:00自2016年以來,每年我都會對下一年行業的發展做出預測。如果你關注年復一年的增量變化,你就會意識到一切都有聯系,而你可以預見一些令人興奮的結果.
1900/1/1 0:00:00北京時間12月16日晚上21:40,在萬眾期待之中,比特幣價格終于沖破了20000美元大關,這標志著“她”達到了一個新的高度,同時也預示著新一輪加密貨幣熱潮正在蔓延.
1900/1/1 0:00:00要點: 美國財政部下屬金融犯罪執法網絡已發布了針對未托管加密貨幣錢包的擬議規則;這些規則將要求貨幣服務企業向FinCEN報告此類錢包的某些加密交易;FinCEN稱這些規則旨在打擊非法活動.
1900/1/1 0:00:00123家現貨和衍生品加密貨幣交易所的融資史。原文|TheBlockJohnDantoni?編譯|PANewsTheBlockResearch分析了123家加密貨幣現貨和衍生品交易所,這些交易所一.
1900/1/1 0:00:00


